 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacticGen: Grounding Adaptable and Scalable Generation of Football Tactics
Apr 20, 2026Success in association football relies on both individual skill and coordinated tactics. While recent advancements in spatio-temporal data and deep learning have enabled predictive analyses like trajectory forecasting, the development of tactical design remains limited. Bridging this gap is essential, as prediction reveals what is likely to occur, whereas tactic generation determines what should occur to achieve strategic objectives. In this work, we present TacticGen, a generative model for adaptable and scalable tactic generation. TacticGen formulates tactics as sequences of multi-agent movements and interactions conditioned on the game context. It employs a multi-agent diffusion transformer with agent-wise self-attention and context-aware cross-attention to capture cooperative and competitive dynamics among players and the ball. Trained with over 3.3 million events and 100 million tracking frames from top-tier leagues, TacticGen achieves state-of-the-art precision in predicting player trajectories. Building on it, TacticGen enables adaptable tactic generation tailored to diverse inference-time objectives through classifier guidance mechanism, specified via rules, natural language, or neural models. Its modeling performance is also inherently scalable. A case study with football experts confirms that TacticGen generates realistic, strategically valuable tactics, demonstrating its practical utility for tactical planning in professional football. The project page is available at: https://shengxu.net/TacticGen/.
CREST: Constraint-Release Execution for Multi-Robot Warehouse Shelf Rearrangement
Mar 27, 2026Double-Deck Multi-Agent Pickup and Delivery (DD-MAPD) models the multi-robot shelf rearrangement problem in automated warehouses. MAPF-DECOMP is a recent framework that first computes collision-free shelf trajectories with a MAPF solver and then assigns agents to execute them. While efficient, it enforces strict trajectory dependencies, often leading to poor execution quality due to idle agents and unnecessary shelf switching. We introduce CREST, a new execution framework that achieves more continuous shelf carrying by proactively releasing trajectory constraints during execution. Experiments on diverse warehouse layouts show that CREST consistently outperforms MAPF-DECOMP, reducing metrics related to agent travel, makespan, and shelf switching by up to 40.5\%, 33.3\%, and 44.4\%, respectively, with even greater benefits under lift/place overhead. These results underscore the importance of execution-aware constraint release for scalable warehouse rearrangement. Code and data are available at https://github.com/ChristinaTan0704/CREST.
Boosting CVaR Policy Optimization with Quantile Gradients
Jan 29, 2026Optimizing Conditional Value-at-risk (CVaR) using policy gradient (a.k.a CVaR-PG) faces significant challenges of sample inefficiency. This inefficiency stems from the fact that it focuses on tail-end performance and overlooks many sampled trajectories. We address this problem by augmenting CVaR with an expected quantile term. Quantile optimization admits a dynamic programming formulation that leverages all sampled data, thus improves sample efficiency. This does not alter the CVaR objective since CVaR corresponds to the expectation of quantile over the tail. Empirical results in domains with verifiable risk-averse behavior show that our algorithm within the Markovian policy class substantially improves upon CVaR-PG and consistently outperforms other existing methods.
Measures of Variability for Risk-averse Policy Gradient
Apr 15, 2025Risk-averse reinforcement learning (RARL) is critical for decision-making under uncertainty, which is especially valuable in high-stake applications. However, most existing works focus on risk measures, e.g., conditional value-at-risk (CVaR), while measures of variability remain underexplored. In this paper, we comprehensively study nine common measures of variability, namely Variance, Gini Deviation, Mean Deviation, Mean-Median Deviation, Standard Deviation, Inter-Quantile Range, CVaR Deviation, Semi_Variance, and Semi_Standard Deviation. Among them, four metrics have not been previously studied in RARL. We derive policy gradient formulas for these unstudied metrics, improve gradient estimation for Gini Deviation, analyze their gradient properties, and incorporate them with the REINFORCE and PPO frameworks to penalize the dispersion of returns. Our empirical study reveals that variance-based metrics lead to unstable policy updates. In contrast, CVaR Deviation and Gini Deviation show consistent performance across different randomness and evaluation domains, achieving high returns while effectively learning risk-averse policies. Mean Deviation and Semi_Standard Deviation are also competitive across different scenarios. This work provides a comprehensive overview of variability measures in RARL, offering practical insights for risk-aware decision-making and guiding future research on risk metrics and RARL algorithms.
