 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPS: Context-Aware Priority Sampling for Enhanced Imitation Learning in Autonomous Driving
Mar 03, 2025In this paper, we introduce CAPS (Context-Aware Priority Sampling), a novel method designed to enhance data efficiency in learning-based autonomous driving systems. CAPS addresses the challenge of imbalanced training datasets in imitation learning by leveraging Vector Quantized Variational Autoencoders (VQ-VAEs). The use of VQ-VAE provides a structured and interpretable data representation, which helps reveal meaningful patterns in the data. These patterns are used to group the data into clusters, with each sample being assigned a cluster ID. The cluster IDs are then used to re-balance the dataset, ensuring that rare yet valuable samples receive higher priority during training. By ensuring a more diverse and informative training set, CAPS improves the generalization of the trained planner across a wide range of driving scenarios. We evaluate our method through closed-loop simulations in the CARLA environment. The results on Bench2Drive scenarios demonstrate that our framework outperforms state-of-the-art methods, leading to notable improvements in model performance.
Learning Soft Driving Constraints from Vectorized Scene Embeddings while Imitating Expert Trajectories
Dec 07, 2024


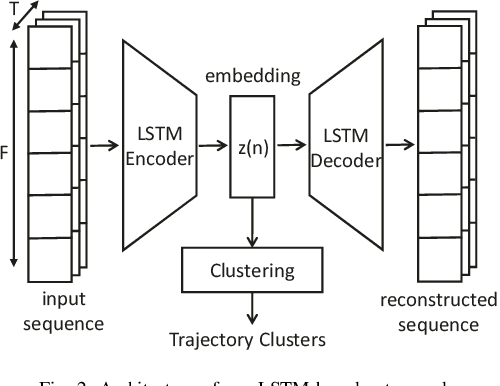
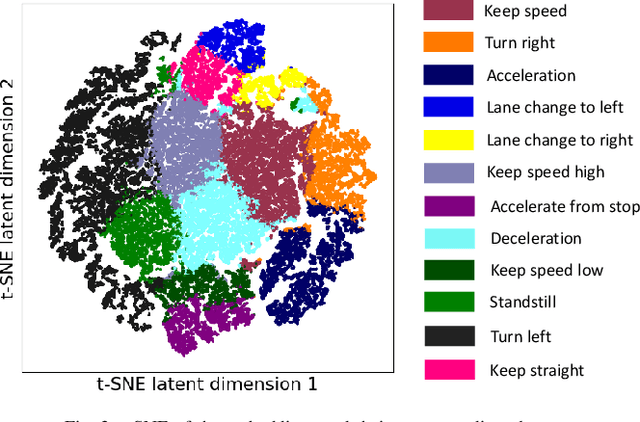
The primary goal of motion planning is to generate safe and efficient trajectories for vehicles. Traditionally, motion planning models are trained using imitation learning to mimic the behavior of human experts. However, these models often lack interpretability and fail to provide clear justifications for their decisions. We propose a method that integrates constraint learning into imitation learning by extracting driving constraints from expert trajectories. Our approach utilizes vectorized scene embeddings that capture critical spatial and temporal features, enabling the model to identify and generalize constraints across various driving scenarios. We formulate the constraint learning problem using a maximum entropy model, which scores the motion planner's trajectories based on their similarity to the expert trajectory. By separating the scoring process into distinct reward and constraint streams, we improve both the interpretability of the planner's behavior and its attention to relevant scene components. Unlike existing constraint learning methods that rely on simulators and are typically embedded in reinforcement learning (RL) or inverse reinforcement learning (IRL) frameworks, our method operates without simulators, making it applicable to a wider range of datasets and real-world scenarios. Experimental results on the InD and TrafficJams datasets demonstrate that incorporating driving constraints enhances model interpretability and improves closed-loop performance.
