 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Imitation to Discrimination: Progressive Curriculum Learning for Robust Web Navigation
Apr 14, 2026Text-based web agents offer computational efficiency for autonomous web navigation, yet developing robust agents remains challenging due to the noisy and heterogeneous nature of real-world HTML. Standard Supervised Fine-Tuning (SFT) approaches fail in two critical dimensions: they lack discrimination capabilities to reject plausible but incorrect elements in densely populated pages, and exhibit limited generalization to unseen website layouts. To address these challenges, we introduce the Triton dataset (590k instances) and a progressive training curriculum. Triton is constructed via Structural-Semantic Hard Negative Mining, which explicitly mines topologically similar distractors, and a Dual-Agent Consensus pipeline that synthesizes diverse cross-domain tasks with strict verification. Building upon this foundation, our progressive curriculum produces three models: Triton-SFT-32B for basic imitation, Triton-ORPO-32B for robust discrimination via Odds Ratio Preference Optimization, and Triton-GRPO-32B for long-horizon consistency through Group Relative Policy Optimization. Empirical evaluation on Mind2Web demonstrates that Triton-GRPO-32B achieves state-of-the-art performance among open-source models with 58.7% Step Success Rate, surpassing GPT-4.5 (42.4%) and Claude-4.5 (41.4%) by over 16%, validating that specialized data curriculum outweighs raw parameter scale for web navigation.
CoCoDiff: Correspondence-Consistent Diffusion Model for Fine-grained Style Transfer
Feb 16, 2026Transferring visual style between images while preserving semantic correspondence between similar objects remains a central challenge in computer vision. While existing methods have made great strides, most of them operate at global level but overlook region-wise and even pixel-wise semantic correspondence. To address this, we propose CoCoDiff, a novel training-free and low-cost style transfer framework that leverages pretrained latent diffusion models to achieve fine-grained, semantically consistent stylization. We identify that correspondence cues within generative diffusion models are under-explored and that content consistency across semantically matched regions is often neglected. CoCoDiff introduces a pixel-wise semantic correspondence module that mines intermediate diffusion features to construct a dense alignment map between content and style images. Furthermore, a cycle-consistency module then enforces structural and perceptual alignment across iterations, yielding object and region level stylization that preserves geometry and detail. Despite requiring no additional training or supervision, CoCoDiff delivers state-of-the-art visual quality and strong quantitative results, outperforming methods that rely on extra training or annotations.
Scaling Up AI-Generated Image Detection via Generator-Aware Prototypes
Dec 15, 2025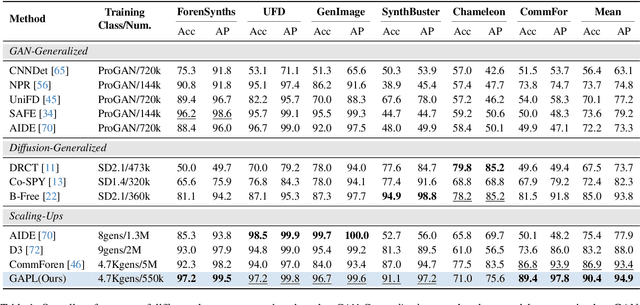
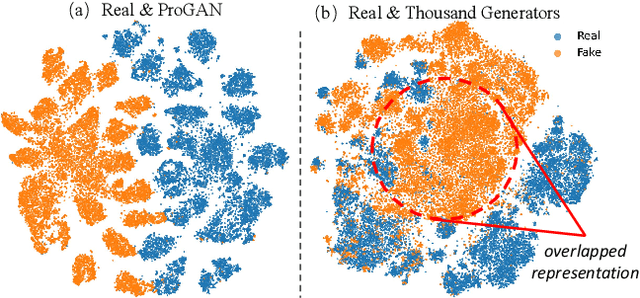
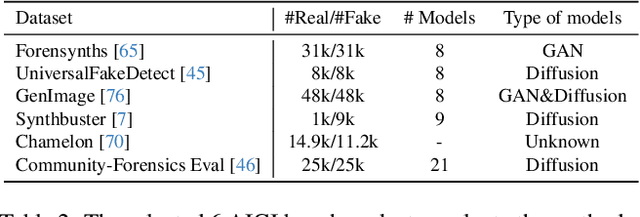