Benchmarking Large Neighborhood Search for Multi-Agent Path Finding
Jul 12, 2024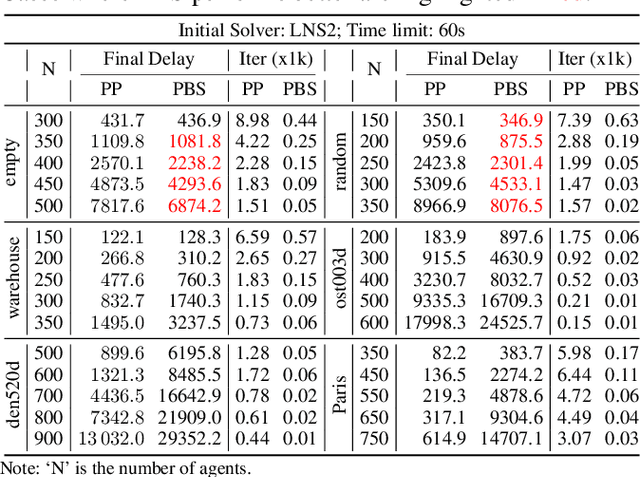
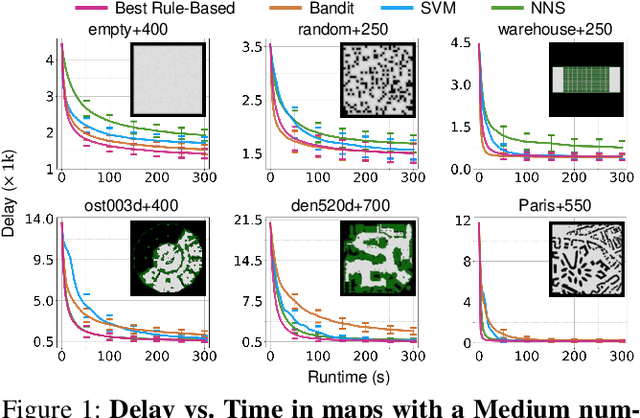

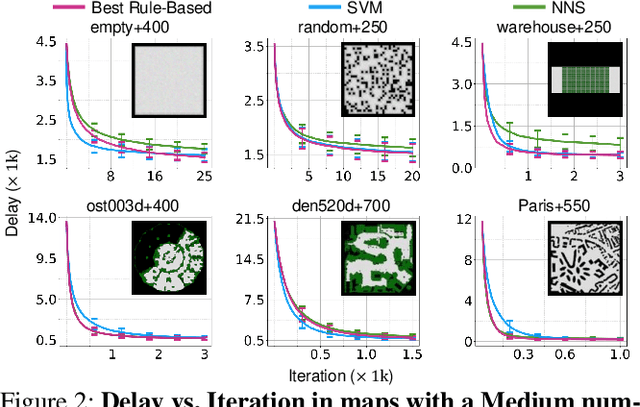
Multi-Agent Path Finding (MAPF) aims to arrange collision-free goal-reaching paths for a group of agents. Anytime MAPF solvers based on large neighborhood search (LNS) have gained prominence recently due to their flexibility and scalability. Neighborhood selection strategy is crucial to the success of MAPF-LNS and a flurry of methods have been proposed. However, several pitfalls exist and hinder a comprehensive evaluation of these new methods, which mainly include: 1) Lower than actual or incorrect baseline performance; 2) Lack of a unified evaluation setting and criterion; 3) Lack of a codebase or executable model for supervised learning methods. To overcome these challenges, we conduct a fair comparison across prominent methods on the same benchmark and hyperparameter search settings. Additionally, we propose a simple neighborhood selection strategy which marks a clear advancement in terms of runtime efficiency in large maps with large number of agents. Our benchmarking evaluation promotes new challenges for existing learning based methods and presents opportunities for future research when machine learning is integrated with MAPF-LNS. Code and data are available at https://github.com/ChristinaTan0704/mapf-lns-benchmark.