Confidence Aware Inverse Constrained Reinforcement Learning
Jun 24, 2024



In coming up with solutions to real-world problems, humans implicitly adhere to constraints that are too numerous and complex to be specified completely. However, reinforcement learning (RL) agents need these constraints to learn the correct optimal policy in these settings. The field of Inverse Constraint Reinforcement Learning (ICRL) deals with this problem and provides algorithms that aim to estimate the constraints from expert demonstrations collected offline. Practitioners prefer to know a measure of confidence in the estimated constraints, before deciding to use these constraints, which allows them to only use the constraints that satisfy a desired level of confidence. However, prior works do not allow users to provide the desired level of confidence for the inferred constraints. This work provides a principled ICRL method that can take a confidence level with a set of expert demonstrations and outputs a constraint that is at least as constraining as the true underlying constraint with the desired level of confidence. Further, unlike previous methods, this method allows a user to know if the number of expert trajectories is insufficient to learn a constraint with a desired level of confidence, and therefore collect more expert trajectories as required to simultaneously learn constraints with the desired level of confidence and a policy that achieves the desired level of performance.
Vectorized Representation Dreamer (VRD): Dreaming-Assisted Multi-Agent Motion-Forecasting
Jun 20, 2024



For an autonomous vehicle to plan a path in its environment, it must be able to accurately forecast the trajectory of all dynamic objects in its proximity. While many traditional methods encode observations in the scene to solve this problem, there are few approaches that consider the effect of the ego vehicle's behavior on the future state of the world. In this paper, we introduce VRD, a vectorized world model-inspired approach to the multi-agent motion forecasting problem. Our method combines a traditional open-loop training regime with a novel dreamed closed-loop training pipeline that leverages a kinematic reconstruction task to imagine the trajectory of all agents, conditioned on the action of the ego vehicle. Quantitative and qualitative experiments are conducted on the Argoverse 2 multi-world forecasting evaluation dataset and the intersection drone (inD) dataset to demonstrate the performance of our proposed model. Our model achieves state-of-the-art performance on the single prediction miss rate metric on the Argoverse 2 dataset and performs on par with the leading models for the single prediction displacement metrics.
Learning from Mistakes: a Weakly-supervised Method for Mitigating the Distribution Shift in Autonomous Vehicle Planning
Jun 03, 2024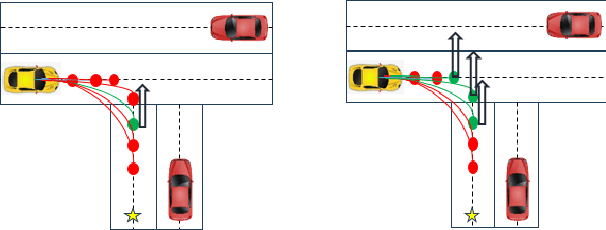



The planning problem constitutes a fundamental aspect of the autonomous driving framework. Recent strides in representation learning have empowered vehicles to comprehend their surrounding environments, thereby facilitating the integration of learning-based planning strategies. Among these approaches, Imitation Learning stands out due to its notable training efficiency. However, traditional Imitation Learning methodologies encounter challenges associated with the co-variate shift phenomenon. We propose Learn from Mistakes (LfM) as a remedy to address this issue. The essence of LfM lies in deploying a pre-trained planner across diverse scenarios. Instances where the planner deviates from its immediate objectives, such as maintaining a safe distance from obstacles or adhering to traffic rules, are flagged as mistakes. The environments corresponding to these mistakes are categorized as out-of-distribution states and compiled into a new dataset termed closed-loop mistakes dataset. Notably, the absence of expert annotations for the closed-loop data precludes the applicability of standard imitation learning approaches. To facilitate learning from the closed-loop mistakes, we introduce Validity Learning, a weakly supervised method, which aims to discern valid trajectories within the current environmental context. Experimental evaluations conducted on the InD and Nuplan datasets reveal substantial enhancements in closed-loop metrics such as Progress and Collision Rate, underscoring the effectiveness of the proposed methodology.
