 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces
Apr 09, 2026The emergence of Large Language Models (LLMs) has illuminated the potential for a general-purpose user simulator. However, existing benchmarks remain constrained to isolated scenarios, narrow action spaces, or synthetic data, failing to capture the holistic nature of authentic human behavior. To bridge this gap, we introduce OmniBehavior, the first user simulation benchmark constructed entirely from real-world data, integrating long-horizon, cross-scenario, and heterogeneous behavioral patterns into a unified framework. Based on this benchmark, we first provide empirical evidence that previous datasets with isolated scenarios suffer from tunnel vision, whereas real-world decision-making relies on long-term, cross-scenario causal chains. Extensive evaluations of state-of-the-art LLMs reveal that current models struggle to accurately simulate these complex behaviors, with performance plateauing even as context windows expand. Crucially, a systematic comparison between simulated and authentic behaviors uncovers a fundamental structural bias: LLMs tend to converge toward a positive average person, exhibiting hyper-activity, persona homogenization, and a Utopian bias. This results in the loss of individual differences and long-tail behaviors, highlighting critical directions for future high-fidelity simulation research.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Discrete Prior-based Temporal-coherent Content Prediction for Blind Face Video Restoration
Jan 17, 2025



Blind face video restoration aims to restore high-fidelity details from videos subjected to complex and unknown degradations. This task poses a significant challenge of managing temporal heterogeneity while at the same time maintaining stable face attributes. In this paper, we introduce a Discrete Prior-based Temporal-Coherent content prediction transformer to address the challenge, and our model is referred to as DP-TempCoh. Specifically, we incorporate a spatial-temporal-aware content prediction module to synthesize high-quality content from discrete visual priors, conditioned on degraded video tokens. To further enhance the temporal coherence of the predicted content, a motion statistics modulation module is designed to adjust the content, based on discrete motion priors in terms of cross-frame mean and variance. As a result, the statistics of the predicted content can match with that of real videos over time. By performing extensive experiments, we verify the effectiveness of the design elements and demonstrate the superior performance of our DP-TempCoh in both synthetically and naturally degraded video restoration.
Temporal Correlation Meets Embedding: Towards a 2nd Generation of JDE-based Real-Time Multi-Object Tracking
Jul 19, 2024



Joint Detection and Embedding(JDE) trackers have demonstrated excellent performance in Multi-Object Tracking(MOT) tasks by incorporating the extraction of appearance features as auxiliary tasks through embedding Re-Identification task(ReID) into the detector, achieving a balance between inference speed and tracking performance. However, solving the competition between the detector and the feature extractor has always been a challenge. Also, the issue of directly embedding the ReID task into MOT has remained unresolved. The lack of high discriminability in appearance features results in their limited utility. In this paper, we propose a new learning approach using cross-correlation to capture temporal information of objects. The feature extraction network is no longer trained solely on appearance features from each frame but learns richer motion features by utilizing feature heatmaps from consecutive frames, addressing the challenge of inter-class feature similarity. Furthermore, we apply our learning approach to a more lightweight feature extraction network, and treat the feature matching scores as strong cues rather than auxiliary cues, employing a appropriate weight calculation to reflect the compatibility between our obtained features and the MOT task. Our tracker, named TCBTrack, achieves state-of-the-art performance on multiple public benchmarks, i.e., MOT17, MOT20, and DanceTrack datasets. Specifically, on the DanceTrack test set, we achieve 56.8 HOTA, 58.1 IDF1 and 92.5 MOTA, making it the best online tracker that can achieve real-time performance. Comparative evaluations with other trackers prove that our tracker achieves the best balance between speed, robustness and accuracy.
Autonomous Vehicles as a Sensor: Simulating Data Collection Process
Aug 31, 2023



