 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Tencent Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation
Nov 05, 2024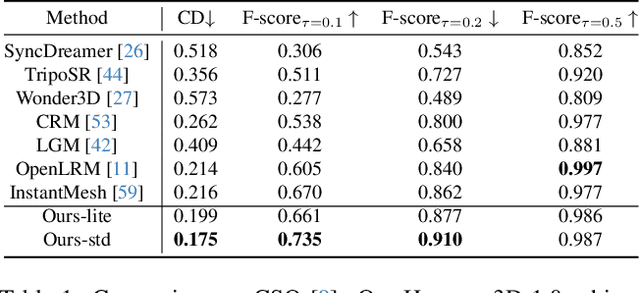

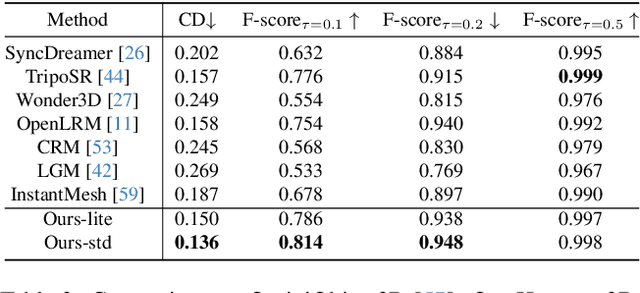

While 3D generative models have greatly improved artists' workflows, the existing diffusion models for 3D generation suffer from slow generation and poor generalization. To address this issue, we propose a two-stage approach named Hunyuan3D-1.0 including a lite version and a standard version, that both support text- and image-conditioned generation. In the first stage, we employ a multi-view diffusion model that efficiently generates multi-view RGB in approximately 4 seconds. These multi-view images capture rich details of the 3D asset from different viewpoints, relaxing the tasks from single-view to multi-view reconstruction. In the second stage, we introduce a feed-forward reconstruction model that rapidly and faithfully reconstructs the 3D asset given the generated multi-view images in approximately 7 seconds. The reconstruction network learns to handle noises and in-consistency introduced by the multi-view diffusion and leverages the available information from the condition image to efficiently recover the 3D structure. Our framework involves the text-to-image model, i.e., Hunyuan-DiT, making it a unified framework to support both text- and image-conditioned 3D generation. Our standard version has 3x more parameters than our lite and other existing model. Our Hunyuan3D-1.0 achieves an impressive balance between speed and quality, significantly reducing generation time while maintaining the quality and diversity of the produced assets.
Separating Content from Style Using Adversarial Learning for Recognizing Text in the Wild
Jan 13, 2020

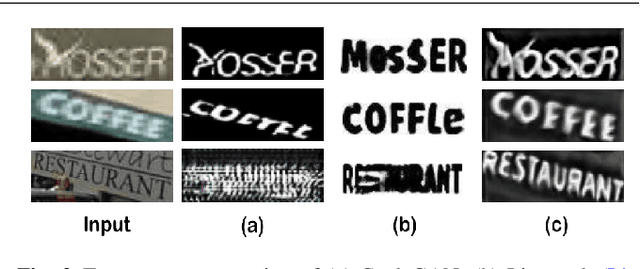

In this work we propose to improve text recognition from a new perspective by separating text content from complex backgrounds. We exploit the generative adversarial networks (GANs) for removing backgrounds while retaining the text content. As vanilla GANs are not sufficiently robust to generate sequence-like characters in natural images, we propose an adversarial learning framework for the generation and recognition of multiple characters in an image. The proposed framework consists of an attention-based recognizer and a generative adversarial architecture. Furthermore, to tackle the lack of paired training samples, we design an interactive joint training scheme, which shares attention masks from the recognizer to the discriminator, and enables the discriminator to extract the features of every character for further adversarial training. Benefiting from the character-level adversarial training, our framework requires only unpaired simple data for style supervision. Every target style sample containing only one randomly chosen character can be simply synthesized online during the training. This is significant as the training does not require costly paired samples or character-level annotations. Thus, only the input images and corresponding text labels are needed. In addition to the style transfer of the backgrounds, we refine character patterns to ease the recognition task. A feedback mechanism is proposed to bridge the gap between the discriminator and the recognizer. Therefore, the discriminator can guide the generator according to the confusion of the recognizer. The generated patterns are thus clearer for recognition. Experiments on various benchmarks, including both regular and irregular text, demonstrate that our method significantly reduces the difficulty of recognition. Our framework can be integrated with recent recognition methods to achieve new state-of-the-art performance.