 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Constraint Generation for Motion Planning in Dynamic Environments
Oct 27, 2021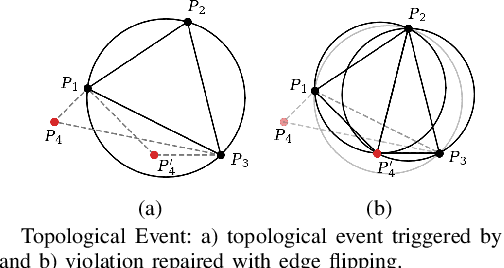
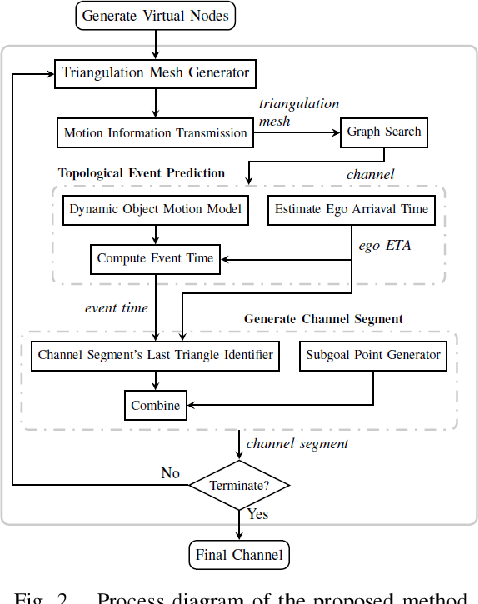
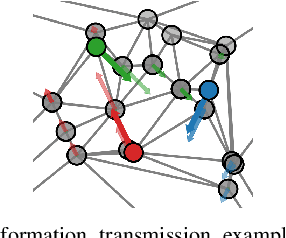
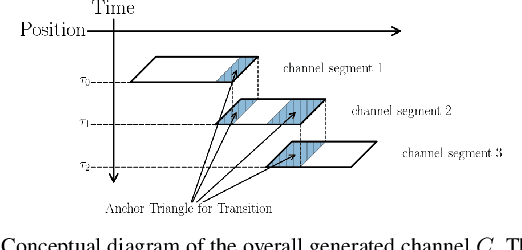
This paper presents a novel method to generate spatial constraints for motion planning in dynamic environments. Motion planning methods for autonomous driving and mobile robots typically need to rely on the spatial constraints imposed by a map-based global planner to generate a collision-free trajectory. These methods may fail without an offline map or where the map is invalid due to dynamic changes in the environment such as road obstruction, construction, and traffic congestion. To address this problem, triangulation-based methods can be used to obtain a spatial constraint. However, the existing methods fall short when dealing with dynamic environments and may lead the motion planner to an unrecoverable state. In this paper, we propose a new method to generate a sequence of channels across different triangulation mesh topologies to serve as the spatial constraints. This can be applied to motion planning of autonomous vehicles or robots in cluttered, unstructured environments. The proposed method is evaluated and compared with other triangulation-based methods in synthetic and complex scenarios collected from a real-world autonomous driving dataset. We have shown that the proposed method results in a more stable, long-term plan with a higher task completion rate, faster arrival time, a higher rate of successful plans, and fewer collisions compared to existing methods.
