 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2P-CLIP: Injecting Category Common Prompt in CLIP to Enhance Generalization in Deepfake Detection
Aug 19, 2024



This work focuses on AIGC detection to develop universal detectors capable of identifying various types of forgery images. Recent studies have found large pre-trained models, such as CLIP, are effective for generalizable deepfake detection along with linear classifiers. However, two critical issues remain unresolved: 1) understanding why CLIP features are effective on deepfake detection through a linear classifier; and 2) exploring the detection potential of CLIP. In this study, we delve into the underlying mechanisms of CLIP's detection capabilities by decoding its detection features into text and performing word frequency analysis. Our finding indicates that CLIP detects deepfakes by recognizing similar concepts (Fig. \ref{fig:fig1} a). Building on this insight, we introduce Category Common Prompt CLIP, called C2P-CLIP, which integrates the category common prompt into the text encoder to inject category-related concepts into the image encoder, thereby enhancing detection performance (Fig. \ref{fig:fig1} b). Our method achieves a 12.41\% improvement in detection accuracy compared to the original CLIP, without introducing additional parameters during testing. Comprehensive experiments conducted on two widely-used datasets, encompassing 20 generation models, validate the efficacy of the proposed method, demonstrating state-of-the-art performance. The code is available at \url{https://github.com/chuangchuangtan/C2P-CLIP-DeepfakeDetection}
Frequency-Aware Deepfake Detection: Improving Generalizability through Frequency Space Learning
Mar 12, 2024



This research addresses the challenge of developing a universal deepfake detector that can effectively identify unseen deepfake images despite limited training data. Existing frequency-based paradigms have relied on frequency-level artifacts introduced during the up-sampling in GAN pipelines to detect forgeries. However, the rapid advancements in synthesis technology have led to specific artifacts for each generation model. Consequently, these detectors have exhibited a lack of proficiency in learning the frequency domain and tend to overfit to the artifacts present in the training data, leading to suboptimal performance on unseen sources. To address this issue, we introduce a novel frequency-aware approach called FreqNet, centered around frequency domain learning, specifically designed to enhance the generalizability of deepfake detectors. Our method forces the detector to continuously focus on high-frequency information, exploiting high-frequency representation of features across spatial and channel dimensions. Additionally, we incorporate a straightforward frequency domain learning module to learn source-agnostic features. It involves convolutional layers applied to both the phase spectrum and amplitude spectrum between the Fast Fourier Transform (FFT) and Inverse Fast Fourier Transform (iFFT). Extensive experimentation involving 17 GANs demonstrates the effectiveness of our proposed method, showcasing state-of-the-art performance (+9.8\%) while requiring fewer parameters. The code is available at {\cred \url{https://github.com/chuangchuangtan/FreqNet-DeepfakeDetection}}.
Rethinking the Up-Sampling Operations in CNN-based Generative Network for Generalizable Deepfake Detection
Dec 20, 2023Recently, the proliferation of highly realistic synthetic images, facilitated through a variety of GANs and Diffusions, has significantly heightened the susceptibility to misuse. While the primary focus of deepfake detection has traditionally centered on the design of detection algorithms, an investigative inquiry into the generator architectures has remained conspicuously absent in recent years. This paper contributes to this lacuna by rethinking the architectures of CNN-based generators, thereby establishing a generalized representation of synthetic artifacts. Our findings illuminate that the up-sampling operator can, beyond frequency-based artifacts, produce generalized forgery artifacts. In particular, the local interdependence among image pixels caused by upsampling operators is significantly demonstrated in synthetic images generated by GAN or diffusion. Building upon this observation, we introduce the concept of Neighboring Pixel Relationships(NPR) as a means to capture and characterize the generalized structural artifacts stemming from up-sampling operations. A comprehensive analysis is conducted on an open-world dataset, comprising samples generated by \tft{28 distinct generative models}. This analysis culminates in the establishment of a novel state-of-the-art performance, showcasing a remarkable \tft{11.6\%} improvement over existing methods. The code is available at https://github.com/chuangchuangtan/NPR-DeepfakeDetection.
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020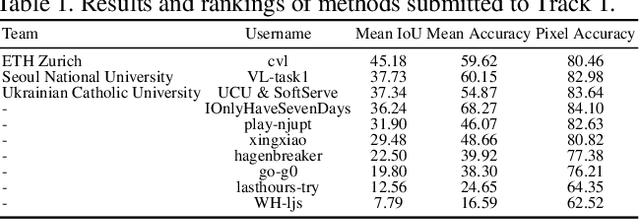
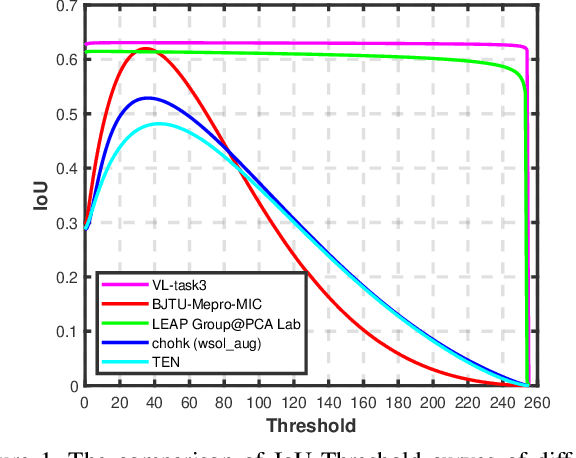

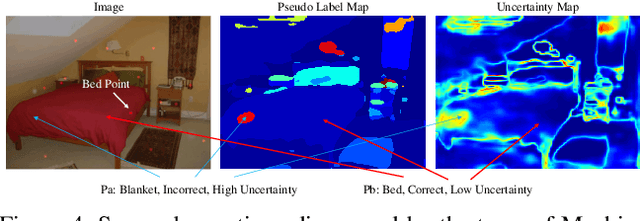
Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io