 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human Speech to Ocean Signals: Transferring Speech Large Models for Underwater Acoustic Target Recognition
Jan 26, 2026Underwater acoustic target recognition (UATR) plays a vital role in marine applications but remains challenging due to limited labeled data and the complexity of ocean environments. This paper explores a central question: can speech large models (SLMs), trained on massive human speech corpora, be effectively transferred to underwater acoustics? To investigate this, we propose UATR-SLM, a simple framework that reuses the speech feature pipeline, adapts the SLM as an acoustic encoder, and adds a lightweight classifier.Experiments on the DeepShip and ShipsEar benchmarks show that UATR-SLM achieves over 99% in-domain accuracy, maintains strong robustness across variable signal lengths, and reaches up to 96.67% accuracy in cross-domain evaluation. These results highlight the strong transferability of SLMs to UATR, establishing a promising paradigm for leveraging speech foundation models in underwater acoustics.
GEA: Generation-Enhanced Alignment for Text-to-Image Person Retrieval
Nov 13, 2025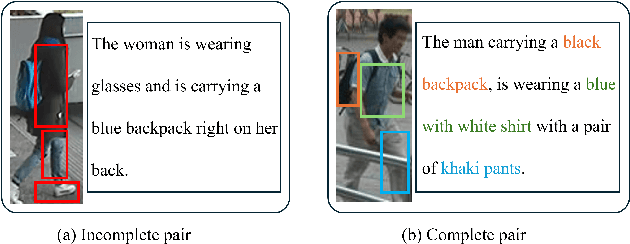
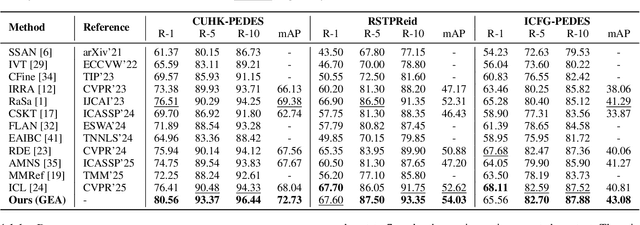
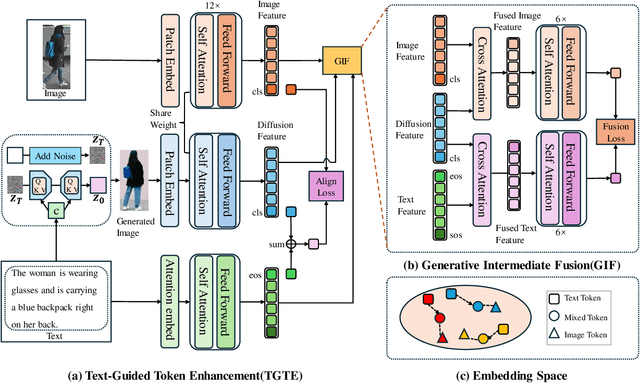
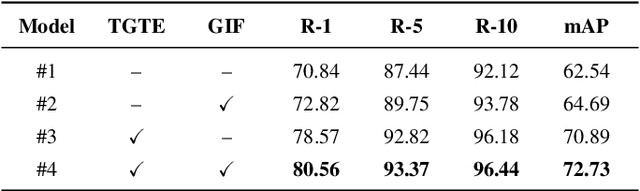
Text-to-Image Person Retrieval (TIPR) aims to retrieve person images based on natural language descriptions. Although many TIPR methods have achieved promising results, sometimes textual queries cannot accurately and comprehensively reflect the content of the image, leading to poor cross-modal alignment and overfitting to limited datasets. Moreover, the inherent modality gap between text and image further amplifies these issues, making accurate cross-modal retrieval even more challenging. To address these limitations, we propose the Generation-Enhanced Alignment (GEA) from a generative perspective. GEA contains two parallel modules: (1) Text-Guided Token Enhancement (TGTE), which introduces diffusion-generated images as intermediate semantic representations to bridge the gap between text and visual patterns. These generated images enrich the semantic representation of text and facilitate cross-modal alignment. (2) Generative Intermediate Fusion (GIF), which combines cross-attention between generated images, original images, and text features to generate a unified representation optimized by triplet alignment loss. We conduct extensive experiments on three public TIPR datasets, CUHK-PEDES, RSTPReid, and ICFG-PEDES, to evaluate the performance of GEA. The results justify the effectiveness of our method. More implementation details and extended results are available at https://github.com/sugelamyd123/Sup-for-GEA.