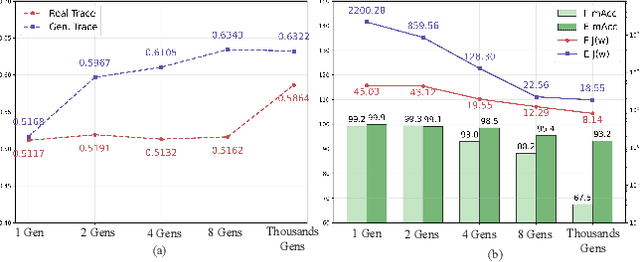
The pursuit of a universal AI-generated image (AIGI) detector often relies on aggregating data from numerous generators to improve generalization. However, this paper identifies a paradoxical phenomenon we term the Benefit then Conflict dilemma, where detector performance stagnates and eventually degrades as source diversity expands. Our systematic analysis, diagnoses this failure by identifying two core issues: severe data-level heterogeneity, which causes the feature distributions of real and synthetic images to increasingly overlap, and a critical model-level bottleneck from fixed, pretrained encoders that cannot adapt to the rising complexity. To address these challenges, we propose Generator-Aware Prototype Learning (GAPL), a framework that constrain representation with a structured learning paradigm. GAPL learns a compact set of canonical forgery prototypes to create a unified, low-variance feature space, effectively countering data heterogeneity.To resolve the model bottleneck, it employs a two-stage training scheme with Low-Rank Adaptation, enhancing its discriminative power while preserving valuable pretrained knowledge. This approach establishes a more robust and generalizable decision boundary. Through extensive experiments, we demonstrate that GAPL achieves state-of-the-art performance, showing superior detection accuracy across a wide variety of GAN and diffusion-based generators. Code is available at https://github.com/UltraCapture/GAPL
Taming Generative Synthetic Data for X-ray Prohibited Item Detection
Nov 19, 2025


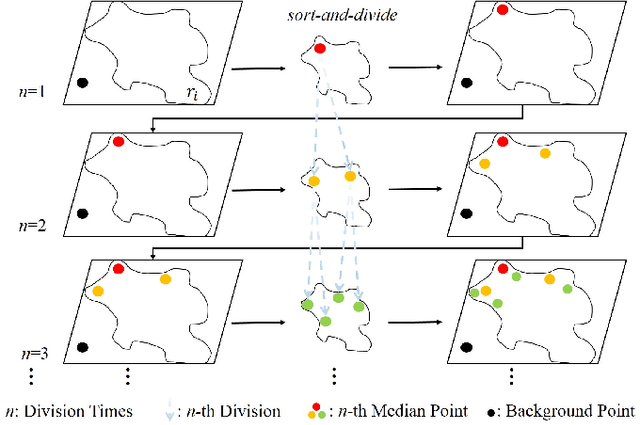
Training prohibited item detection models requires a large amount of X-ray security images, but collecting and annotating these images is time-consuming and laborious. To address data insufficiency, X-ray security image synthesis methods composite images to scale up datasets. However, previous methods primarily follow a two-stage pipeline, where they implement labor-intensive foreground extraction in the first stage and then composite images in the second stage. Such a pipeline introduces inevitable extra labor cost and is not efficient. In this paper, we propose a one-stage X-ray security image synthesis pipeline (Xsyn) based on text-to-image generation, which incorporates two effective strategies to improve the usability of synthetic images. The Cross-Attention Refinement (CAR) strategy leverages the cross-attention map from the diffusion model to refine the bounding box annotation. The Background Occlusion Modeling (BOM) strategy explicitly models background occlusion in the latent space to enhance imaging complexity. To the best of our knowledge, compared with previous methods, Xsyn is the first to achieve high-quality X-ray security image synthesis without extra labor cost. Experiments demonstrate that our method outperforms all previous methods with 1.2% mAP improvement, and the synthetic images generated by our method are beneficial to improve prohibited item detection performance across various X-ray security datasets and detectors. Code is available at https://github.com/pILLOW-1/Xsyn/.
