 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneTransporter: Optimal Transport-Guided Compositional Latent Diffusion for Single-Image Structured 3D Scene Generation
Feb 26, 2026We introduce SceneTransporter, an end-to-end framework for structured 3D scene generation from a single image. While existing methods generate part-level 3D objects, they often fail to organize these parts into distinct instances in open-world scenes. Through a debiased clustering probe, we reveal a critical insight: this failure stems from the lack of structural constraints within the model's internal assignment mechanism. Based on this finding, we reframe the task of structured 3D scene generation as a global correlation assignment problem. To solve this, SceneTransporter formulates and solves an entropic Optimal Transport (OT) objective within the denoising loop of the compositional DiT model. This formulation imposes two powerful structural constraints. First, the resulting transport plan gates cross-attention to enforce an exclusive, one-to-one routing of image patches to part-level 3D latents, preventing entanglement. Second, the competitive nature of the transport encourages the grouping of similar patches, a process that is further regularized by an edge-based cost, to form coherent objects and prevent fragmentation. Extensive experiments show that SceneTransporter outperforms existing methods on open-world scene generation, significantly improving instance-level coherence and geometric fidelity. Code and models will be publicly available at https://2019epwl.github.io/SceneTransporter/.
Video4DGen: Enhancing Video and 4D Generation through Mutual Optimization
Apr 05, 2025The advancement of 4D (i.e., sequential 3D) generation opens up new possibilities for lifelike experiences in various applications, where users can explore dynamic objects or characters from any viewpoint. Meanwhile, video generative models are receiving particular attention given their ability to produce realistic and imaginative frames. These models are also observed to exhibit strong 3D consistency, indicating the potential to act as world simulators. In this work, we present Video4DGen, a novel framework that excels in generating 4D representations from single or multiple generated videos as well as generating 4D-guided videos. This framework is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. The 4D outputs generated by Video4DGen are represented using our proposed Dynamic Gaussian Surfels (DGS), which optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. We design warped-state geometric regularization and refinements on Gaussian surfels, to preserve the structural integrity and fine-grained appearance details. To perform 4D generation from multiple videos and capture representation across spatial, temporal, and pose dimensions, we design multi-video alignment, root pose optimization, and pose-guided frame sampling strategies. The leveraging of continuous warping fields also enables a precise depiction of pose, motion, and deformation over per-video frames. Further, to improve the overall fidelity from the observation of all camera poses, Video4DGen performs novel-view video generation guided by the 4D content, with the proposed confidence-filtered DGS to enhance the quality of generated sequences. With the ability of 4D and video generation, Video4DGen offers a powerful tool for applications in virtual reality, animation, and beyond.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Medical Multimodal Foundation Models in Clinical Diagnosis and Treatment: Applications, Challenges, and Future Directions
Dec 03, 2024



Recent advancements in deep learning have significantly revolutionized the field of clinical diagnosis and treatment, offering novel approaches to improve diagnostic precision and treatment efficacy across diverse clinical domains, thus driving the pursuit of precision medicine. The growing availability of multi-organ and multimodal datasets has accelerated the development of large-scale Medical Multimodal Foundation Models (MMFMs). These models, known for their strong generalization capabilities and rich representational power, are increasingly being adapted to address a wide range of clinical tasks, from early diagnosis to personalized treatment strategies. This review offers a comprehensive analysis of recent developments in MMFMs, focusing on three key aspects: datasets, model architectures, and clinical applications. We also explore the challenges and opportunities in optimizing multimodal representations and discuss how these advancements are shaping the future of healthcare by enabling improved patient outcomes and more efficient clinical workflows.
Tencent Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation
Nov 05, 2024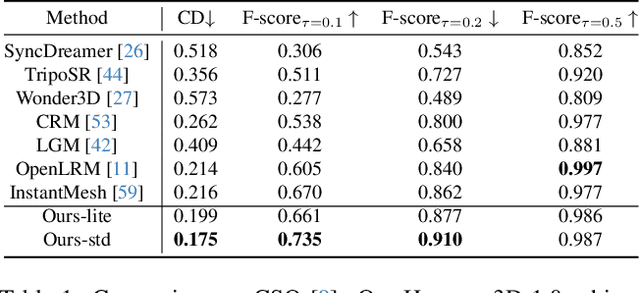