Collapsing Sequence-Level Data-Policy Coverage via Poisoning Attack in Offline Reinforcement Learning
Jun 12, 2025Offline reinforcement learning (RL) heavily relies on the coverage of pre-collected data over the target policy's distribution. Existing studies aim to improve data-policy coverage to mitigate distributional shifts, but overlook security risks from insufficient coverage, and the single-step analysis is not consistent with the multi-step decision-making nature of offline RL. To address this, we introduce the sequence-level concentrability coefficient to quantify coverage, and reveal its exponential amplification on the upper bound of estimation errors through theoretical analysis. Building on this, we propose the Collapsing Sequence-Level Data-Policy Coverage (CSDPC) poisoning attack. Considering the continuous nature of offline RL data, we convert state-action pairs into decision units, and extract representative decision patterns that capture multi-step behavior. We identify rare patterns likely to cause insufficient coverage, and poison them to reduce coverage and exacerbate distributional shifts. Experiments show that poisoning just 1% of the dataset can degrade agent performance by 90%. This finding provides new perspectives for analyzing and safeguarding the security of offline RL.
Associate Everything Detected: Facilitating Tracking-by-Detection to the Unknown
Sep 14, 2024



Multi-object tracking (MOT) emerges as a pivotal and highly promising branch in the field of computer vision. Classical closed-vocabulary MOT (CV-MOT) methods aim to track objects of predefined categories. Recently, some open-vocabulary MOT (OV-MOT) methods have successfully addressed the problem of tracking unknown categories. However, we found that the CV-MOT and OV-MOT methods each struggle to excel in the tasks of the other. In this paper, we present a unified framework, Associate Everything Detected (AED), that simultaneously tackles CV-MOT and OV-MOT by integrating with any off-the-shelf detector and supports unknown categories. Different from existing tracking-by-detection MOT methods, AED gets rid of prior knowledge (e.g. motion cues) and relies solely on highly robust feature learning to handle complex trajectories in OV-MOT tasks while keeping excellent performance in CV-MOT tasks. Specifically, we model the association task as a similarity decoding problem and propose a sim-decoder with an association-centric learning mechanism. The sim-decoder calculates similarities in three aspects: spatial, temporal, and cross-clip. Subsequently, association-centric learning leverages these threefold similarities to ensure that the extracted features are appropriate for continuous tracking and robust enough to generalize to unknown categories. Compared with existing powerful OV-MOT and CV-MOT methods, AED achieves superior performance on TAO, SportsMOT, and DanceTrack without any prior knowledge. Our code is available at https://github.com/balabooooo/AED.
AMNS: Attention-Weighted Selective Mask and Noise Label Suppression for Text-to-Image Person Retrieval
Sep 11, 2024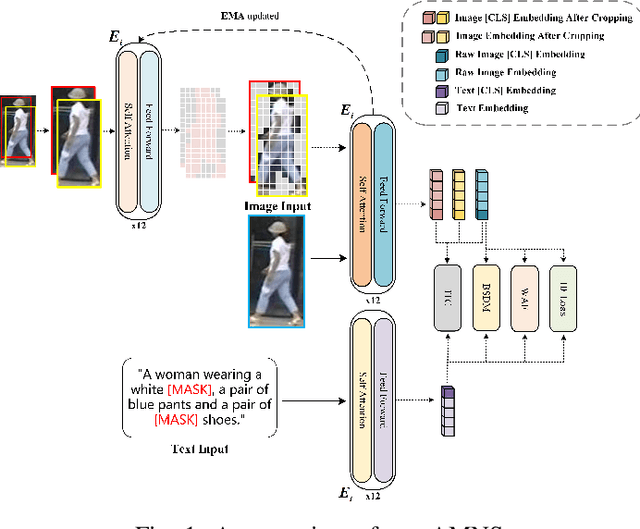
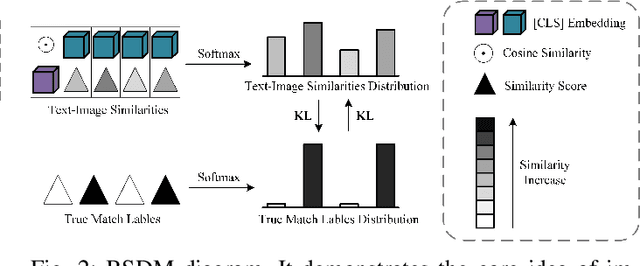
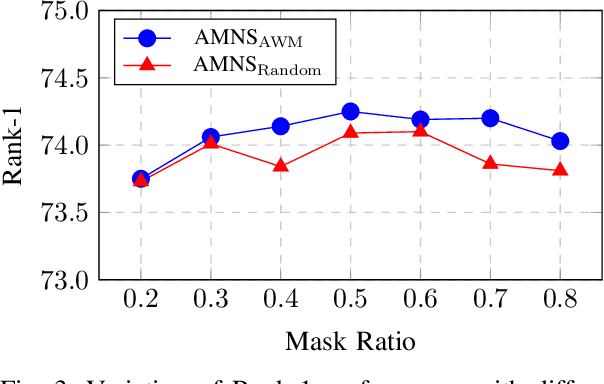
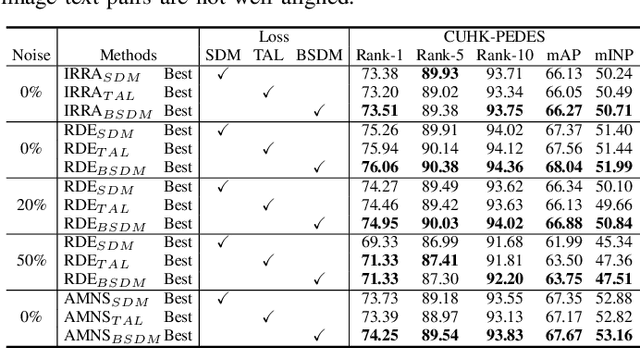
Text-to-image person retrieval aims to retrieve images of person given textual descriptions, and most methods implicitly assume that the training image-text pairs are correctly aligned, but in practice, under-correlated and false-correlated problems arise for image-text pairs due to poor image quality and mislabeling. Meanwhile, the random masking augmentation strategy may incorrectly discard semantic content resulting in the problem of generating noisy pairings between image lexical elements and text descriptions. To solve these two problems, we propose a new noise label suppression method and alleviate the problem generated by random mask through an attention-weighted selective mask strategy. In the proposed noise