 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXaMCaP: Subset Selection with Entropy Gain Maximization for Probing Capability Gains of Large Chart Understanding Training Sets
Feb 04, 2026Recent works focus on synthesizing Chart Understanding (ChartU) training sets to inject advanced chart knowledge into Multimodal Large Language Models (MLLMs), where the sufficiency of the knowledge is typically verified by quantifying capability gains via the fine-tune-then-evaluate paradigm. However, full-set fine-tuning MLLMs to assess such gains incurs significant time costs, hindering the iterative refinement cycles of the ChartU dataset. Reviewing the ChartU dataset synthesis and data selection domains, we find that subsets can potentially probe the MLLMs' capability gains from full-set fine-tuning. Given that data diversity is vital for boosting MLLMs' performance and entropy reflects this feature, we propose EXaMCaP, which uses entropy gain maximization to select a subset. To obtain a high-diversity subset, EXaMCaP chooses the maximum-entropy subset from the large ChartU dataset. As enumerating all possible subsets is impractical, EXaMCaP iteratively selects samples to maximize the gain in set entropy relative to the current set, approximating the maximum-entropy subset of the full dataset. Experiments show that EXaMCaP outperforms baselines in probing the capability gains of the ChartU training set, along with its strong effectiveness across diverse subset sizes and compatibility with various MLLM architectures.
QVLA: Not All Channels Are Equal in Vision-Language-Action Model's Quantization
Feb 03, 2026The advent of Vision-Language-Action (VLA) models represents a significant leap for embodied intelligence, yet their immense computational demands critically hinder deployment on resource-constrained robotic platforms. Intuitively, low-bit quantization is a prevalent and preferred technique for large-scale model compression. However, we find that a systematic analysis of VLA model's quantization is fundamentally lacking. We argue that naively applying uniform-bit quantization from Large Language Models (LLMs) to robotics is flawed, as these methods prioritize passive data fidelity while ignoring how minor action deviations compound into catastrophic task failures. To bridge this gap, we introduce QVLA, the first action-centric quantization framework specifically designed for embodied control. In a sharp departure from the rigid, uniform-bit quantization of LLM-based methods, QVLA introduces a highly granular, channel-wise bit allocation strategy. Its core mechanism is to directly measure the final action-space sensitivity when quantizing each individual channel to various bit-widths. This process yields a precise, per-channel importance metric that guides a global optimization, which elegantly unifies quantization and pruning (0-bit) into a single, cohesive framework. Extensive evaluations on different baselines demonstrate the superiority of our approach. In the LIBERO, the quantization version of OpenVLA-OFT with our method requires only 29.2% of the original model's VRAM while maintaining 98.9% of its original performance and achieving a 1.49x speedup. This translates to a 22.6% performance improvement over the LLM-derived method SmoothQuant. Our work establishes a new, principled foundation for compressing VLA models in robotics, paving the way for deploying powerful, large-scale models on real-world hardware. Code will be released.
The Illusion of Forgetting: Attack Unlearned Diffusion via Initial Latent Variable Optimization
Jan 30, 2026Although unlearning-based defenses claim to purge Not-Safe-For-Work (NSFW) concepts from diffusion models (DMs), we reveals that this "forgetting" is largely an illusion. Unlearning partially disrupts the mapping between linguistic symbols and the underlying knowledge, which remains intact as dormant memories. We find that the distributional discrepancy in the denoising process serves as a measurable indicator of how much of the mapping is retained, also reflecting the strength of unlearning. Inspired by this, we propose IVO (Initial Latent Variable Optimization), a concise and powerful attack framework that reactivates these dormant memories by reconstructing the broken mappings. Through Image Inversion}, Adversarial Optimization and Reused Attack, IVO optimizes initial latent variables to realign the noise distribution of unlearned models with their original unsafe states. Extensive experiments across 8 widely used unlearning techniques demonstrate that IVO achieves superior attack success rates and strong semantic consistency, exposing fundamental flaws in current defenses. The code is available at anonymous.4open.science/r/IVO/. Warning: This paper has unsafe images that may offend some readers.