When Deepfakes Look Real: Detecting AI-Generated Faces with Unlabeled Data due to Annotation Challenges
Aug 12, 2025Existing deepfake detection methods heavily depend on labeled training data. However, as AI-generated content becomes increasingly realistic, even \textbf{human annotators struggle to distinguish} between deepfakes and authentic images. This makes the labeling process both time-consuming and less reliable. Specifically, there is a growing demand for approaches that can effectively utilize large-scale unlabeled data from online social networks. Unlike typical unsupervised learning tasks, where categories are distinct, AI-generated faces closely mimic real image distributions and share strong similarities, causing performance drop in conventional strategies. In this paper, we introduce the Dual-Path Guidance Network (DPGNet), to tackle two key challenges: (1) bridging the domain gap between faces from different generation models, and (2) utilizing unlabeled image samples. The method features two core modules: text-guided cross-domain alignment, which uses learnable prompts to unify visual and textual embeddings into a domain-invariant feature space, and curriculum-driven pseudo label generation, which dynamically exploit more informative unlabeled samples. To prevent catastrophic forgetting, we also facilitate bridging between domains via cross-domain knowledge distillation. Extensive experiments on \textbf{11 popular datasets}, show that DPGNet outperforms SoTA approaches by \textbf{6.3\%}, highlighting its effectiveness in leveraging unlabeled data to address the annotation challenges posed by the increasing realism of deepfakes.
Pay Less Attention to Deceptive Artifacts: Robust Detection of Compressed Deepfakes on Online Social Networks
Jun 25, 2025



With the rapid advancement of deep learning, particularly through generative adversarial networks (GANs) and diffusion models (DMs), AI-generated images, or ``deepfakes", have become nearly indistinguishable from real ones. These images are widely shared across Online Social Networks (OSNs), raising concerns about their misuse. Existing deepfake detection methods overlook the ``block effects" introduced by compression in OSNs, which obscure deepfake artifacts, and primarily focus on raw images, rarely encountered in real-world scenarios. To address these challenges, we propose PLADA (Pay Less Attention to Deceptive Artifacts), a novel framework designed to tackle the lack of paired data and the ineffective use of compressed images. PLADA consists of two core modules: Block Effect Eraser (B2E), which uses a dual-stage attention mechanism to handle block effects, and Open Data Aggregation (ODA), which processes both paired and unpaired data to improve detection. Extensive experiments across 26 datasets demonstrate that PLADA achieves a remarkable balance in deepfake detection, outperforming SoTA methods in detecting deepfakes on OSNs, even with limited paired data and compression. More importantly, this work introduces the ``block effect" as a critical factor in deepfake detection, providing a robust solution for open-world scenarios. Our code is available at https://github.com/ManyiLee/PLADA.
Unsupervised Region-Based Image Editing of Denoising Diffusion Models
Dec 17, 2024



Although diffusion models have achieved remarkable success in the field of image generation, their latent space remains under-explored. Current methods for identifying semantics within latent space often rely on external supervision, such as textual information and segmentation masks. In this paper, we propose a method to identify semantic attributes in the latent space of pre-trained diffusion models without any further training. By projecting the Jacobian of the targeted semantic region into a low-dimensional subspace which is orthogonal to the non-masked regions, our approach facilitates precise semantic discovery and control over local masked areas, eliminating the need for annotations. We conducted extensive experiments across multiple datasets and various architectures of diffusion models, achieving state-of-the-art performance. In particular, for some specific face attributes, the performance of our proposed method even surpasses that of supervised approaches, demonstrating its superior ability in editing local image properties.