label suppression method, the effect of noise labels is suppressed by preventing the model from being overconfident by considering the inverse KL scatter loss, which is combined with the weight adjustment focus loss to further improve the model's recognition ability on difficult samples. On the other hand, Attention-Weighted Selective Mask processes the raw image through the EMA version of the image encoder, retaining some of the tokens with strong semantic associations with the corresponding text descriptions in order to extract better features. Numerous experiments validate the effectiveness of our approach in terms of dealing with noisy problems. The code will be available soon at https://github.com/RunQing715/AMNS.git.
Temporal Correlation Meets Embedding: Towards a 2nd Generation of JDE-based Real-Time Multi-Object Tracking
Jul 19, 2024



Joint Detection and Embedding(JDE) trackers have demonstrated excellent performance in Multi-Object Tracking(MOT) tasks by incorporating the extraction of appearance features as auxiliary tasks through embedding Re-Identification task(ReID) into the detector, achieving a balance between inference speed and tracking performance. However, solving the competition between the detector and the feature extractor has always been a challenge. Also, the issue of directly embedding the ReID task into MOT has remained unresolved. The lack of high discriminability in appearance features results in their limited utility. In this paper, we propose a new learning approach using cross-correlation to capture temporal information of objects. The feature extraction network is no longer trained solely on appearance features from each frame but learns richer motion features by utilizing feature heatmaps from consecutive frames, addressing the challenge of inter-class feature similarity. Furthermore, we apply our learning approach to a more lightweight feature extraction network, and treat the feature matching scores as strong cues rather than auxiliary cues, employing a appropriate weight calculation to reflect the compatibility between our obtained features and the MOT task. Our tracker, named TCBTrack, achieves state-of-the-art performance on multiple public benchmarks, i.e., MOT17, MOT20, and DanceTrack datasets. Specifically, on the DanceTrack test set, we achieve 56.8 HOTA, 58.1 IDF1 and 92.5 MOTA, making it the best online tracker that can achieve real-time performance. Comparative evaluations with other trackers prove that our tracker achieves the best balance between speed, robustness and accuracy.
Unsupervised Anomaly Detection via Masked Diffusion Posterior Sampling
Apr 27, 2024Reconstruction-based methods have been commonly used for unsupervised anomaly detection, in which a normal image is reconstructed and compared with the given test image to detect and locate anomalies. Recently, diffusion models have shown promising applications for anomaly detection due to their powerful generative ability. However, these models lack strict mathematical support for normal image reconstruction and unexpectedly suffer from low reconstruction quality. To address these issues, this paper proposes a novel and highly-interpretable method named Masked Diffusion Posterior Sampling (MDPS). In MDPS, the problem of normal image reconstruction is mathematically modeled as multiple diffusion posterior sampling for normal images based on the devised masked noisy observation model and the diffusion-based normal image prior under Bayesian framework. Using a metric designed from pixel-level and perceptual-level perspectives, MDPS can effectively compute the difference map between each normal posterior sample and the given test image. Anomaly scores are obtained by averaging all difference maps for multiple posterior samples. Exhaustive experiments on MVTec and BTAD datasets demonstrate that MDPS can achieve state-of-the-art performance in normal image reconstruction quality as well as anomaly detection and localization.