Multi-lane Cruising Using Hierarchical Planning and Reinforcement Learning
Oct 01, 2021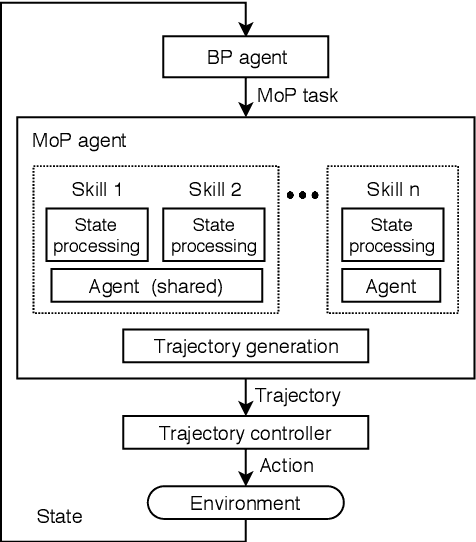
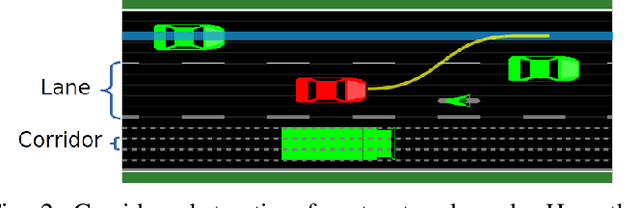
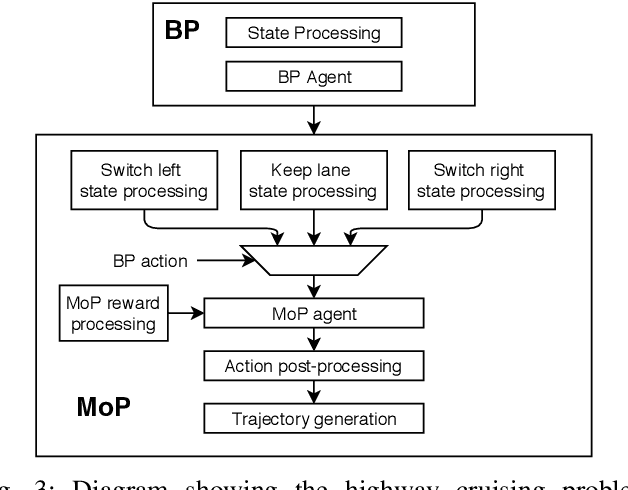
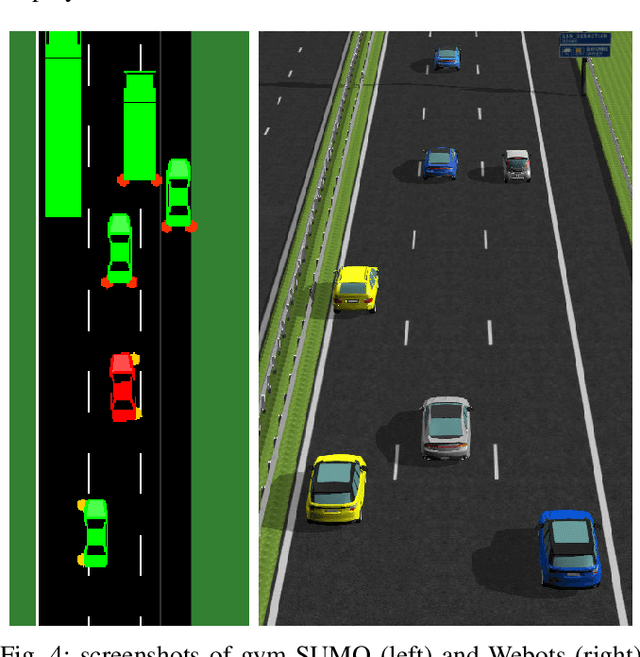
Competent multi-lane cruising requires using lane changes and within-lane maneuvers to achieve good speed and maintain safety. This paper proposes a design for autonomous multi-lane cruising by combining a hierarchical reinforcement learning framework with a novel state-action space abstraction. While the proposed solution follows the classical hierarchy of behavior decision, motion planning and control, it introduces a key intermediate abstraction within the motion planner to discretize the state-action space according to high level behavioral decisions. We argue that this design allows principled modular extension of motion planning, in contrast to using either monolithic behavior cloning or a large set of hand-written rules. Moreover, we demonstrate that our state-action space abstraction allows transferring of the trained models without retraining from a simulated environment with virtually no dynamics to one with significantly more realistic dynamics. Together, these results suggest that our proposed hierarchical architecture is a promising way to allow reinforcement learning to be applied to complex multi-lane cruising in the real world.