Late Breaking Results: Conversion of Neural Networks into Logic Flows for Edge Computing
Jan 29, 2026Neural networks have been successfully applied in various resource-constrained edge devices, where usually central processing units (CPUs) instead of graphics processing units exist due to limited power availability. State-of-the-art research still focuses on efficiently executing enormous numbers of multiply-accumulate (MAC) operations. However, CPUs themselves are not good at executing such mathematical operations on a large scale, since they are more suited to execute control flow logic, i.e., computer algorithms. To enhance the computation efficiency of neural networks on CPUs, in this paper, we propose to convert them into logic flows for execution. Specifically, neural networks are first converted into equivalent decision trees, from which decision paths with constant leaves are then selected and compressed into logic flows. Such logic flows consist of if and else structures and a reduced number of MAC operations. Experimental results demonstrate that the latency can be reduced by up to 14.9 % on a simulated RISC-V CPU without any accuracy degradation. The code is open source at https://github.com/TUDa-HWAI/NN2Logic
Learning Functional Graphs with Nonlinear Sufficient Dimension Reduction
Jan 22, 2026Functional graphical models have undergone extensive development during the recent years, leading to a variety models such as the functional Gaussian graphical model, the functional copula Gaussian graphical model, the functional Bayesian graphical model, the nonparametric functional additive graphical model, and the conditional functional graphical model. These models rely either on some parametric form of distributions on random functions, or on additive conditional independence, a criterion that is different from probabilistic conditional independence. In this paper we introduce a nonparametric functional graphical model based on functional sufficient dimension reduction. Our method not only relaxes the Gaussian or copula Gaussian assumptions, but also enhances estimation accuracy by avoiding the ``curse of dimensionality''. Moreover, it retains the probabilistic conditional independence as the criterion to determine the absence of edges. By doing simulation study and analysis of the f-MRI dataset, we demonstrate the advantages of our method.
SoLA-Vision: Fine-grained Layer-wise Linear Softmax Hybrid Attention
Jan 16, 2026Standard softmax self-attention excels in vision tasks but incurs quadratic complexity O(N^2), limiting high-resolution deployment. Linear attention reduces the cost to O(N), yet its compressed state representations can impair modeling capacity and accuracy. We present an analytical study that contrasts linear and softmax attention for visual representation learning from a layer-stacking perspective. We further conduct systematic experiments on layer-wise hybridization patterns of linear and softmax attention. Our results show that, compared with rigid intra-block hybrid designs, fine-grained layer-wise hybridization can match or surpass performance while requiring fewer softmax layers. Building on these findings, we propose SoLA-Vision (Softmax-Linear Attention Vision), a flexible layer-wise hybrid attention backbone that enables fine-grained control over how linear and softmax attention are integrated. By strategically inserting a small number of global softmax layers, SoLA-Vision achieves a strong trade-off between accuracy and computational cost. On ImageNet-1K, SoLA-Vision outperforms purely linear and other hybrid attention models. On dense prediction tasks, it consistently surpasses strong baselines by a considerable margin. Code will be released.