Learning Feature Fusion for Unsupervised Domain Adaptive Person Re-identification
May 19, 2022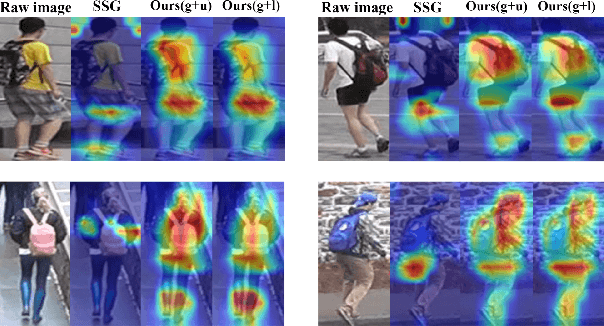
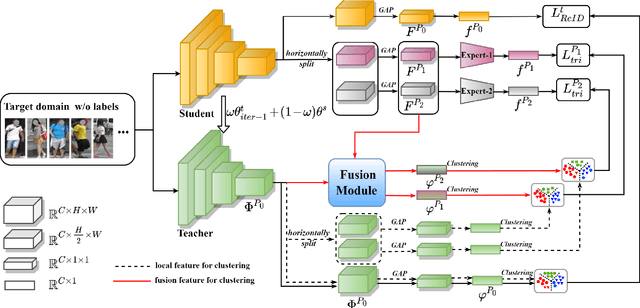
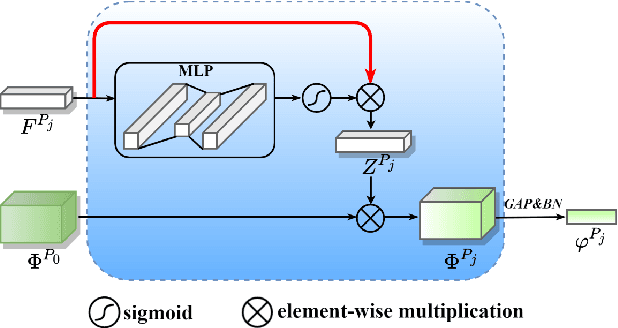
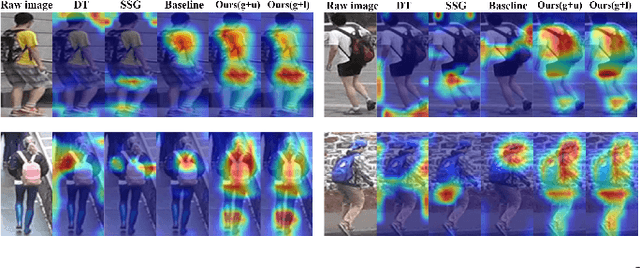
Unsupervised domain adaptive (UDA) person re-identification (ReID) has gained increasing attention for its effectiveness on the target domain without manual annotations. Most fine-tuning based UDA person ReID methods focus on encoding global features for pseudo labels generation, neglecting the local feature that can provide for the fine-grained information. To handle this issue, we propose a Learning Feature Fusion (LF2) framework for adaptively learning to fuse global and local features to obtain a more comprehensive fusion feature representation. Specifically, we first pre-train our model within a source domain, then fine-tune the model on unlabeled target domain based on the teacher-student training strategy. The average weighting teacher network is designed to encode global features, while the student network updating at each iteration is responsible for fine-grained local features. By fusing these multi-view features, multi-level clustering is adopted to generate diverse pseudo labels. In particular, a learnable Fusion Module (FM) for giving prominence to fine-grained local information within the global feature is also proposed to avoid obscure learning of multiple pseudo labels. Experiments show that our proposed LF2 framework outperforms the state-of-the-art with 73.5% mAP and 83.7% Rank1 on Market1501 to DukeMTMC-ReID, and achieves 83.2% mAP and 92.8% Rank1 on DukeMTMC-ReID to Market1501.
