 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Anomaly Detection via Masked Diffusion Posterior Sampling
Apr 27, 2024

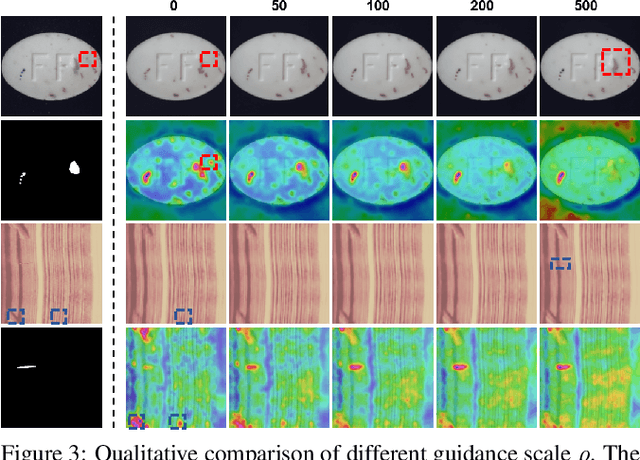
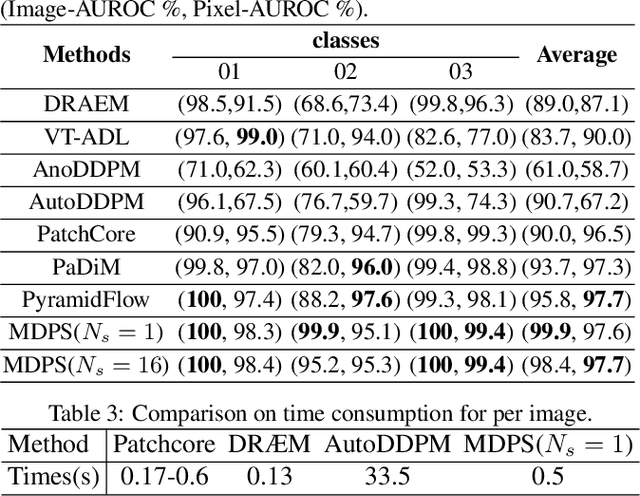
Reconstruction-based methods have been commonly used for unsupervised anomaly detection, in which a normal image is reconstructed and compared with the given test image to detect and locate anomalies. Recently, diffusion models have shown promising applications for anomaly detection due to their powerful generative ability. However, these models lack strict mathematical support for normal image reconstruction and unexpectedly suffer from low reconstruction quality. To address these issues, this paper proposes a novel and highly-interpretable method named Masked Diffusion Posterior Sampling (MDPS). In MDPS, the problem of normal image reconstruction is mathematically modeled as multiple diffusion posterior sampling for normal images based on the devised masked noisy observation model and the diffusion-based normal image prior under Bayesian framework. Using a metric designed from pixel-level and perceptual-level perspectives, MDPS can effectively compute the difference map between each normal posterior sample and the given test image. Anomaly scores are obtained by averaging all difference maps for multiple posterior samples. Exhaustive experiments on MVTec and BTAD datasets demonstrate that MDPS can achieve state-of-the-art performance in normal image reconstruction quality as well as anomaly detection and localization.
Variational Probabilistic Fusion Network for RGB-T Semantic Segmentation
Jul 17, 2023RGB-T semantic segmentation has been widely adopted to handle hard scenes with poor lighting conditions by fusing different modality features of RGB and thermal images. Existing methods try to find an optimal fusion feature for segmentation, resulting in sensitivity to modality noise, class-imbalance, and modality bias. To overcome the problems, this paper proposes a novel Variational Probabilistic Fusion Network (VPFNet), which regards fusion features as random variables and obtains robust segmentation by averaging segmentation results under multiple samples of fusion features. The random samples generation of fusion features in VPFNet is realized by a novel Variational Feature Fusion Module (VFFM) designed based on variation attention. To further avoid class-imbalance and modality bias, we employ the weighted cross-entropy loss and introduce prior information of illumination and category to control the proposed VFFM. Experimental results on MFNet and PST900 datasets demonstrate that the proposed VPFNet can achieve state-of-the-art segmentation performance.
