 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative Log Likelihood Ratio Loss for Deep Neural Network Classification
Apr 27, 2018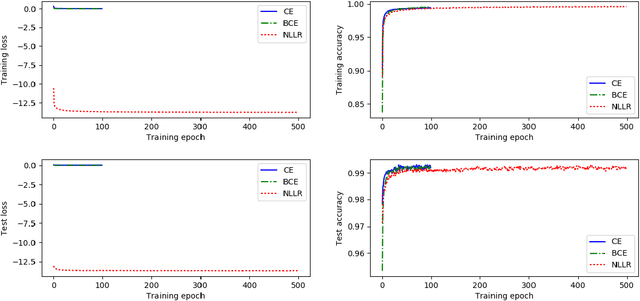

In deep neural network, the cross-entropy loss function is commonly used for classification. Minimizing cross-entropy is equivalent to maximizing likelihood under assumptions of uniform feature and class distributions. It belongs to generative training criteria which does not directly discriminate correct class from competing classes. We propose a discriminative loss function with negative log likelihood ratio between correct and competing classes. It significantly outperforms the cross-entropy loss on the CIFAR-10 image classification task.
Practical Issues of Action-conditioned Next Image Prediction
Feb 08, 2018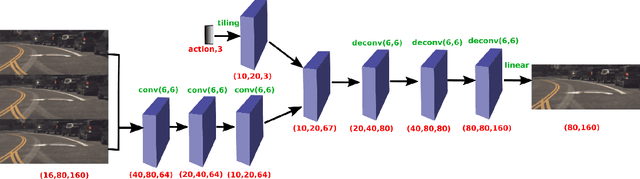
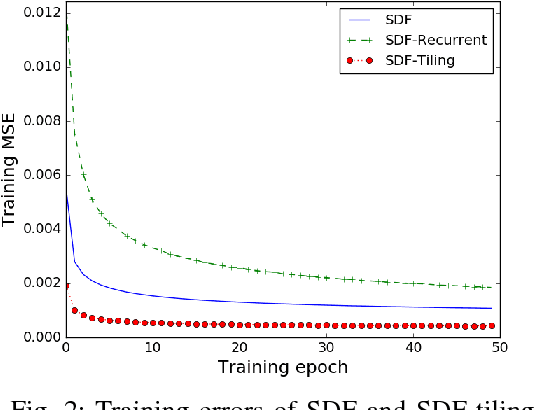


The problem of action-conditioned image prediction is to predict the expected next frame given the current camera frame the robot observes and an action selected by the robot. We provide the first comparison of two recent popular models, especially for image prediction on cars. Our major finding is that action tiling encoding is the most important factor leading to the remarkable performance of the CDNA model. We present a light-weight model by action tiling encoding which has a single-decoder feedforward architecture same as [action_video_prediction_honglak]. On a real driving dataset, the CDNA model achieves ${0.3986} \times 10^{-3}$ MSE and ${0.9846}$ Structure SIMilarity (SSIM) with a network size of about {\bfseries ${12.6}$ million} parameters. With a small network of fewer than {\bfseries ${1}$ million} parameters, our new model achieves a comparable performance to CDNA at ${0.3613} \times 10^{-3}$ MSE and ${0.9633}$ SSIM. Our model requires less memory, is more computationally efficient and is advantageous to be used inside self-driving vehicles.