A Simple Mixture Policy Parameterization for Improving Sample Efficiency of CVaR Optimization
Mar 20, 2024



Reinforcement learning algorithms utilizing policy gradients (PG) to optimize Conditional Value at Risk (CVaR) face significant challenges with sample inefficiency, hindering their practical applications. This inefficiency stems from two main facts: a focus on tail-end performance that overlooks many sampled trajectories, and the potential of gradient vanishing when the lower tail of the return distribution is overly flat. To address these challenges, we propose a simple mixture policy parameterization. This method integrates a risk-neutral policy with an adjustable policy to form a risk-averse policy. By employing this strategy, all collected trajectories can be utilized for policy updating, and the issue of vanishing gradients is counteracted by stimulating higher returns through the risk-neutral component, thus lifting the tail and preventing flatness. Our empirical study reveals that this mixture parameterization is uniquely effective across a variety of benchmark domains. Specifically, it excels in identifying risk-averse CVaR policies in some Mujoco environments where the traditional CVaR-PG fails to learn a reasonable policy.
An Alternative to Variance: Gini Deviation for Risk-averse Policy Gradient
Aug 09, 2023


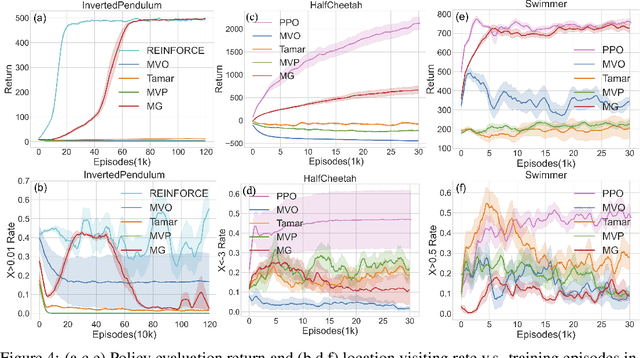
Restricting the variance of a policy's return is a popular choice in risk-averse Reinforcement Learning (RL) due to its clear mathematical definition and easy interpretability. Traditional methods directly restrict the total return variance. Recent methods restrict the per-step reward variance as a proxy. We thoroughly examine the limitations of these variance-based methods, such as sensitivity to numerical scale and hindering of policy learning, and propose to use an alternative risk measure, Gini deviation, as a substitute. We study various properties of this new risk measure and derive a policy gradient algorithm to minimize it. Empirical evaluation in domains where risk-aversion can be clearly defined, shows that our algorithm can mitigate the limitations of variance-based risk measures and achieves high return with low risk in terms of variance and Gini deviation when others fail to learn a reasonable policy.