How To Not Drive: Learning Driving Constraints from Demonstration
Oct 01, 2021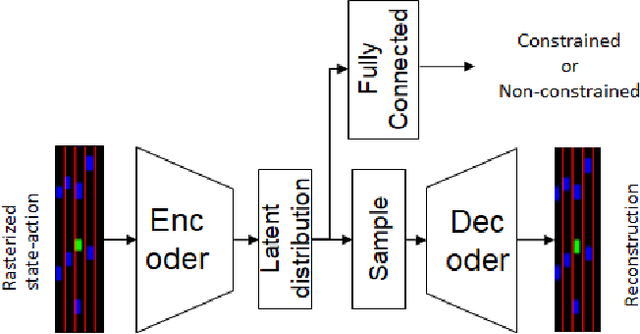
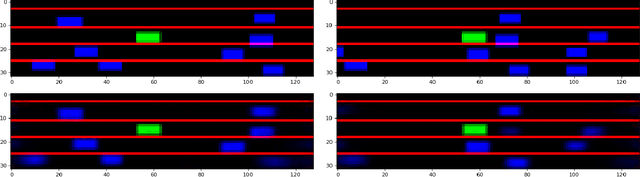

We propose a new scheme to learn motion planning constraints from human driving trajectories. Behavioral and motion planning are the key components in an autonomous driving system. The behavioral planning is responsible for high-level decision making required to follow traffic rules and interact with other road participants. The motion planner role is to generate feasible, safe trajectories for a self-driving vehicle to follow. The trajectories are generated through an optimization scheme to optimize a cost function based on metrics related to smoothness, movability, and comfort, and subject to a set of constraints derived from the planned behavior, safety considerations, and feasibility. A common practice is to manually design the cost function and constraints. Recent work has investigated learning the cost function from human driving demonstrations. While effective, the practical application of such approaches is still questionable in autonomous driving. In contrast, this paper focuses on learning driving constraints, which can be used as an add-on module to existing autonomous driving solutions. To learn the constraint, the planning problem is formulated as a constrained Markov Decision Process, whose elements are assumed to be known except the constraints. The constraints are then learned by learning the distribution of expert trajectories and estimating the probability of optimal trajectories belonging to the learned distribution. The proposed scheme is evaluated using NGSIM dataset, yielding less than 1\% collision rate and out of road maneuvers when the learned constraints is used in an optimization-based motion planner.
Motion Planning for Autonomous Vehicles in the Presence of Uncertainty Using Reinforcement Learning
Oct 01, 2021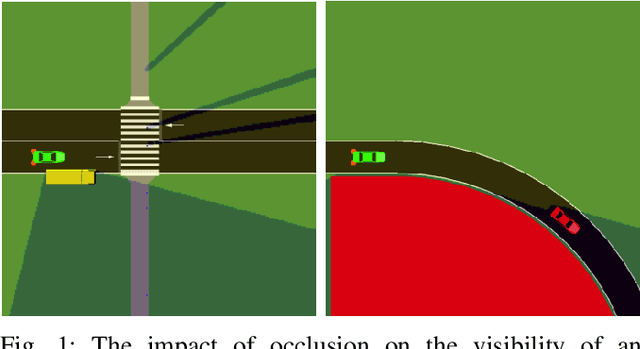
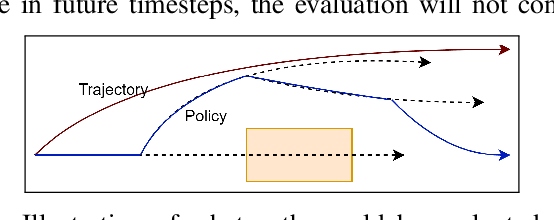
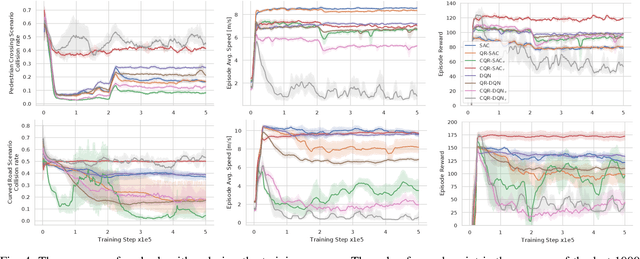
Motion planning under uncertainty is one of the main challenges in developing autonomous driving vehicles. In this work, we focus on the uncertainty in sensing and perception, resulted from a limited field of view, occlusions, and sensing range. This problem is often tackled by considering hypothetical hidden objects in occluded areas or beyond the sensing range to guarantee passive safety. However, this may result in conservative planning and expensive computation, particularly when numerous hypothetical objects need to be considered. We propose a reinforcement learning (RL) based solution to manage uncertainty by optimizing for the worst case outcome. This approach is in contrast to traditional RL, where the agents try to maximize the average expected reward. The proposed approach is built on top of the Distributional RL with its policy optimization maximizing the stochastic outcomes' lower bound. This modification can be applied to a range of RL algorithms. As a proof-of-concept, the approach is applied to two different RL algorithms, Soft Actor-Critic and DQN. The approach is evaluated against two challenging scenarios of pedestrians crossing with occlusion and curved roads with a limited field of view. The algorithm is trained and evaluated using the SUMO traffic simulator. The proposed approach yields much better motion planning behavior compared to conventional RL algorithms and behaves comparably to humans driving style.
