 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning under Retain-Forget Entanglement
Mar 27, 2026Forgetting a subset in machine unlearning is rarely an isolated task. Often, retained samples that are closely related to the forget set can be unintentionally affected, particularly when they share correlated features from pretraining or exhibit strong semantic similarities. To address this challenge, we propose a novel two-phase optimization framework specifically designed to handle such retai-forget entanglements. In the first phase, an augmented Lagrangian method increases the loss on the forget set while preserving accuracy on less-related retained samples. The second phase applies a gradient projection step, regularized by the Wasserstein-2 distance, to mitigate performance degradation on semantically related retained samples without compromising the unlearning objective. We validate our approach through comprehensive experiments on multiple unlearning tasks, standard benchmark datasets, and diverse neural architectures, demonstrating that it achieves effective and reliable unlearning while outperforming existing baselines in both accuracy retention and removal fidelity.
PROBE: Diagnosing Residual Concept Capacity in Erased Text-to-Video Diffusion Models
Mar 23, 2026Concept erasure techniques for text-to-video (T2V) diffusion models report substantial suppression of sensitive content, yet current evaluation is limited to checking whether the target concept is absent from generated frames, treating output-level suppression as evidence of representational removal. We introduce PROBE, a diagnostic protocol that quantifies the \textit{reactivation potential} of erased concepts in T2V models. With all model parameters frozen, PROBE optimizes a lightweight pseudo-token embedding through a denoising reconstruction objective combined with a novel latent alignment constraint that anchors recovery to the spatiotemporal structure of the original concept. We make three contributions: (1) a multi-level evaluation framework spanning classifier-based detection, semantic similarity, temporal reactivation analysis, and human validation; (2) systematic experiments across three T2V architectures, three concept categories, and three erasure strategies revealing that all tested methods leave measurable residual capacity whose robustness correlates with intervention depth; and (3) the identification of temporal re-emergence, a video-specific failure mode where suppressed concepts progressively resurface across frames, invisible to frame-level metrics. These findings suggest that current erasure methods achieve output-level suppression rather than representational removal. We release our protocol to support reproducible safety auditing. Our code is available at https://github.com/YiweiXie/PRObingBasedEvaluation.
High Fidelity Textual User Representation over Heterogeneous Sources via Reinforcement Learning
Feb 07, 2026Effective personalization on large-scale job platforms requires modeling members based on heterogeneous textual sources, including profiles, professional data, and search activity logs. As recommender systems increasingly adopt Large Language Models (LLMs), creating unified, interpretable, and concise representations from heterogeneous sources becomes critical, especially for latency-sensitive online environments. In this work, we propose a novel Reinforcement Learning (RL) framework to synthesize a unified textual representation for each member. Our approach leverages implicit user engagement signals (e.g., clicks, applies) as the primary reward to distill salient information. Additionally, the framework is complemented by rule-based rewards that enforce formatting and length constraints. Extensive offline experiments across multiple LinkedIn products, one of the world's largest job platforms, demonstrate significant improvements in key downstream business metrics. This work provides a practical, labeling-free, and scalable solution for constructing interpretable user representations that are directly compatible with LLM-based systems.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Automated anatomy-based post-processing reduces false positives and improved interpretability of deep learning intracranial aneurysm detection
Jul 01, 2025Introduction: Deep learning (DL) models can help detect intracranial aneurysms on CTA, but high false positive (FP) rates remain a barrier to clinical translation, despite improvement in model architectures and strategies like detection threshold tuning. We employed an automated, anatomy-based, heuristic-learning hybrid artery-vein segmentation post-processing method to further reduce FPs. Methods: Two DL models, CPM-Net and a deformable 3D convolutional neural network-transformer hybrid (3D-CNN-TR), were trained with 1,186 open-source CTAs (1,373 annotated aneurysms), and evaluated with 143 held-out private CTAs (218 annotated aneurysms). Brain, artery, vein, and cavernous venous sinus (CVS) segmentation masks were applied to remove possible FPs in the DL outputs that overlapped with: (1) brain mask; (2) vein mask; (3) vein more than artery masks; (4) brain plus vein mask; (5) brain plus vein more than artery masks. Results: CPM-Net yielded 139 true-positives (TP); 79 false-negative (FN); 126 FP. 3D-CNN-TR yielded 179 TP; 39 FN; 182 FP. FPs were commonly extracranial (CPM-Net 27.3%; 3D-CNN-TR 42.3%), venous (CPM-Net 56.3%; 3D-CNN-TR 29.1%), arterial (CPM-Net 11.9%; 3D-CNN-TR 53.3%), and non-vascular (CPM-Net 25.4%; 3D-CNN-TR 9.3%) structures. Method 5 performed best, reducing CPM-Net FP by 70.6% (89/126) and 3D-CNN-TR FP by 51.6% (94/182), without reducing TP, lowering the FP/case rate from 0.88 to 0.26 for CPM-NET, and from 1.27 to 0.62 for the 3D-CNN-TR. Conclusion: Anatomy-based, interpretable post-processing can improve DL-based aneurysm detection model performance. More broadly, automated, domain-informed, hybrid heuristic-learning processing holds promise for improving the performance and clinical acceptance of aneurysm detection models.