Structure-Preserving Nonlinear Sufficient Dimension Reduction for Tensors
Dec 23, 2025We introduce two nonlinear sufficient dimension reduction methods for regressions with tensor-valued predictors. Our goal is two-fold: the first is to preserve the tensor structure when performing dimension reduction, particularly the meaning of the tensor modes, for improved interpretation; the second is to substantially reduce the number of parameters in dimension reduction, thereby achieving model parsimony and enhancing estimation accuracy. Our two tensor dimension reduction methods echo the two commonly used tensor decomposition mechanisms: one is the Tucker decomposition, which reduces a larger tensor to a smaller one; the other is the CP-decomposition, which represents an arbitrary tensor as a sequence of rank-one tensors. We developed the Fisher consistency of our methods at the population level and established their consistency and convergence rates. Both methods are easy to implement numerically: the Tucker-form can be implemented through a sequence of least-squares steps, and the CP-form can be implemented through a sequence of singular value decompositions. We investigated the finite-sample performance of our methods and showed substantial improvement in accuracy over existing methods in simulations and two data applications.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


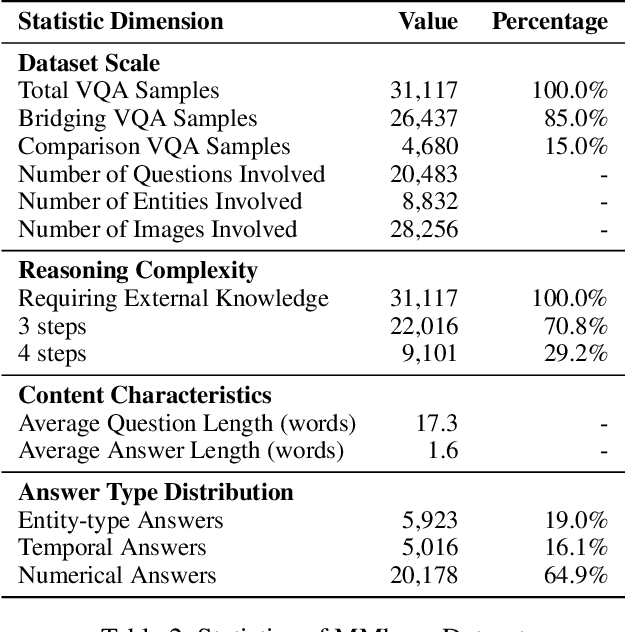
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
OBJVanish: Physically Realizable Text-to-3D Adv. Generation of LiDAR-Invisible Objects
Oct 08, 2025LiDAR-based 3D object detectors are fundamental to autonomous driving, where failing to detect objects poses severe safety risks. Developing effective 3D adversarial attacks is essential for thoroughly testing these detection systems and exposing their vulnerabilities before real-world deployment. However, existing adversarial attacks that add optimized perturbations to 3D points have two critical limitations: they rarely cause complete object disappearance and prove difficult to implement in physical environments. We introduce the text-to-3D adversarial generation method, a novel approach enabling physically realizable attacks that can generate 3D models of objects truly invisible to LiDAR detectors and be easily realized in the real world. Specifically, we present the first empirical study that systematically investigates the factors