A Sufficient Condition for Convex Hull Property in General Convex Spatio-Temporal Corridors
Sep 30, 2021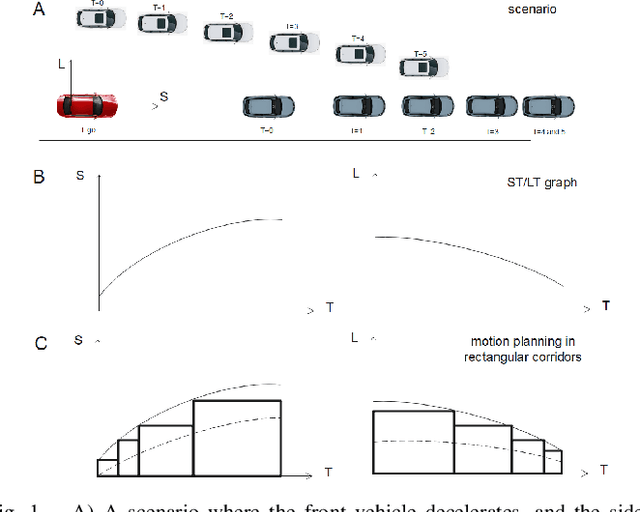
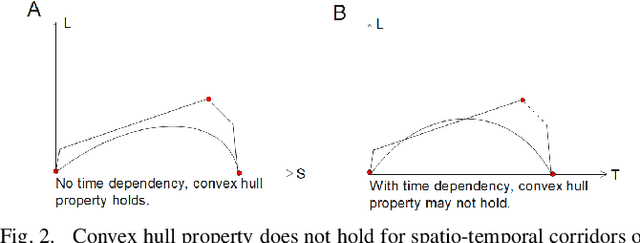
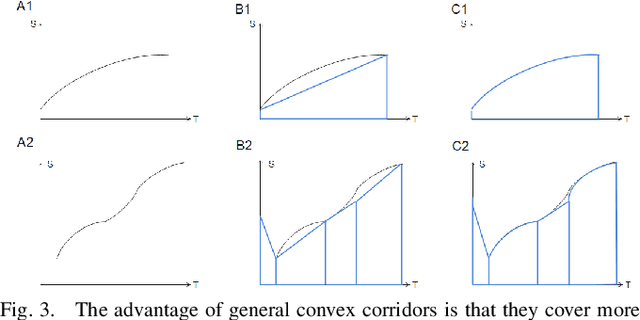
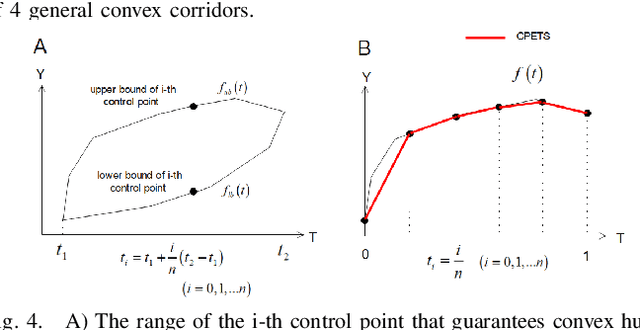
Motion planning is one of the key modules in autonomous driving systems to generate trajectories for self-driving vehicles to follow. A common motion planning approach is to generate trajectories within semantic safe corridors. The trajectories are generated by optimizing parametric curves (\textit{e.g.} Bezier curves) according to an objective function. To guarantee safety, the curves are required to satisfy the convex hull property, and be contained within the safety corridors. The convex hull property however does not necessary hold for time-dependent corridors, and depends on the shape of corridors. The existing approaches only support simple shape corridors, which is restrictive in real-world, complex scenarios. In this paper, we provide a sufficient condition for general convex, spatio-temporal corridors with theoretical proof of guaranteed convex hull property. The theorem allows for using more complicated shapes to generate spatio-temporal corridors and minimizing the uncovered search space to $O(\frac{1}{n^2})$ compared to $O(1)$ of trapezoidal corridors, which can improve the optimality of the solution. Simulation results show that using general convex corridors yields less harsh brakes, hence improving the overall smoothness of the resulting trajectories.