Fed-HeLLo: Efficient Federated Foundation Model Fine-Tuning with Heterogeneous LoRA Allocation
Jun 13, 2025Federated Learning has recently been utilized to collaboratively fine-tune foundation models across multiple clients. Notably, federated low-rank adaptation LoRA-based fine-tuning methods have recently gained attention, which allows clients to fine-tune FMs with a small portion of trainable parameters locally. However, most existing methods do not account for the heterogeneous resources of clients or lack an effective local training strategy to maximize global fine-tuning performance under limited resources. In this work, we propose Fed-HeLLo, a novel federated LoRA-based fine-tuning framework that enables clients to collaboratively fine-tune an FM with different local trainable LoRA layers. To ensure its effectiveness, we develop several heterogeneous LoRA allocation (HLA) strategies that adaptively allocate local trainable LoRA layers based on clients' resource capabilities and the layer importance. Specifically, based on the dynamic layer importance, we design a Fisher Information Matrix score-based HLA that leverages dynamic gradient norm information. To better stabilize the training process, we consider the intrinsic importance of LoRA layers and design a Geometrically-Defined HLA strategy. It shapes the collective distribution of trainable LoRA layers into specific geometric patterns, such as Triangle, Inverted Triangle, Bottleneck, and Uniform. Moreover, we extend GD-HLA into a randomized version, named Randomized Geometrically-Defined HLA, for enhanced model accuracy with randomness. By co-designing the proposed HLA strategies, we incorporate both the dynamic and intrinsic layer importance into the design of our HLA strategy. We evaluate our approach on five datasets under diverse federated LoRA fine-tuning settings, covering three levels of data distribution from IID to extreme Non-IID. Results show that Fed-HeLLo with HLA strategies is both effective and efficient.
Erasing Concepts, Steering Generations: A Comprehensive Survey of Concept Suppression
May 26, 2025Text-to-Image (T2I) models have demonstrated impressive capabilities in generating high-quality and diverse visual content from natural language prompts. However, uncontrolled reproduction of sensitive, copyrighted, or harmful imagery poses serious ethical, legal, and safety challenges. To address these concerns, the concept erasure paradigm has emerged as a promising direction, enabling the selective removal of specific semantic concepts from generative models while preserving their overall utility. This survey provides a comprehensive overview and in-depth synthesis of concept erasure techniques in T2I diffusion models. We systematically categorize existing approaches along three key dimensions: intervention level, which identifies specific model components targeted for concept removal; optimization structure, referring to the algorithmic strategies employed to achieve suppression; and semantic scope, concerning the complexity and nature of the concepts addressed. This multi-dimensional taxonomy enables clear, structured comparisons across diverse methodologies, highlighting fundamental trade-offs between erasure specificity, generalization, and computational complexity. We further discuss current evaluation benchmarks, standardized metrics, and practical datasets, emphasizing gaps that limit comprehensive assessment, particularly regarding robustness and practical effectiveness. Finally, we outline major challenges and promising future directions, including disentanglement of concept representations, adaptive and incremental erasure strategies, adversarial robustness, and new generative architectures. This survey aims to guide researchers toward safer, more ethically aligned generative models, providing foundational knowledge and actionable recommendations to advance responsible development in generative AI.
MAGIC: Motion-Aware Generative Inference via Confidence-Guided LLM
May 22, 2025Recent advances in static 3D generation have intensified the demand for physically consistent dynamic 3D content. However, existing video generation models, including diffusion-based methods, often prioritize visual realism while neglecting physical plausibility, resulting in implausible object dynamics. Prior approaches for physics-aware dynamic generation typically rely on large-scale annotated datasets or extensive model fine-tuning, which imposes significant computational and data collection burdens and limits scalability across scenarios. To address these challenges, we present MAGIC, a training-free framework for single-image physical property inference and dynamic generation, integrating pretrained image-to-video diffusion models with iterative LLM-based reasoning. Our framework generates motion-rich videos from a static image and closes the visual-to-physical gap through a confidence-driven LLM feedback loop that adaptively steers the diffusion model toward physics-relevant motion. To translate visual dynamics into controllable physical behavior, we further introduce a differentiable MPM simulator operating directly on 3D Gaussians reconstructed from the single image, enabling physically grounded, simulation-ready outputs without any supervision or model tuning. Experiments show that MAGIC outperforms existing physics-aware generative methods in inference accuracy and achieves greater temporal coherence than state-of-the-art video diffusion models.