Augmenting Safety-Critical Driving Scenarios while Preserving Similarity to Expert Trajectories
Apr 20, 2024
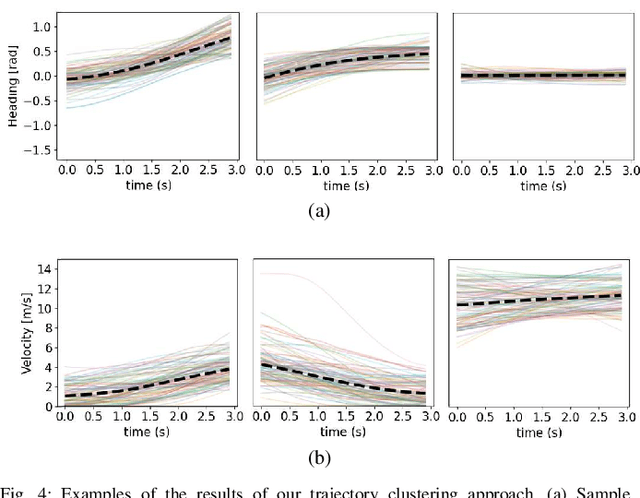
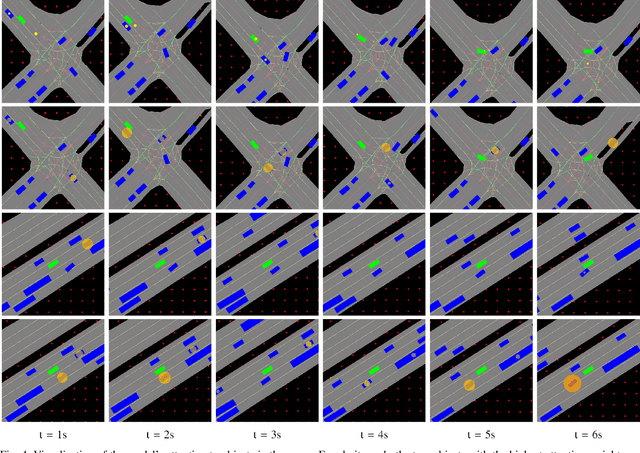
Trajectory augmentation serves as a means to mitigate distributional shift in imitation learning. However, imitating trajectories that inadequately represent the original expert data can result in undesirable behaviors, particularly in safety-critical scenarios. We propose a trajectory augmentation method designed to maintain similarity with expert trajectory data. To accomplish this, we first cluster trajectories to identify minority yet safety-critical groups. Then, we combine the trajectories within the same cluster through geometrical transformation to create new trajectories. These trajectories are then added to the training dataset, provided that they meet our specified safety-related criteria. Our experiments exhibit that training an imitation learning model using these augmented trajectories can significantly improve closed-loop performance.
NeurIPS 2022 Competition: Driving SMARTS
Nov 14, 2022

Driving SMARTS is a regular competition designed to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition supports methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, trained on a combination of naturalistic AD data and open-source simulation platform SMARTS. The two-track structure allows focusing on different aspects of the distribution shift. Track 1 is open to any method and will give ML researchers with different backgrounds an opportunity to solve a real-world autonomous driving challenge. Track 2 is designed for strictly offline learning methods. Therefore, direct comparisons can be made between different methods with the aim to identify new promising research directions. The proposed setup consists of 1) realistic traffic generated using real-world data and micro simulators to ensure fidelity of the scenarios, 2) framework accommodating diverse methods for solving the problem, and 3) baseline method. As such it provides a unique opportunity for the principled investigation into various aspects of autonomous vehicle deployment.