Urban traffic state estimation is pivotal in furnishing precise and reliable insights into traffic flow characteristics, thereby enabling efficient traffic management. Traditional traffic estimation methodologies have predominantly hinged on labor-intensive and costly techniques such as loop detectors and floating car data. Nevertheless, the relentless progression in autonomous driving technology has catalyzed an increasing interest in capitalizing on the extensive potential of on-board sensor data, giving rise to a novel concept known as "Autonomous Vehicles as a Sensor" (AVaaS). This paper innovatively refines the AVaaS concept by simulating the data collection process. We take real-world sensor attributes into account and employ more accurate estimation techniques based on the on-board sensor data. Such data can facilitate the estimation of high-resolution, link-level traffic states and, more extensively, online cluster- and network-level traffic states. We substantiate the viability of the AVaaS concept through a case study conducted using a real-world traffic simulation in Ingolstadt, Germany. The results attest to the ability of AVaaS in estimating both microscopic (link-level) and macroscopic (cluster- and network-level) traffic states, thereby highlighting the immense potential of the AVaaS concept in effecting precise and reliable traffic state estimation and also further applications.
ANT: Learning Accurate Network Throughput for Better Adaptive Video Streaming
May 05, 2021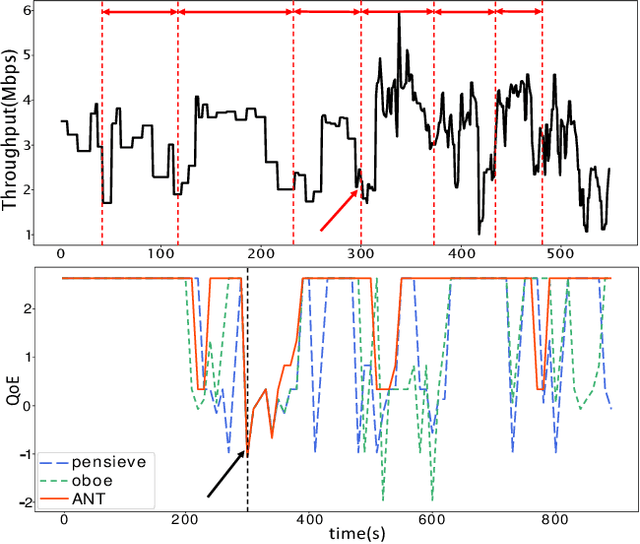
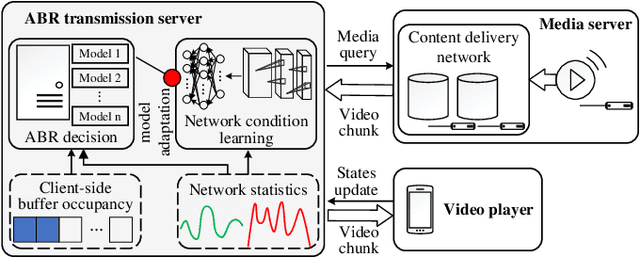
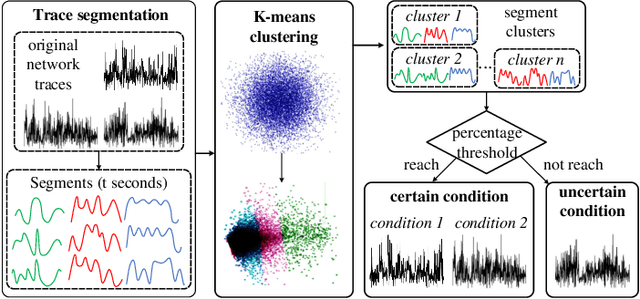
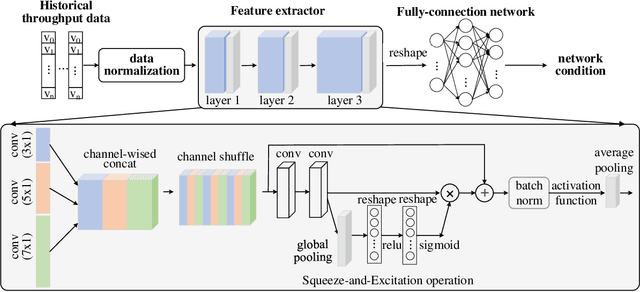
Adaptive Bit Rate (ABR) decision plays a crucial role for ensuring satisfactory Quality of Experience (QoE) in video streaming applications, in which past network statistics are mainly leveraged for future network bandwidth prediction. However, most algorithms, either rules-based or learning-driven approaches, feed throughput traces or classified traces based on traditional statistics (i.e., mean/standard deviation) to drive ABR decision, leading to compromised performances in specific scenarios. Given the diverse network connections (e.g., WiFi, cellular and wired link) from time to time, this paper thus proposes to learn the ANT (a.k.a., Accurate Network Throughput) model to characterize the full spectrum of network throughput dynamics in the past for deriving the proper network condition associated with a specific cluster of network throughput segments (NTS). Each cluster of NTS is then used to generate a dedicated ABR model, by which we wish to better capture the network dynamics for diverse connections. We have integrated the ANT model with existing reinforcement learning (RL)-based ABR decision engine, where different ABR models are applied to respond to the accurate network sensing for better rate decision. Extensive experiment results show that our approach can significantly improve the user QoE by 65.5% and 31.3% respectively, compared with the state-of-the-art Pensive and Oboe, across a wide range of network scenarios.
Practical Issues of Action-conditioned Next Image Prediction
Feb 08, 2018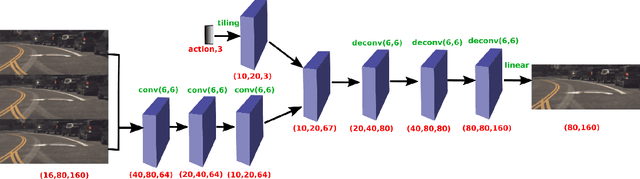
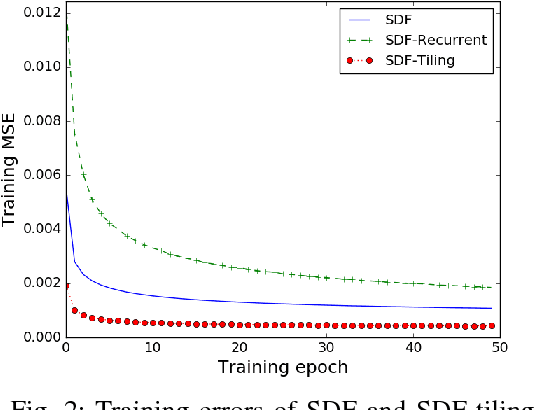


The problem of action-conditioned image prediction is to predict the expected next frame given the current camera frame the robot observes and an action selected by the robot. We provide the first comparison of two recent popular models, especially for image prediction on cars. Our major finding is that action tiling encoding is the most important factor leading to the remarkable performance of the CDNA model. We present a light-weight model by action tiling encoding which has a single-decoder feedforward architecture same as [action_video_prediction_honglak]. On a real driving dataset, the CDNA model achieves ${0.3986} \times 10^{-3}$ MSE and ${0.9846}$ Structure SIMilarity (SSIM) with a network size of about {\bfseries ${12.6}$ million} parameters. With a small network of fewer than {\bfseries ${1}$ million} parameters, our new model achieves a comparable performance to CDNA at ${0.3613} \times 10^{-3}$ MSE and ${0.9633}$ SSIM. Our model requires less memory, is more computationally efficient and is advantageous to be used inside self-driving vehicles.