DRTAM: Dual Rank-1 Tensor Attention Module
Mar 11, 2022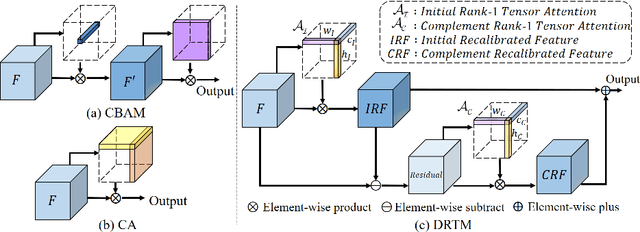
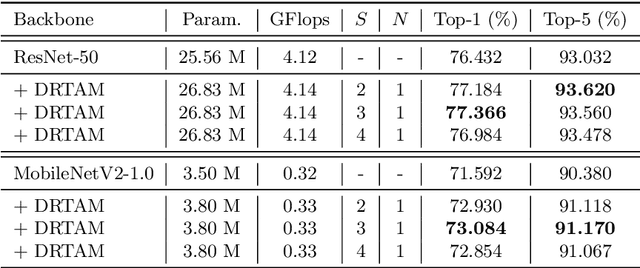
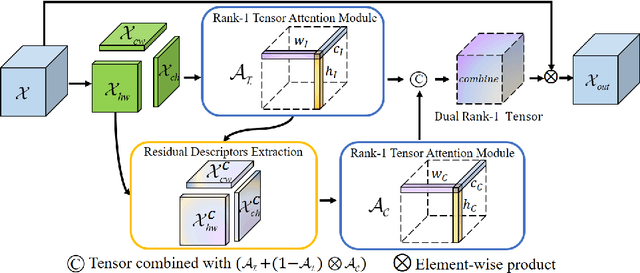
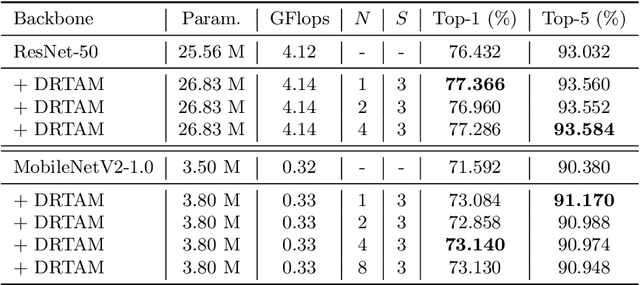
Recently, attention mechanisms have been extensively investigated in computer vision, but few of them show excellent performance on both large and mobile networks. This paper proposes Dual Rank-1 Tensor Attention Module (DRTAM), a novel residual-attention-learning-guided attention module for feed-forward convolutional neural networks. Given a 3D feature tensor map, DRTAM firstly generates three 2D feature descriptors along three axes. Then, using three descriptors, DRTAM sequentially infers two rank-1 tensor attention maps, the initial attention map and the complement attention map, combines and multiplied them to the input feature map for adaptive feature refinement(see Fig.1(c)). To generate two attention maps, DRTAM introduces rank-1 tensor attention module (RTAM) and residual descriptors extraction module (RDEM): RTAM divides each 2D feature descriptors into several chunks, and generate three factor vectors of a rank-1 tensor attention map by employing strip pooling on each chunk so that local and long-range contextual information can be captured along three dimension respectively; RDEM generates three 2D feature descriptors of the residual feature to produce the complement attention map, using three factor vectors of the initial attention map and three descriptors of the input feature. Extensive experimental results on ImageNet-1K, MS COCO and PASCAL VOC demonstrate that DRTAM achieves competitive performance on both large and mobile networks compare with other state-of-the-art attention modules.