influencing detection vulnerability by manipulating the topology, connectivity, and intensity of individual pedestrian 3D models and combining pedestrians with multiple objects within the CARLA simulation environment. Building on the insights, we propose the physically-informed text-to-3D adversarial generation (Phy3DAdvGen) that systematically optimizes text prompts by iteratively refining verbs, objects, and poses to produce LiDAR-invisible pedestrians. To ensure physical realizability, we construct a comprehensive object pool containing 13 3D models of real objects and constrain Phy3DAdvGen to generate 3D objects based on combinations of objects in this set. Extensive experiments demonstrate that our approach can generate 3D pedestrians that evade six state-of-the-art (SOTA) LiDAR 3D detectors in both CARLA simulation and physical environments, thereby highlighting vulnerabilities in safety-critical applications.
Large Language Models (LLMs) for Electronic Design Automation (EDA)
Aug 27, 2025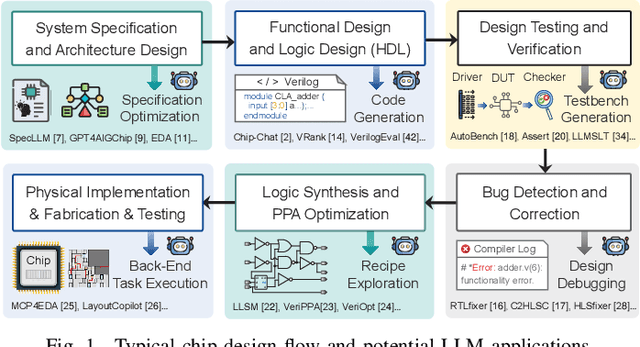
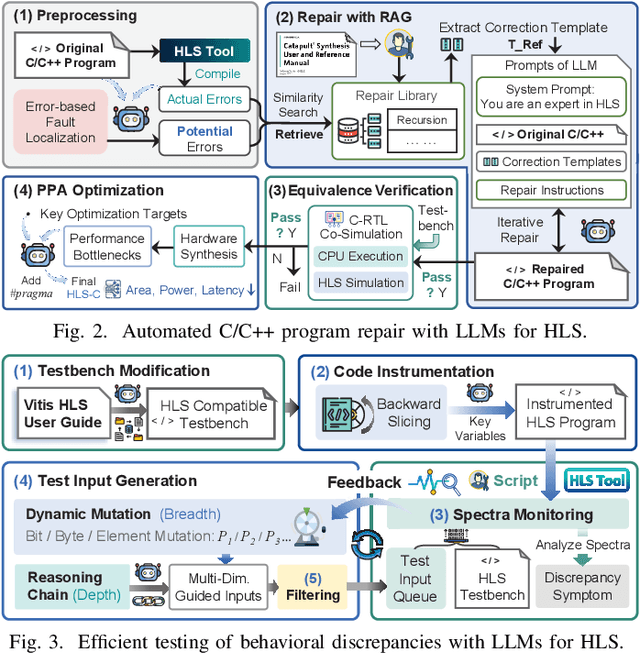
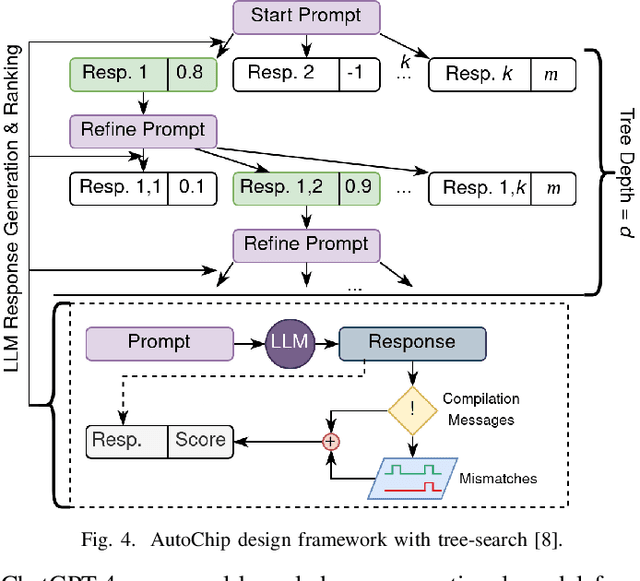
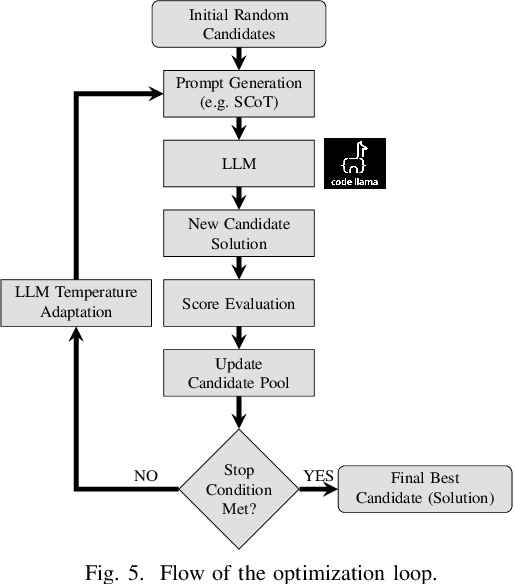
With the growing complexity of modern integrated circuits, hardware engineers are required to devote more effort to the full design-to-manufacturing workflow. This workflow involves numerous iterations, making it both labor-intensive and error-prone. Therefore, there is an urgent demand for more efficient Electronic Design Automation (EDA) solutions to accelerate hardware development. Recently, large language models (LLMs) have shown remarkable advancements in contextual comprehension, logical reasoning, and generative capabilities. Since hardware designs and intermediate scripts can be represented as text, integrating LLM for EDA offers a promising opportunity to simplify and even automate the entire workflow. Accordingly, this paper provides a comprehensive overview of incorporating LLMs into EDA, with emphasis on their capabilities, limitations, and future opportunities. Three case studies, along with their outlook, are introduced to demonstrate the capabilities of LLMs in hardware design, testing, and optimization. Finally, future directions and challenges are highlighted to further explore the potential of LLMs in shaping the next-generation EDA, providing valuable insights for researchers interested in leveraging advanced AI technologies for EDA.