 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBESTAnP: Bi-Step Efficient and Statistically Optimal Estimator for Acoustic-n-Point Problem
Nov 26, 2024
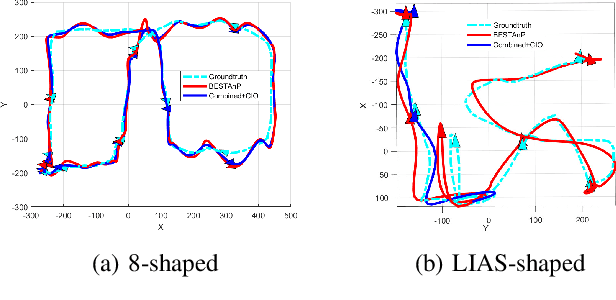
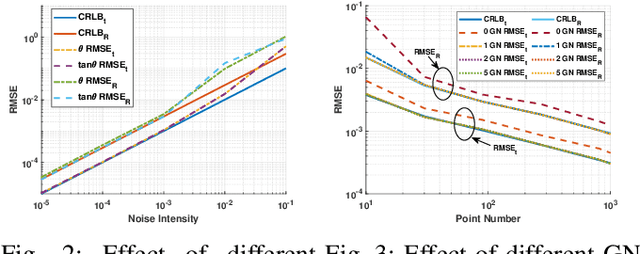
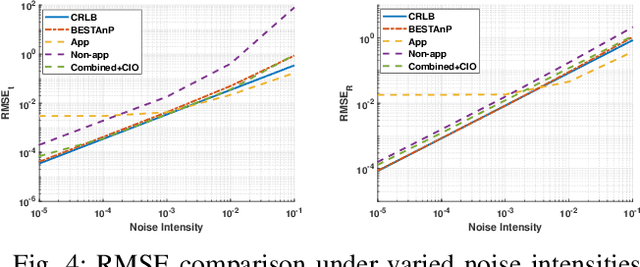
We consider the acoustic-n-point (AnP) problem, which estimates the pose of a 2D forward-looking sonar (FLS) according to n 3D-2D point correspondences. We explore the nature of the measured partial spherical coordinates and reveal their inherent relationships to translation and orientation. Based on this, we propose a bi-step efficient and statistically optimal AnP (BESTAnP) algorithm that decouples the estimation of translation and orientation. Specifically, in the first step, the translation estimation is formulated as the range-based localization problem based on distance-only measurements. In the second step, the rotation is estimated via eigendecomposition based on azimuth-only measurements and the estimated translation. BESTAnP is the first AnP algorithm that gives a closed-form solution for the full six-degree pose. In addition, we conduct bias elimination for BESTAnP such that it owns the statistical property of consistency. Through simulation and real-world experiments, we demonstrate that compared with the state-of-the-art (SOTA) methods, BESTAnP is over ten times faster and features real-time capacity in resource-constrained platforms while exhibiting comparable accuracy. Moreover, for the first time, we embed BESTAnP into a sonar-based odometry which shows its effectiveness for trajectory estimation.
Tencent Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation
Nov 05, 2024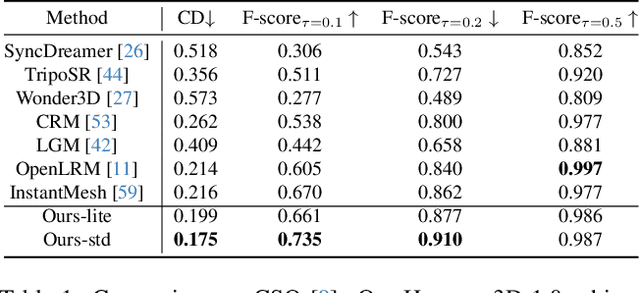

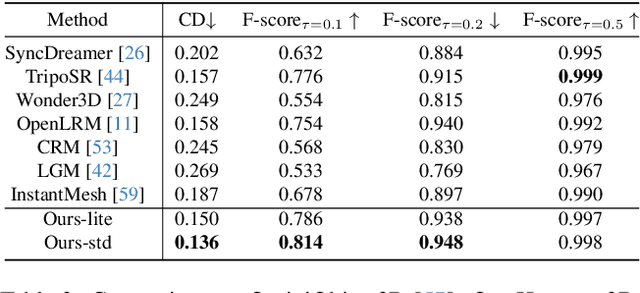

While 3D generative models have greatly improved artists' workflows, the existing diffusion models for 3D generation suffer from slow generation and poor generalization. To address this issue, we propose a two-stage approach named Hunyuan3D-1.0 including a lite version and a standard version, that both support text- and image-conditioned generation. In the first stage, we employ a multi-view diffusion model that efficiently generates multi-view RGB in approximately 4 seconds. These multi-view images capture rich details of the 3D asset from different viewpoints, relaxing the tasks from single-view to multi-view reconstruction. In the second stage, we introduce a feed-forward reconstruction model that rapidly and faithfully reconstructs the 3D asset given the generated multi-view images in approximately 7 seconds. The reconstruction network learns to handle noises and in-consistency introduced by the multi-view diffusion and leverages the available information from the condition image to efficiently recover the 3D structure. Our framework involves the text-to-image model, i.e., Hunyuan-DiT, making it a unified framework to support both text- and image-conditioned 3D generation. Our standard version has 3x more parameters than our lite and other existing model. Our Hunyuan3D-1.0 achieves an impressive balance between speed and quality, significantly reducing generation time while maintaining the quality and diversity of the produced assets.