One More Check: Making "Fake Background" Be Tracked Again
Apr 19, 2021

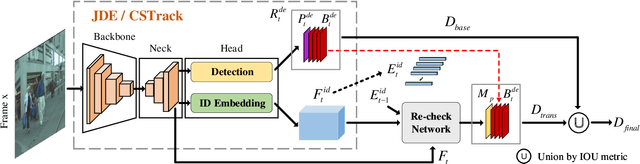
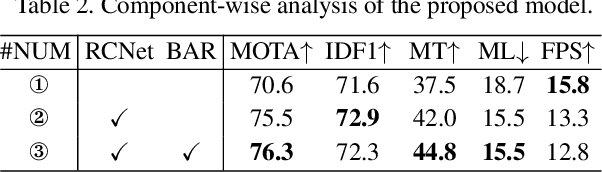
The one-shot multi-object tracking, which integrates object detection and ID embedding extraction into a unified network, has achieved groundbreaking results in recent years. However, current one-shot trackers solely rely on single-frame detections to predict candidate bounding boxes, which may be unreliable when facing disastrous visual degradation, e.g., motion blur, occlusions. Once a target bounding box is mistakenly classified as background by the detector, the temporal consistency of its corresponding tracklet will be no longer maintained, as shown in Fig. 1. In this paper, we set out to restore the misclassified bounding boxes, i.e., fake background, by proposing a re-check network. The re-check network propagates previous tracklets to the current frame by exploring the relation between cross-frame temporal cues and current candidates using the modified cross-correlation layer. The propagation results help to reload the "fake background" and eventually repair the broken tracklets. By inserting the re-check network to a strong baseline tracker CSTrack (a variant of JDE), our model achieves favorable gains by $70.7 \rightarrow 76.7$, $70.6 \rightarrow 76.3$ MOTA on MOT16 and MOT17, respectively. Code is publicly available at https://github.com/JudasDie/SOTS.
Rethinking the competition between detection and ReID in Multi-Object Tracking
Oct 23, 2020
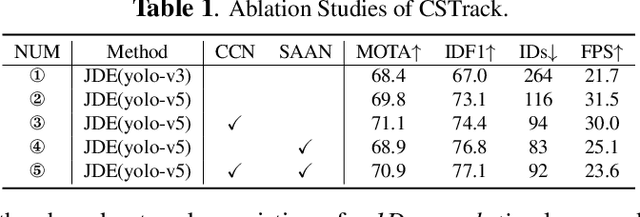
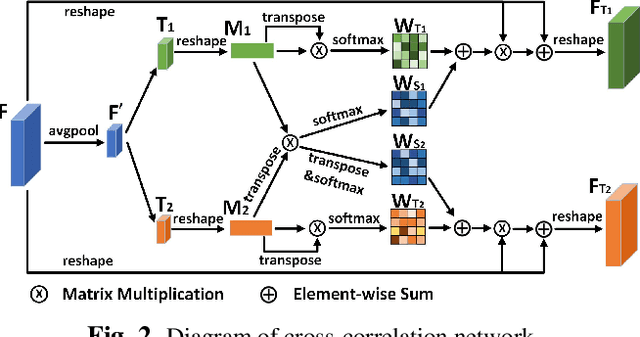
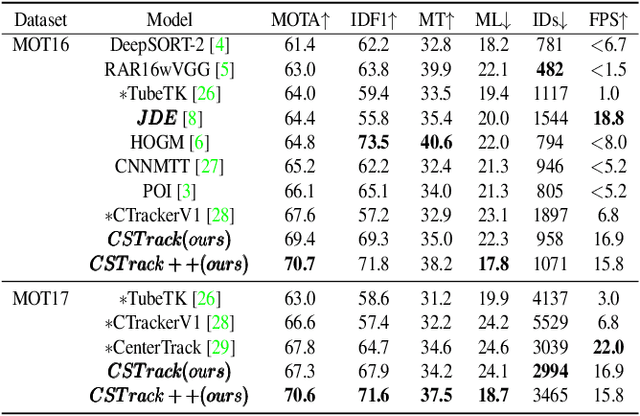
Due to balanced accuracy and speed, joint learning detection and ReID-based one-shot models have drawn great attention in multi-object tracking(MOT). However, the differences between the above two tasks in the one-shot tracking paradigm are unconsciously overlooked, leading to inferior performance than the two-stage methods. In this paper, we dissect the reasoning process of the aforementioned two tasks. Our analysis reveals that the competition of them inevitably hurts the learning of task-dependent representations, which further impedes the tracking performance. To remedy this issue, we propose a novel cross-correlation network that can effectively impel the separate branches to learn task-dependent representations. Furthermore, we introduce a scale-aware attention network that learns discriminative embeddings to improve the ReID capability. We integrate the delicately designed networks into a one-shot online MOT system, dubbed CSTrack. Without bells and whistles, our model achieves new state-of-the-art performances on MOT16 and MOT17. We will release our code to facilitate further work.