Benchmarking Constraint Inference in Inverse Reinforcement Learning
Jun 20, 2022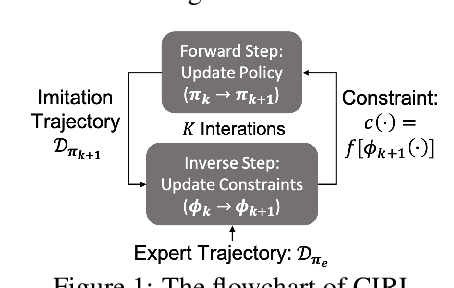
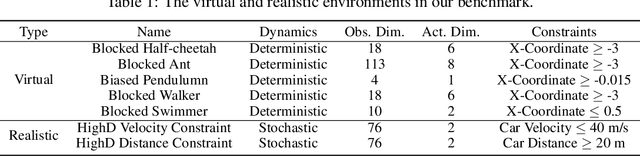
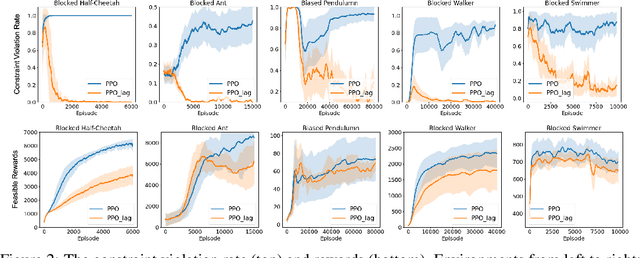

When deploying Reinforcement Learning (RL) agents into a physical system, we must ensure that these agents are well aware of the underlying constraints. In many real-world problems, however, the constraints followed by expert agents (e.g., humans) are often hard to specify mathematically and unknown to the RL agents. To tackle these issues, Constraint Inverse Reinforcement Learning (CIRL) considers the formalism of Constrained Markov Decision Processes (CMDPs) and estimates constraints from expert demonstrations by learning a constraint function. As an emerging research topic, CIRL does not have common benchmarks, and previous works tested their algorithms with hand-crafted environments (e.g., grid worlds). In this paper, we construct a CIRL benchmark in the context of two major application domains: robot control and autonomous driving. We design relevant constraints for each environment and empirically study the ability of different algorithms to recover those constraints based on expert trajectories that respect those constraints. To handle stochastic dynamics, we propose a variational approach that infers constraint distributions, and we demonstrate its performance by comparing it with other CIRL baselines on our benchmark. The benchmark, including the information for reproducing the performance of CIRL algorithms, is publicly available at https://github.com/Guiliang/CIRL-benchmarks-public
Learning Selective Communication for Multi-Agent Path Finding
Sep 12, 2021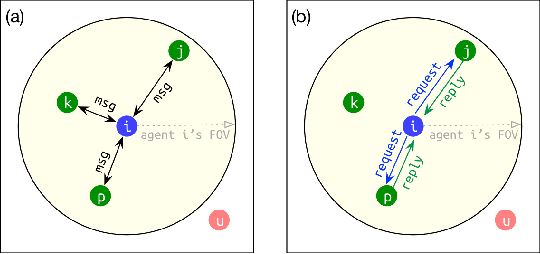
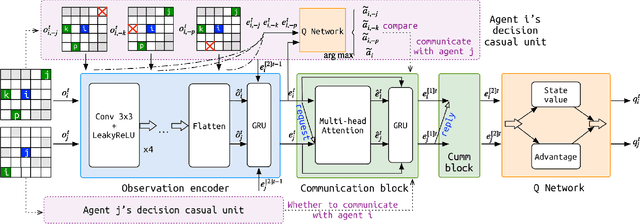
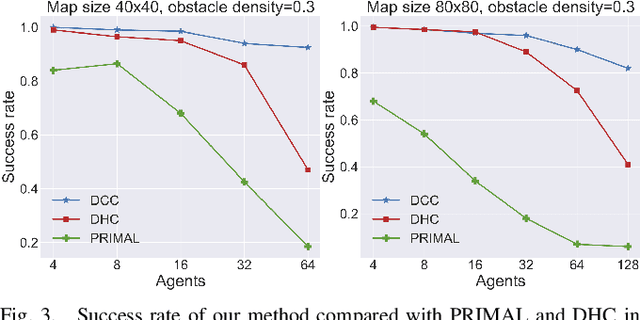
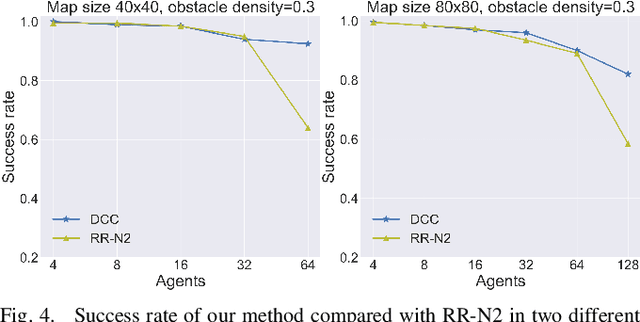
Learning communication via deep reinforcement learning (RL) or imitation learning (IL) has recently been shown to be an effective way to solve Multi-Agent Path Finding (MAPF). However, existing communication based MAPF solvers focus on broadcast communication, where an agent broadcasts its message to all other or predefined agents. It is not only