 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust automatic brain vessel segmentation in 3D CTA scans using dynamic 4D-CTA data
Jan 30, 2026In this study, we develop a novel methodology for annotating the brain vasculature using dynamic 4D-CTA head scans. By using multiple time points from dynamic CTA acquisitions, we subtract bone and soft tissue to enhance the visualization of arteries and veins, reducing the effort required to obtain manual annotations of brain vessels. We then train deep learning models on our ground truth annotations by using the same segmentation for multiple phases from the dynamic 4D-CTA collection, effectively enlarging our dataset by 4 to 5 times and inducing robustness to contrast phases. In total, our dataset comprises 110 training images from 25 patients and 165 test images from 14 patients. In comparison with two similarly-sized datasets for CTA-based brain vessel segmentation, a nnUNet model trained on our dataset can achieve significantly better segmentations across all vascular regions, with an average mDC of 0.846 for arteries and 0.957 for veins in the TopBrain dataset. Furthermore, metrics such as average directed Hausdorff distance (adHD) and topology sensitivity (tSens) reflected similar trends: using our dataset resulted in low error margins (aDHD of 0.304 mm for arteries and 0.078 for veins) and high sensitivity (tSens of 0.877 for arteries and 0.974 for veins), indicating excellent accuracy in capturing vessel morphology. Our code and model weights are available online: https://github.com/alceballosa/robust-vessel-segmentation
Automated anatomy-based post-processing reduces false positives and improved interpretability of deep learning intracranial aneurysm detection
Jul 01, 2025Introduction: Deep learning (DL) models can help detect intracranial aneurysms on CTA, but high false positive (FP) rates remain a barrier to clinical translation, despite improvement in model architectures and strategies like detection threshold tuning. We employed an automated, anatomy-based, heuristic-learning hybrid artery-vein segmentation post-processing method to further reduce FPs. Methods: Two DL models, CPM-Net and a deformable 3D convolutional neural network-transformer hybrid (3D-CNN-TR), were trained with 1,186 open-source CTAs (1,373 annotated aneurysms), and evaluated with 143 held-out private CTAs (218 annotated aneurysms). Brain, artery, vein, and cavernous venous sinus (CVS) segmentation masks were applied to remove possible FPs in the DL outputs that overlapped with: (1) brain mask; (2) vein mask; (3) vein more than artery masks; (4) brain plus vein mask; (5) brain plus vein more than artery masks. Results: CPM-Net yielded 139 true-positives (TP); 79 false-negative (FN); 126 FP. 3D-CNN-TR yielded 179 TP; 39 FN; 182 FP. FPs were commonly extracranial (CPM-Net 27.3%; 3D-CNN-TR 42.3%), venous (CPM-Net 56.3%; 3D-CNN-TR 29.1%), arterial (CPM-Net 11.9%; 3D-CNN-TR 53.3%), and non-vascular (CPM-Net 25.4%; 3D-CNN-TR 9.3%) structures. Method 5 performed best, reducing CPM-Net FP by 70.6% (89/126) and 3D-CNN-TR FP by 51.6% (94/182), without reducing TP, lowering the FP/case rate from 0.88 to 0.26 for CPM-NET, and from 1.27 to 0.62 for the 3D-CNN-TR. Conclusion: Anatomy-based, interpretable post-processing can improve DL-based aneurysm detection model performance. More broadly, automated, domain-informed, hybrid heuristic-learning processing holds promise for improving the performance and clinical acceptance of aneurysm detection models.