CoachNet: An Adversarial Sampling Approach for Reinforcement Learning
Jan 07, 2021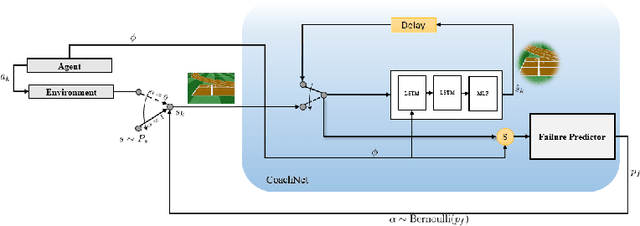

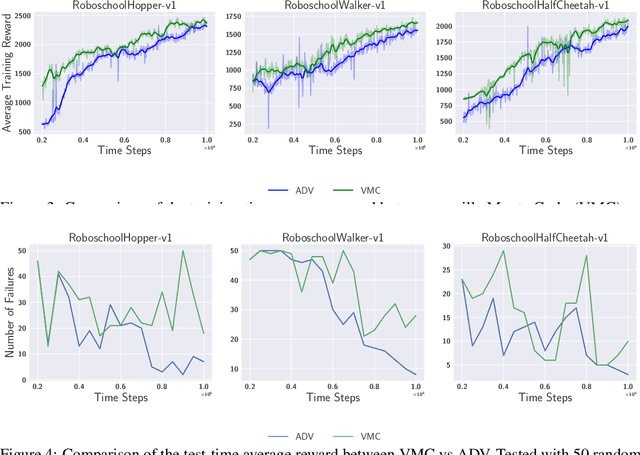
Despite the recent successes of reinforcement learning in games and robotics, it is yet to become broadly practical. Sample efficiency and unreliable performance in rare but challenging scenarios are two of the major obstacles. Drawing inspiration from the effectiveness of deliberate practice for achieving expert-level human performance, we propose a new adversarial sampling approach guided by a failure predictor named "CoachNet". CoachNet is trained online along with the agent to predict the probability of failure. This probability is then used in a stochastic sampling process to guide the agent to more challenging episodes. This way, instead of wasting time on scenarios that the agent has already mastered, training is focused on the agent's "weak spots". We present the design of CoachNet, explain its underlying principles, and empirically demonstrate its effectiveness in improving sample efficiency and test-time robustness in common continuous control tasks.
SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving
Nov 01, 2020
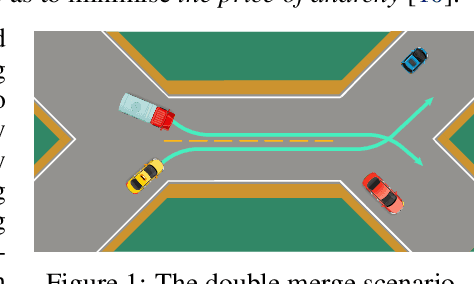
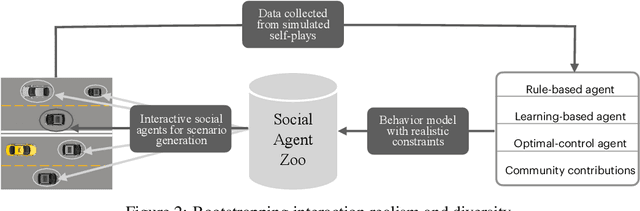
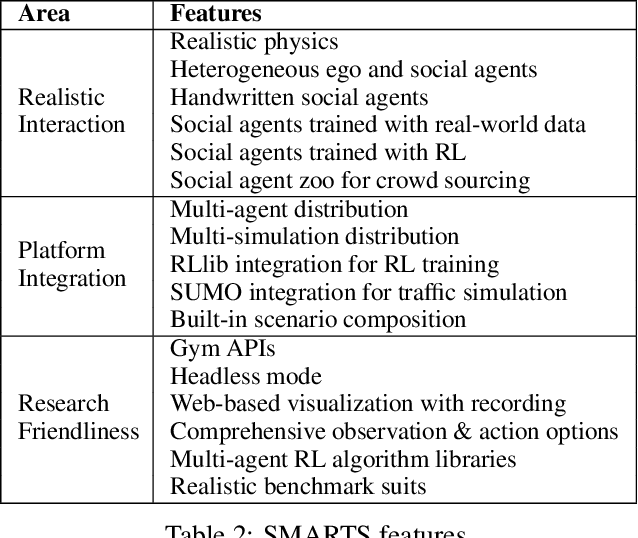
Multi-agent interaction is a fundamental aspect of autonomous driving in the real world. Despite more than a decade of research and development, the problem of how to competently interact with diverse road users in diverse scenarios remains largely unsolved. Learning methods have much to offer towards solving this problem. But they require a realistic multi-agent simulator that generates diverse and competent driving interactions. To meet this need, we develop a dedicated simulation platform called SMARTS (Scalable Multi-Agent RL Training School). SMARTS supports the training, accumulation, and use of diverse behavior models of road users. These are in turn used to create increasingly more realistic and diverse interactions that enable deeper and broader research on multi-agent interaction. In this paper, we describe the design goals of SMARTS, explain its basic architecture and its key features, and illustrate its use through concrete multi-agent experiments on interactive scenarios. We open-source the SMARTS platform and the associated benchmark tasks and evaluation metrics to encourage and empower research on multi-agent learning for autonomous driving. Our code is available at https://github.com/huawei-noah/SMARTS.
Practical Issues of Action-conditioned Next Image Prediction
Feb 08, 2018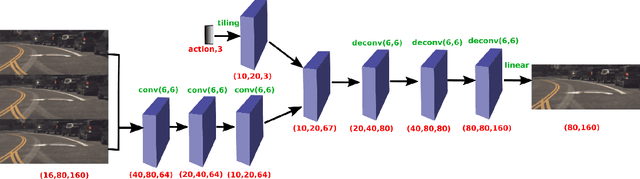
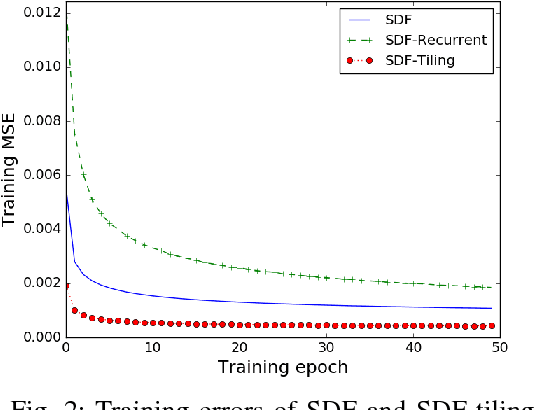


The problem of action-conditioned image prediction is to predict the expected next frame given the current camera frame the robot observes and an action selected by the robot. We provide the first comparison of two recent popular models, especially for image prediction on cars. Our major finding is that action tiling encoding is the most important factor leading to the remarkable performance of the CDNA model. We present a light-weight model by action tiling encoding which has a single-decoder feedforward architecture same as [action_video_prediction_honglak]. On a real driving dataset, the CDNA model achieves ${0.3986} \times 10^{-3}$ MSE and ${0.9846}$ Structure SIMilarity (SSIM) with a network size of about {\bfseries ${12.6}$ million} parameters. With a small network of fewer than {\bfseries ${1}$ million} parameters, our new model achieves a comparable performance to CDNA at ${0.3613} \times 10^{-3}$ MSE and ${0.9633}$ SSIM. Our model requires less memory, is more computationally efficient and is advantageous to be used inside self-driving vehicles.