 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Forgetting: Attack Unlearned Diffusion via Initial Latent Variable Optimization
Jan 30, 2026Although unlearning-based defenses claim to purge Not-Safe-For-Work (NSFW) concepts from diffusion models (DMs), we reveals that this "forgetting" is largely an illusion. Unlearning partially disrupts the mapping between linguistic symbols and the underlying knowledge, which remains intact as dormant memories. We find that the distributional discrepancy in the denoising process serves as a measurable indicator of how much of the mapping is retained, also reflecting the strength of unlearning. Inspired by this, we propose IVO (Initial Latent Variable Optimization), a concise and powerful attack framework that reactivates these dormant memories by reconstructing the broken mappings. Through Image Inversion}, Adversarial Optimization and Reused Attack, IVO optimizes initial latent variables to realign the noise distribution of unlearned models with their original unsafe states. Extensive experiments across 8 widely used unlearning techniques demonstrate that IVO achieves superior attack success rates and strong semantic consistency, exposing fundamental flaws in current defenses. The code is available at anonymous.4open.science/r/IVO/. Warning: This paper has unsafe images that may offend some readers.
Adaptive and Iterative Point Cloud Denoising with Score-Based Diffusion Model
Sep 18, 2025Point cloud denoising task aims to recover the clean point cloud from the scanned data coupled with different levels or patterns of noise. The recent state-of-the-art methods often train deep neural networks to update the point locations towards the clean point cloud, and empirically repeat the denoising process several times in order to obtain the denoised results. It is not clear how to efficiently arrange the iterative denoising processes to deal with different levels or patterns of noise. In this paper, we propose an adaptive and iterative point cloud denoising method based on the score-based diffusion model. For a given noisy point cloud, we first estimate the noise variation and determine an adaptive denoising schedule with appropriate step sizes, then invoke the trained network iteratively to update point clouds following the adaptive schedule. To facilitate this adaptive and iterative denoising process, we design the network architecture and a two-stage sampling strategy for the network training to enable feature fusion and gradient fusion for iterative denoising. Compared to the state-of-the-art point cloud denoising methods, our approach obtains clean and smooth denoised point clouds, while preserving the shape boundary and details better. Our results not only outperform the other methods both qualitatively and quantitatively, but also are preferable on the synthetic dataset with different patterns of noises, as well as the real-scanned dataset.
Self-Supervised Continuous Colormap Recovery from a 2D Scalar Field Visualization without a Legend
Jul 28, 2025Recovering a continuous colormap from a single 2D scalar field visualization can be quite challenging, especially in the absence of a corresponding color legend. In this paper, we propose a novel colormap recovery approach that extracts the colormap from a color-encoded 2D scalar field visualization by simultaneously predicting the colormap and underlying data using a decoupling-and-reconstruction strategy. Our approach first separates the input visualization into colormap and data using a decoupling module, then reconstructs the visualization with a differentiable color-mapping module. To guide this process, we design a reconstruction loss between the input and reconstructed visualizations, which serves both as a constraint to ensure strong correlation between colormap and data during training, and as a self-supervised optimizer for fine-tuning the predicted colormap of unseen visualizations during inferencing. To ensure smoothness and correct color ordering in the extracted colormap, we introduce a compact colormap representation using cubic B-spline curves and an associated color order loss. We evaluate our method quantitatively and qualitatively on a synthetic dataset and a collection of real-world visualizations from the VIS30K dataset. Additionally, we demonstrate its utility in two prototype applications -- colormap adjustment and colormap transfer -- and explore its generalization to visualizations with color legends and ones encoded using discrete color palettes.