Anatomically-guided masked autoencoder pre-training for aneurysm detection
Feb 28, 2025Intracranial aneurysms are a major cause of morbidity and mortality worldwide, and detecting them manually is a complex, time-consuming task. Albeit automated solutions are desirable, the limited availability of training data makes it difficult to develop such solutions using typical supervised learning frameworks. In this work, we propose a novel pre-training strategy using more widely available unannotated head CT scan data to pre-train a 3D Vision Transformer model prior to fine-tuning for the aneurysm detection task. Specifically, we modify masked auto-encoder (MAE) pre-training in the following ways: we use a factorized self-attention mechanism to make 3D attention computationally viable, we restrict the masked patches to areas near arteries to focus on areas where aneurysms are likely to occur, and we reconstruct not only CT scan intensity values but also artery distance maps, which describe the distance between each voxel and the closest artery, thereby enhancing the backbone's learned representations. Compared with SOTA aneurysm detection models, our approach gains +4-8% absolute Sensitivity at a false positive rate of 0.5. Code and weights will be released.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
A Causal And-Or Graph Model for Visibility Fluent Reasoning in Tracking Interacting Objects
Mar 29, 2018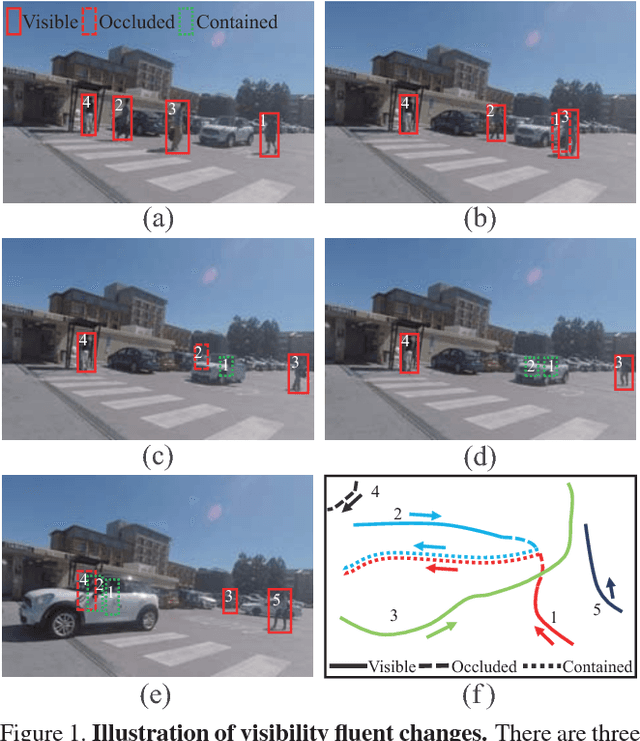
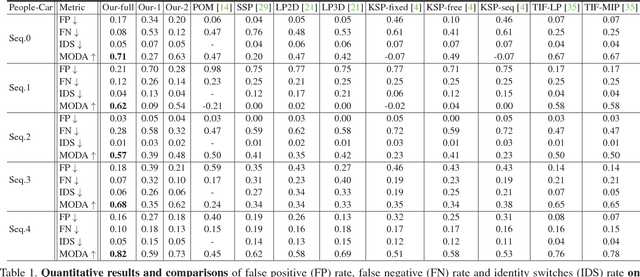
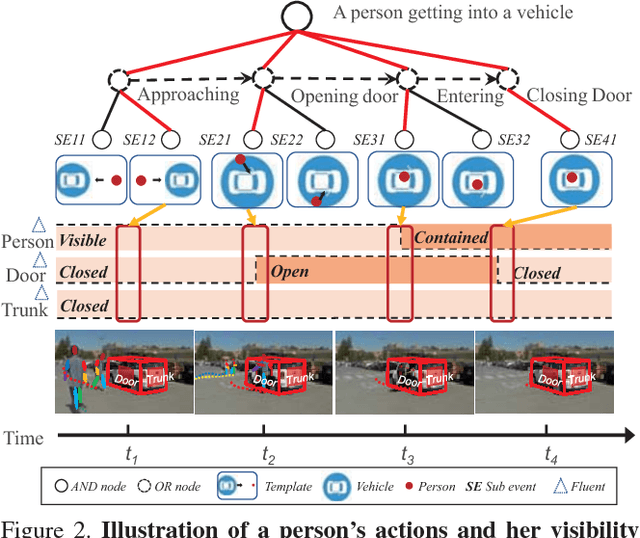
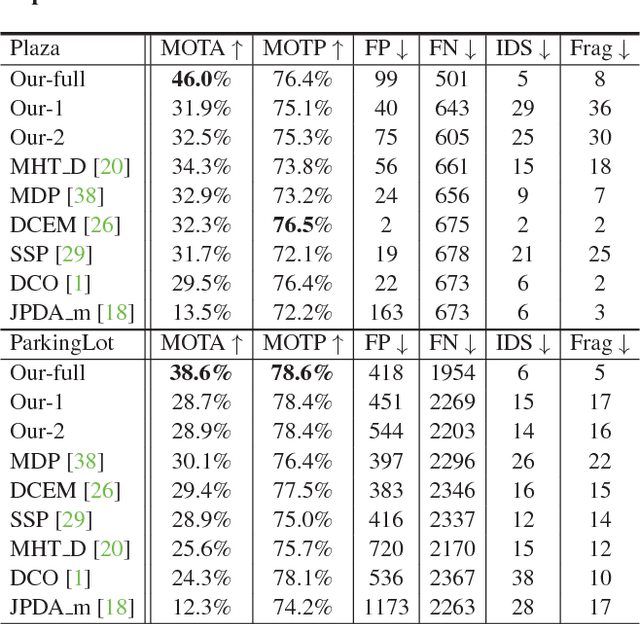
Tracking humans that are interacting with the other subjects or environment remains unsolved in visual tracking, because the visibility of the human of interests in videos is unknown and might vary over time. In particular, it is still difficult for state-of-the-art human trackers to recover complete human trajectories in crowded scenes with frequent human interactions. In this work, we consider the visibility status of a subject as a fluent variable, whose change is mostly attributed to the subject's interaction with the surrounding, e.g., crossing behind another object, entering a building, or getting into a vehicle, etc. We introduce a Causal And-Or Graph (C-AOG) to represent the causal-effect relations between an object's visibility fluent and its activities, and develop a probabilistic graph model to jointly reason the visibility fluent change (e.g., from visible to invisible) and track humans in videos. We formulate this joint task as an iterative search of a feasible causal graph structure that enables fast search algorithm, e.g., dynamic programming method. We apply the proposed method on challenging video sequences to evaluate its capabilities of estimating visibility fluent changes of subjects and tracking subjects of interests over time. Results with comparisons demonstrate that our method outperforms the alternative trackers and can recover complete trajectories of humans in complicated scenarios with frequent human interactions.