Benchmarking Constraint Inference in Inverse Reinforcement Learning
Jun 20, 2022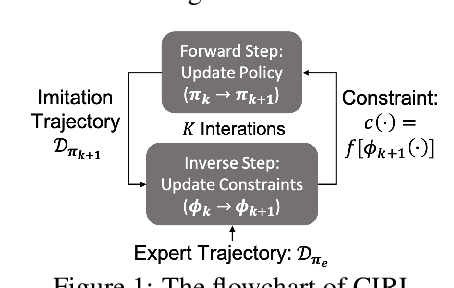
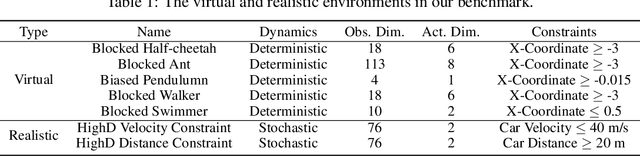
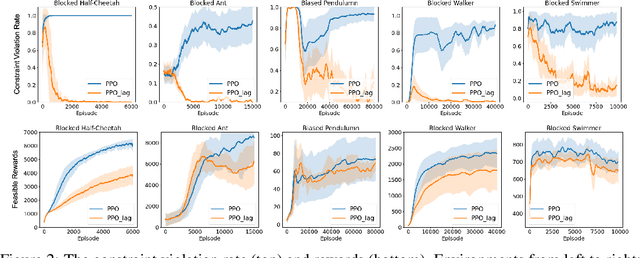

When deploying Reinforcement Learning (RL) agents into a physical system, we must ensure that these agents are well aware of the underlying constraints. In many real-world problems, however, the constraints followed by expert agents (e.g., humans) are often hard to specify mathematically and unknown to the RL agents. To tackle these issues, Constraint Inverse Reinforcement Learning (CIRL) considers the formalism of Constrained Markov Decision Processes (CMDPs) and estimates constraints from expert demonstrations by learning a constraint function. As an emerging research topic, CIRL does not have common benchmarks, and previous works tested their algorithms with hand-crafted environments (e.g., grid worlds). In this paper, we construct a CIRL benchmark in the context of two major application domains: robot control and autonomous driving. We design relevant constraints for each environment and empirically study the ability of different algorithms to recover those constraints based on expert trajectories that respect those constraints. To handle stochastic dynamics, we propose a variational approach that infers constraint distributions, and we demonstrate its performance by comparing it with other CIRL baselines on our benchmark. The benchmark, including the information for reproducing the performance of CIRL algorithms, is publicly available at https://github.com/Guiliang/CIRL-benchmarks-public
Learning Soft Constraints From Constrained Expert Demonstrations
Jun 02, 2022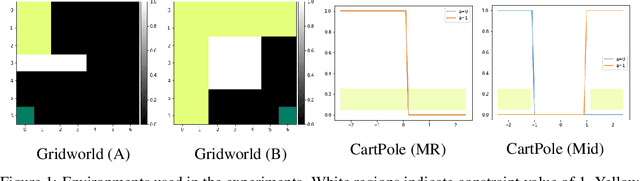
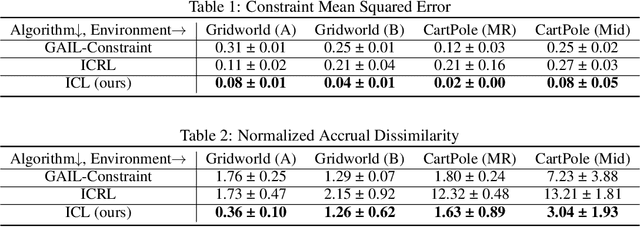

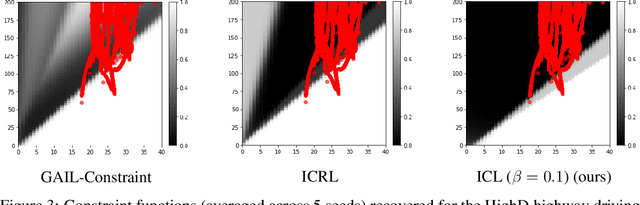
Inverse reinforcement learning (IRL) methods assume that the expert data is generated by an agent optimizing some reward function. However, in many settings, the agent may optimize a reward function subject to some constraints, where the constraints induce behaviors that may be otherwise difficult to express with just a reward function. We consider the setting where the reward function is given, and the constraints are unknown, and propose a method that is able to recover these constraints satisfactorily from the expert data. While previous work has focused on recovering hard constraints, our method can recover cumulative soft constraints that the agent satisfies on average per episode. In IRL fashion, our method solves this problem by adjusting the constraint function iteratively through a constrained optimization procedure, until the agent behavior matches the expert behavior. Despite the simplicity of the formulation, our method is able to obtain good results. We demonstrate our approach on synthetic environments and real world highway driving data.