Pay Less Attention to Deceptive Artifacts: Robust Detection of Compressed Deepfakes on Online Social Networks
Jun 25, 2025



With the rapid advancement of deep learning, particularly through generative adversarial networks (GANs) and diffusion models (DMs), AI-generated images, or ``deepfakes", have become nearly indistinguishable from real ones. These images are widely shared across Online Social Networks (OSNs), raising concerns about their misuse. Existing deepfake detection methods overlook the ``block effects" introduced by compression in OSNs, which obscure deepfake artifacts, and primarily focus on raw images, rarely encountered in real-world scenarios. To address these challenges, we propose PLADA (Pay Less Attention to Deceptive Artifacts), a novel framework designed to tackle the lack of paired data and the ineffective use of compressed images. PLADA consists of two core modules: Block Effect Eraser (B2E), which uses a dual-stage attention mechanism to handle block effects, and Open Data Aggregation (ODA), which processes both paired and unpaired data to improve detection. Extensive experiments across 26 datasets demonstrate that PLADA achieves a remarkable balance in deepfake detection, outperforming SoTA methods in detecting deepfakes on OSNs, even with limited paired data and compression. More importantly, this work introduces the ``block effect" as a critical factor in deepfake detection, providing a robust solution for open-world scenarios. Our code is available at https://github.com/ManyiLee/PLADA.
G-DexGrasp: Generalizable Dexterous Grasping Synthesis Via Part-Aware Prior Retrieval and Prior-Assisted Generation
Mar 25, 2025



Recent advances in dexterous grasping synthesis have demonstrated significant progress in producing reasonable and plausible grasps for many task purposes. But it remains challenging to generalize to unseen object categories and diverse task instructions. In this paper, we propose G-DexGrasp, a retrieval-augmented generation approach that can produce high-quality dexterous hand configurations for unseen object categories and language-based task instructions. The key is to retrieve generalizable grasping priors, including the fine-grained contact part and the affordance-related distribution of relevant grasping instances, for the following synthesis pipeline. Specifically, the fine-grained contact part and affordance act as generalizable guidance to infer reasonable grasping configurations for unseen objects with a generative model, while the relevant grasping distribution plays as regularization to guarantee the plausibility of synthesized grasps during the subsequent refinement optimization. Our comparison experiments validate the effectiveness of our key designs for generalization and demonstrate the remarkable performance against the existing approaches. Project page: https://g-dexgrasp.github.io/
SymbioSim: Human-in-the-loop Simulation Platform for Bidirectional Continuing Learning in Human-Robot Interaction
Feb 11, 2025The development of intelligent robots seeks to seamlessly integrate them into the human world, providing assistance and companionship in daily life and work, with the ultimate goal of achieving human-robot symbiosis. To realize this vision, robots must continuously learn and evolve through consistent interaction and collaboration with humans, while humans need to gradually develop an understanding of and trust in robots through shared experiences. However, training and testing algorithms directly on physical robots involve substantial costs and safety risks. Moreover, current robotic simulators fail to support real human participation, limiting their ability to provide authentic interaction experiences and gather valuable human feedback. In this paper, we introduce SymbioSim, a novel human-in-the-loop robotic simulation platform designed to enable the safe and efficient development, evaluation, and optimization of human-robot interactions. By leveraging a carefully designed system architecture and modules, SymbioSim delivers a natural and realistic interaction experience, facilitating bidirectional continuous learning and adaptation for both humans and robots. Extensive experiments and user studies demonstrate the platform's promising performance and highlight its potential to significantly advance research on human-robot symbiosis.
Unit Region Encoding: A Unified and Compact Geometry-aware Representation for Floorplan Applications
Jan 19, 2025We present the Unit Region Encoding of floorplans, which is a unified and compact geometry-aware encoding representation for various applications, ranging from interior space planning, floorplan metric learning to floorplan generation tasks. The floorplans are represented as the latent encodings on a set of boundary-adaptive unit region partition based on the clustering of the proposed geometry-aware density map. The latent encodings are extracted by a trained network (URE-Net) from the input dense density map and other available semantic maps. Compared to the over-segmented rasterized images and the room-level graph structures, our representation can be flexibly adapted to different applications with the sliced unit regions while achieving higher accuracy performance and better visual quality. We conduct a variety of experiments and compare to the state-of-the-art methods on the aforementioned applications to validate the superiority of our representation, as well as extensive ablation studies to demonstrate the effect of our slicing choices.