Erased or Dormant? Rethinking Concept Erasure Through Reversibility
May 22, 2025To what extent does concept erasure eliminate generative capacity in diffusion models? While prior evaluations have primarily focused on measuring concept suppression under specific textual prompts, we explore a complementary and fundamental question: do current concept erasure techniques genuinely remove the ability to generate targeted concepts, or do they merely achieve superficial, prompt-specific suppression? We systematically evaluate the robustness and reversibility of two representative concept erasure methods, Unified Concept Editing and Erased Stable Diffusion, by probing their ability to eliminate targeted generative behaviors in text-to-image models. These methods attempt to suppress undesired semantic concepts by modifying internal model parameters, either through targeted attention edits or model-level fine-tuning strategies. To rigorously assess whether these techniques truly erase generative capacity, we propose an instance-level evaluation strategy that employs lightweight fine-tuning to explicitly test the reactivation potential of erased concepts. Through quantitative metrics and qualitative analyses, we show that erased concepts often reemerge with substantial visual fidelity after minimal adaptation, indicating that current methods suppress latent generative representations without fully eliminating them. Our findings reveal critical limitations in existing concept erasure approaches and highlight the need for deeper, representation-level interventions and more rigorous evaluation standards to ensure genuine, irreversible removal of concepts from generative models.
Grounding Creativity in Physics: A Brief Survey of Physical Priors in AIGC
Feb 10, 2025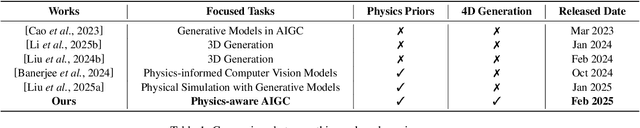
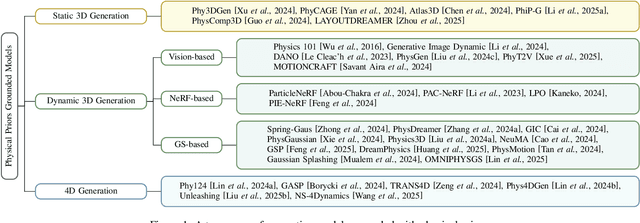

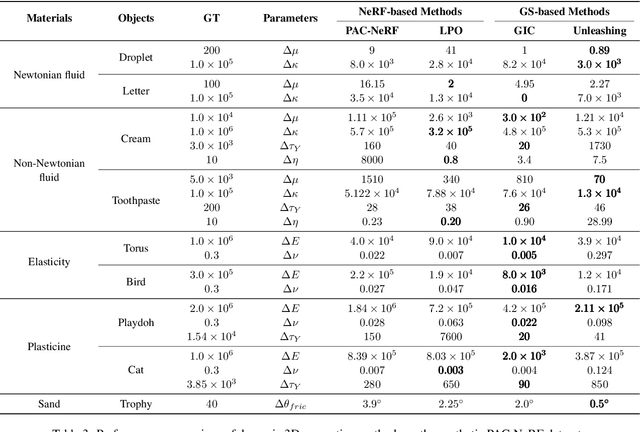
Recent advancements in AI-generated content have significantly improved the realism of 3D and 4D generation. However, most existing methods prioritize appearance consistency while neglecting underlying physical principles, leading to artifacts such as unrealistic deformations, unstable dynamics, and implausible objects interactions. Incorporating physics priors into generative models has become a crucial research direction to enhance structural integrity and motion realism. This survey provides a review of physics-aware generative methods, systematically analyzing how physical constraints are integrated into 3D and 4D generation. First, we examine recent works in incorporating physical priors into static and dynamic 3D generation, categorizing methods based on representation types, including vision-based, NeRF-based, and Gaussian Splatting-based approaches. Second, we explore emerging techniques in 4D generation, focusing on methods that model temporal dynamics with physical simulations. Finally, we conduct a comparative analysis of major methods, highlighting their strengths, limitations, and suitability for different materials and motion dynamics. By presenting an in-depth analysis of physics-grounded AIGC, this survey aims to bridge the gap between generative models and physical realism, providing insights that inspire future research in physically consistent content generation.