MPQ-DM: Mixed Precision Quantization for Extremely Low Bit Diffusion Models
Dec 16, 2024



Diffusion models have received wide attention in generation tasks. However, the expensive computation cost prevents the application of diffusion models in resource-constrained scenarios. Quantization emerges as a practical solution that significantly saves storage and computation by reducing the bit-width of parameters. However, the existing quantization methods for diffusion models still cause severe degradation in performance, especially under extremely low bit-widths (2-4 bit). The primary decrease in performance comes from the significant discretization of activation values at low bit quantization. Too few activation candidates are unfriendly for outlier significant weight channel quantization, and the discretized features prevent stable learning over different time steps of the diffusion model. This paper presents MPQ-DM, a Mixed-Precision Quantization method for Diffusion Models. The proposed MPQ-DM mainly relies on two techniques:(1) To mitigate the quantization error caused by outlier severe weight channels, we propose an Outlier-Driven Mixed Quantization (OMQ) technique that uses $Kurtosis$ to quantify outlier salient channels and apply optimized intra-layer mixed-precision bit-width allocation to recover accuracy performance within target efficiency.(2) To robustly learn representations crossing time steps, we construct a Time-Smoothed Relation Distillation (TRD) scheme between the quantized diffusion model and its full-precision counterpart, transferring discrete and continuous latent to a unified relation space to reduce the representation inconsistency. Comprehensive experiments demonstrate that MPQ-DM achieves significant accuracy gains under extremely low bit-widths compared with SOTA quantization methods. MPQ-DM achieves a 58\% FID decrease under W2A4 setting compared with baseline, while all other methods even collapse.
Behavior Backdoor for Deep Learning Models
Dec 02, 2024



The various post-processing methods for deep-learning-based models, such as quantification, pruning, and fine-tuning, play an increasingly important role in artificial intelligence technology, with pre-train large models as one of the main development directions. However, this popular series of post-processing behaviors targeting pre-training deep models has become a breeding ground for new adversarial security issues. In this study, we take the first step towards ``behavioral backdoor'' attack, which is defined as a behavior-triggered backdoor model training procedure, to reveal a new paradigm of backdoor attacks. In practice, we propose the first pipeline of implementing behavior backdoor, i.e., the Quantification Backdoor (QB) attack, upon exploiting model quantification method as the set trigger. Specifically, to adapt the optimization goal of behavior backdoor, we introduce the behavior-driven backdoor object optimizing method by a bi-target behavior backdoor training loss, thus we could guide the poisoned model optimization direction. To update the parameters across multiple models, we adopt the address-shared backdoor model training, thereby the gradient information could be utilized for multimodel collaborative optimization. Extensive experiments have been conducted on different models, datasets, and tasks, demonstrating the effectiveness of this novel backdoor attack and its potential application threats.
BGM: Background Mixup for X-ray Prohibited Items Detection
Nov 30, 2024Prohibited item detection is crucial for ensuring public safety, yet current X-ray image-based detection methods often lack comprehensive data-driven exploration. This paper introduces a novel data augmentation approach tailored for prohibited item detection, leveraging unique characteristics inherent to X-ray imagery. Our method is motivated by observations of physical properties including: 1) X-ray Transmission Imagery: Unlike reflected light images, transmitted X-ray pixels represent composite information from multiple materials along the imaging path. 2) Material-based Pseudo-coloring: Pseudo-color rendering in X-ray images correlates directly with material properties, aiding in material distinction. Building on a novel perspective from physical properties, we propose a simple yet effective X-ray image augmentation technique, Background Mixup (BGM), for prohibited item detection in security screening contexts. The essence is the rich background simulation of X-ray images to induce the model to increase its attention to the foreground. The approach introduces 1) contour information of baggage and 2) variation of material information into the original image by Mixup at patch level. Background Mixup is plug-and-play, parameter-free, highly generalizable and provides an effective solution to the limitations of classical visual augmentations in non-reflected light imagery. When implemented with different high-performance detectors, our augmentation method consistently boosts performance across diverse X-ray datasets from various devices and environments. Extensive experimental results demonstrate that our approach surpasses strong baselines while maintaining similar training resources.