impractical but also leads to redundant information that could even impair the multi-agent cooperation. A succinct communication scheme should learn which information is relevant and influential to each agent's decision making process. To address this problem, we consider a request-reply scenario and propose Decision Causal Communication (DCC), a simple yet efficient model to enable agents to select neighbors to conduct communication during both training and execution. Specifically, a neighbor is determined as relevant and influential only when the presence of this neighbor causes the decision adjustment on the central agent. This judgment is learned only based on agent's local observation and thus suitable for decentralized execution to handle large scale problems. Empirical evaluation in obstacle-rich environment indicates the high success rate with low communication overhead of our method.
Distributed Heuristic Multi-Agent Path Finding with Communication
Jun 21, 2021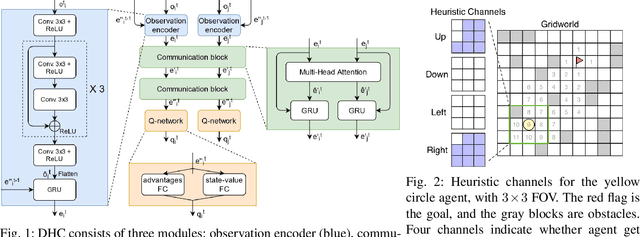
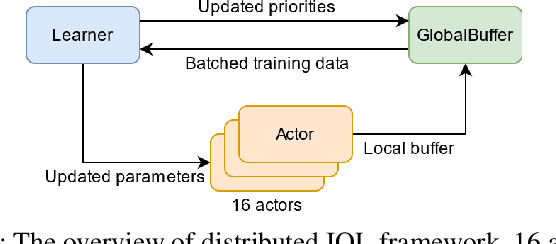
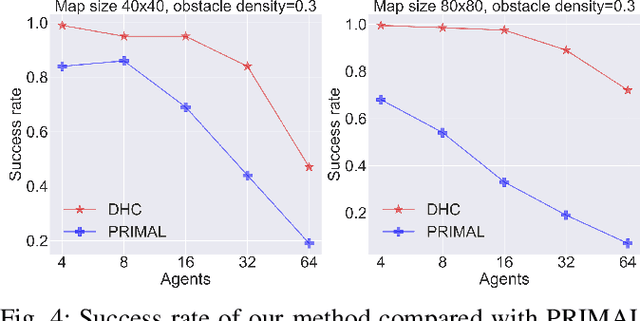

Multi-Agent Path Finding (MAPF) is essential to large-scale robotic systems. Recent methods have applied reinforcement learning (RL) to learn decentralized polices in partially observable environments. A fundamental challenge of obtaining collision-free policy is that agents need to learn cooperation to handle congested situations. This paper combines communication with deep Q-learning to provide a novel learning based method for MAPF, where agents achieve cooperation via graph convolution. To guide RL algorithm on long-horizon goal-oriented tasks, we embed the potential choices of shortest paths from single source as heuristic guidance instead of using a specific path as in most existing works. Our method treats each agent independently and trains the model from a single agent's perspective. The final trained policy is applied to each agent for decentralized execution. The whole system is distributed during training and is trained under a curriculum learning strategy. Empirical evaluation in obstacle-rich environment indicates the high success rate with low average step of our method.