Multi-lane Cruising Using Hierarchical Planning and Reinforcement Learning
Oct 01, 2021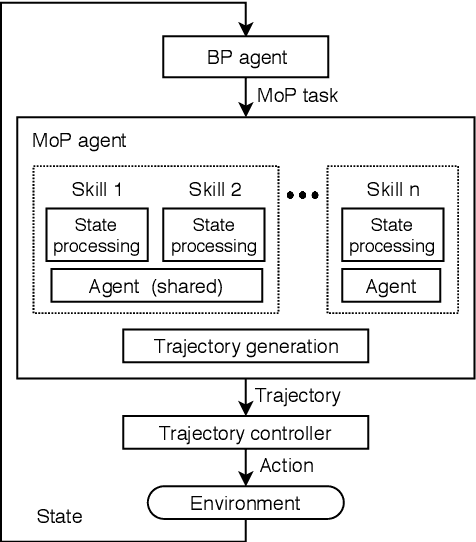
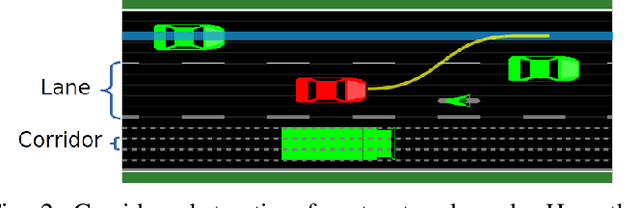
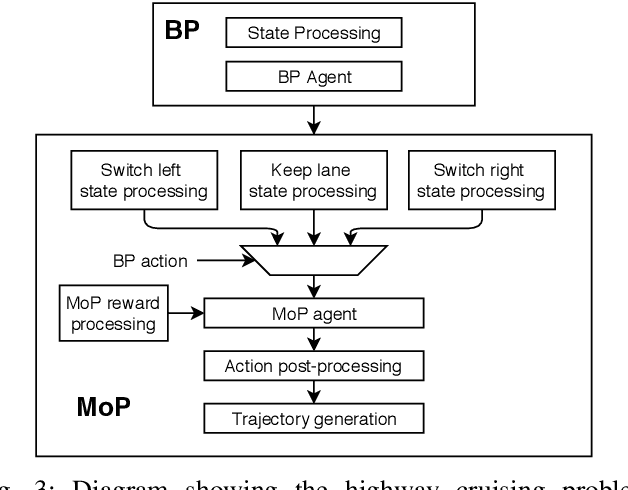
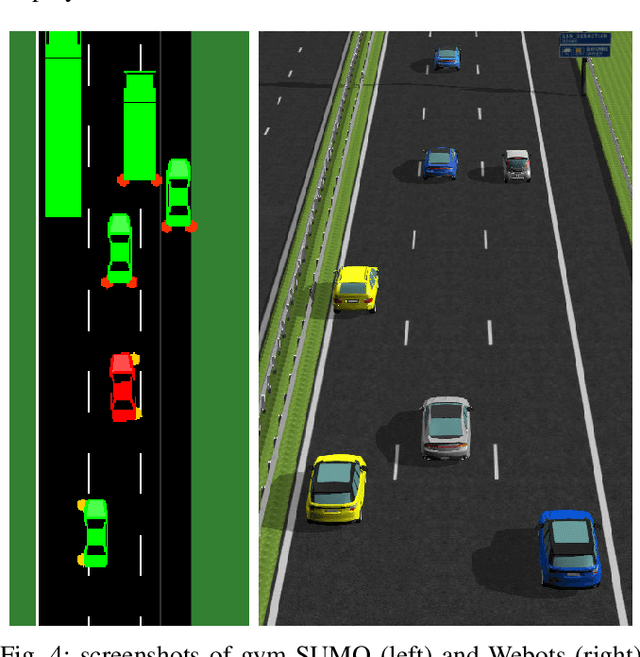
Competent multi-lane cruising requires using lane changes and within-lane maneuvers to achieve good speed and maintain safety. This paper proposes a design for autonomous multi-lane cruising by combining a hierarchical reinforcement learning framework with a novel state-action space abstraction. While the proposed solution follows the classical hierarchy of behavior decision, motion planning and control, it introduces a key intermediate abstraction within the motion planner to discretize the state-action space according to high level behavioral decisions. We argue that this design allows principled modular extension of motion planning, in contrast to using either monolithic behavior cloning or a large set of hand-written rules. Moreover, we demonstrate that our state-action space abstraction allows transferring of the trained models without retraining from a simulated environment with virtually no dynamics to one with significantly more realistic dynamics. Together, these results suggest that our proposed hierarchical architecture is a promising way to allow reinforcement learning to be applied to complex multi-lane cruising in the real world.