CLIP-based Point Cloud Classification via Point Cloud to Image Translation
Aug 07, 2024



Point cloud understanding is an inherently challenging problem because of the sparse and unordered structure of the point cloud in the 3D space. Recently, Contrastive Vision-Language Pre-training (CLIP) based point cloud classification model i.e. PointCLIP has added a new direction in the point cloud classification research domain. In this method, at first multi-view depth maps are extracted from the point cloud and passed through the CLIP visual encoder. To transfer the 3D knowledge to the network, a small network called an adapter is fine-tuned on top of the CLIP visual encoder. PointCLIP has two limitations. Firstly, the point cloud depth maps lack image information which is essential for tasks like classification and recognition. Secondly, the adapter only relies on the global representation of the multi-view features. Motivated by this observation, we propose a Pretrained Point Cloud to Image Translation Network (PPCITNet) that produces generalized colored images along with additional salient visual cues to the point cloud depth maps so that it can achieve promising performance on point cloud classification and understanding. In addition, we propose a novel viewpoint adapter that combines the view feature processed by each viewpoint as well as the global intertwined knowledge that exists across the multi-view features. The experimental results demonstrate the superior performance of the proposed model over existing state-of-the-art CLIP-based models on ModelNet10, ModelNet40, and ScanobjectNN datasets.
Learning based 2D Irregular Shape Packing
Sep 19, 20232D irregular shape packing is a necessary step to arrange UV patches of a 3D model within a texture atlas for memory-efficient appearance rendering in computer graphics. Being a joint, combinatorial decision-making problem involving all patch positions and orientations, this problem has well-known NP-hard complexity. Prior solutions either assume a heuristic packing order or modify the upstream mesh cut and UV mapping to simplify the problem, which either limits the packing ratio or incurs robustness or generality issues. Instead, we introduce a learning-assisted 2D irregular shape packing method that achieves a high packing quality with minimal requirements from the input. Our method iteratively selects and groups subsets of UV patches into near-rectangular super patches, essentially reducing the problem to bin-packing, based on which a joint optimization is employed to further improve the packing ratio. In order to efficiently deal with large problem instances with hundreds of patches, we train deep neural policies to predict nearly rectangular patch subsets and determine their relative poses, leading to linear time scaling with the number of patches. We demonstrate the effectiveness of our method on three datasets for UV packing, where our method achieves a higher packing ratio over several widely used baselines with competitive computational speed.
AffordPose: A Large-scale Dataset of Hand-Object Interactions with Affordance-driven Hand Pose
Sep 16, 2023
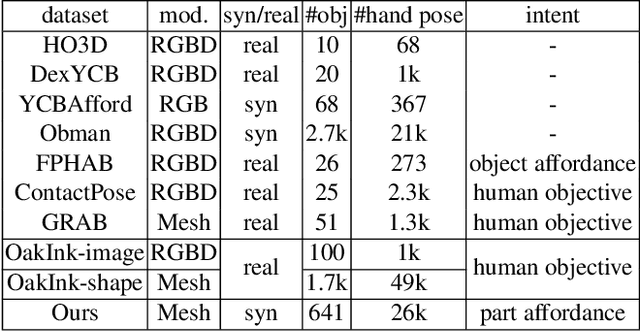


How human interact with objects depends on the functional roles of the target objects, which introduces the problem of affordance-aware hand-object interaction. It requires a large number of human demonstrations for the learning and understanding of plausible and appropriate hand-object interactions. In this work, we present AffordPose, a large-scale dataset of hand-object interactions with affordance-driven hand pose. We first annotate the specific part-level affordance labels for each object, e.g. twist, pull, handle-grasp, etc, instead of the general intents such as use or handover, to indicate the purpose and guide the localization of the hand-object interactions. The fine-grained hand-object interactions reveal the influence of hand-centered affordances on the detailed arrangement of the hand poses, yet also exhibit a certain degree of diversity. We collect a total of 26.7K hand-object interactions, each including the 3D object shape, the part-level affordance label, and the manually adjusted hand poses. The comprehensive data analysis shows the common characteristics and diversity of hand-object interactions per affordance via the parameter statistics and contacting computation. We also conduct experiments on the tasks of hand-object affordance understanding and affordance-oriented hand-object interaction generation, to validate the effectiveness of our dataset in learning the fine-grained hand-object interactions. Project page: https://github.com/GentlesJan/AffordPose.