 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRTAM: Dual Rank-1 Tensor Attention Module
Paper and Code
Mar 11, 2022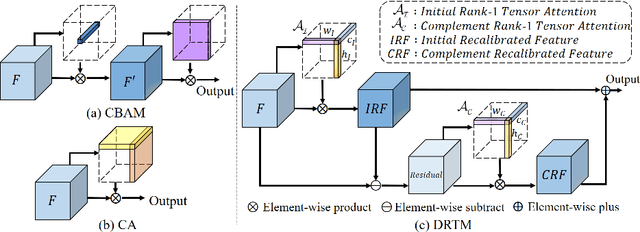
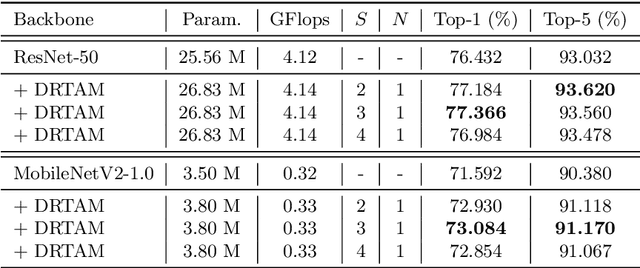
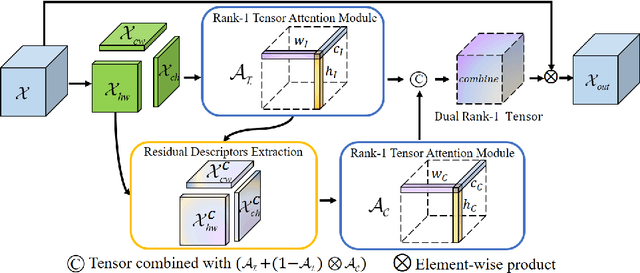
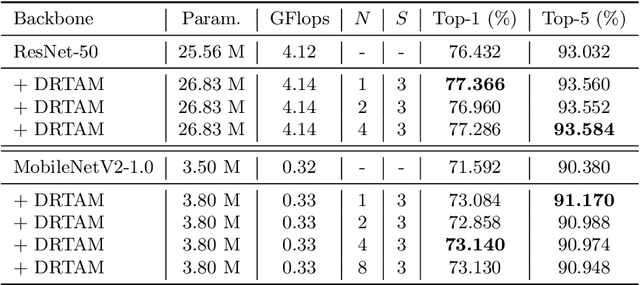
Recently, attention mechanisms have been extensively investigated in computer vision, but few of them show excellent performance on both large and mobile networks. This paper proposes Dual Rank-1 Tensor Attention Module (DRTAM), a novel residual-attention-learning-guided attention module for feed-forward convolutional neural networks. Given a 3D feature tensor map, DRTAM firstly generates three 2D feature descriptors along three axes. Then, using three descriptors, DRTAM sequentially infers two rank-1 tensor attention maps, the initial attention map and the complement attention map, combines and multiplied them to the input feature map for adaptive feature refinement(see Fig.1(c)). To generate two attention maps, DRTAM introduces rank-1 tensor attention module (RTAM) and residual descriptors extraction module (RDEM): RTAM divides each 2D feature descriptors into several chunks, and generate three factor vectors of a rank-1 tensor attention map by employing strip pooling on each chunk so that local and long-range contextual information can be captured along three dimension respectively; RDEM generates three 2D feature descriptors of the residual feature to produce the complement attention map, using three factor vectors of the initial attention map and three descriptors of the input feature. Extensive experimental results on ImageNet-1K, MS COCO and PASCAL VOC demonstrate that DRTAM achieves competitive performance on both large and mobile networks compare with other state-of-the-art attention modules.