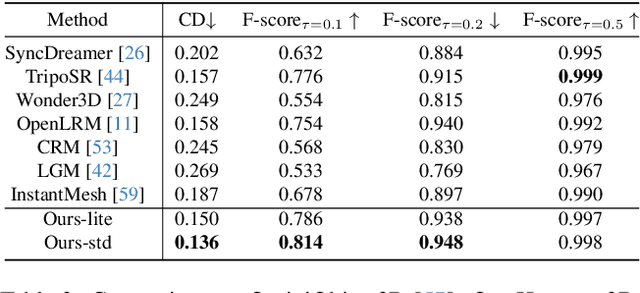

While 3D generative models have greatly improved artists' workflows, the existing diffusion models for 3D generation suffer from slow generation and poor generalization. To address this issue, we propose a two-stage approach named Hunyuan3D-1.0 including a lite version and a standard version, that both support text- and image-conditioned generation. In the first stage, we employ a multi-view diffusion model that efficiently generates multi-view RGB in approximately 4 seconds. These multi-view images capture rich details of the 3D asset from different viewpoints, relaxing the tasks from single-view to multi-view reconstruction. In the second stage, we introduce a feed-forward reconstruction model that rapidly and faithfully reconstructs the 3D asset given the generated multi-view images in approximately 7 seconds. The reconstruction network learns to handle noises and in-consistency introduced by the multi-view diffusion and leverages the available information from the condition image to efficiently recover the 3D structure. Our framework involves the text-to-image model, i.e., Hunyuan-DiT, making it a unified framework to support both text- and image-conditioned 3D generation. Our standard version has 3x more parameters than our lite and other existing model. Our Hunyuan3D-1.0 achieves an impressive balance between speed and quality, significantly reducing generation time while maintaining the quality and diversity of the produced assets.
Vidu4D: Single Generated Video to High-Fidelity 4D Reconstruction with Dynamic Gaussian Surfels
May 27, 2024Video generative models are receiving particular attention given their ability to generate realistic and imaginative frames. Besides, these models are also observed to exhibit strong 3D consistency, significantly enhancing their potential to act as world simulators. In this work, we present Vidu4D, a novel reconstruction model that excels in accurately reconstructing 4D (i.e., sequential 3D) representations from single generated videos, addressing challenges associated with non-rigidity and frame distortion. This capability is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. At the core of Vidu4D is our proposed Dynamic Gaussian Surfels (DGS) technique. DGS optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. This transformation enables a precise depiction of motion and deformation over time. To preserve the structural integrity of surface-aligned Gaussian surfels, we design the warped-state geometric regularization based on continuous warping fields for estimating normals. Additionally, we learn refinements on rotation and scaling parameters of Gaussian surfels, which greatly alleviates texture flickering during the warping process and enhances the capture of fine-grained appearance details. Vidu4D also contains a novel initialization state that provides a proper start for the warping fields in DGS. Equipping Vidu4D with an existing video generative model, the overall framework demonstrates high-fidelity text-to-4D generation in both appearance and geometry.
Equivariant Local Reference Frames for Unsupervised Non-rigid Point Cloud Shape Correspondence
Apr 01, 2024Unsupervised non-rigid point cloud shape correspondence underpins a multitude of 3D vision tasks, yet itself is non-trivial given the exponential complexity stemming from inter-point degree-of-freedom, i.e., pose transformations. Based on the assumption of local rigidity, one solution for reducing complexity is to decompose the overall shape into independent local regions using Local Reference Frames (LRFs) that are invariant to SE(3) transformations. However, the focus solely on local structure neglects global geometric contexts, resulting in less distinctive LRFs that lack crucial semantic information necessary for effective matching. Furthermore, such complexity introduces out-of-distribution geometric contexts during inference, thus complicating generalization. To this end, we introduce 1) EquiShape, a novel structure tailored to learn pair-wise LRFs with global structural cues for both spatial and semantic consistency, and 2) LRF-Refine, an optimization strategy generally applicable to LRF-based methods, aimed at addressing the generalization challenges. Specifically, for EquiShape, we employ cross-talk within separate equivariant graph neural networks (Cross-GVP) to build long-range dependencies to compensate for the lack of semantic information in local structure modeling, deducing pair-wise independent SE(3)-equivariant LRF vectors for each point. For LRF-Refine, the optimization adjusts LRFs within specific contexts and knowledge, enhancing the geometric and semantic generalizability of point features. Our overall framework surpasses the state-of-the-art methods by a large margin on three benchmarks. Code and models will be publicly available.
DreamReward: Text-to-3D Generation with Human Preference
Mar 21, 2024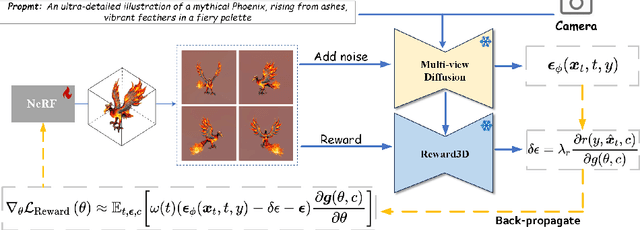


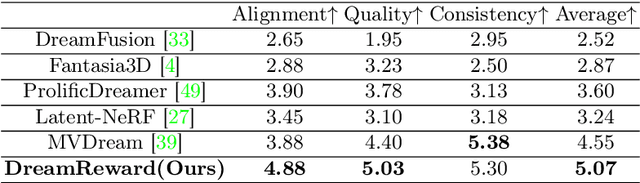
3D content creation from text prompts has shown remarkable success recently. However, current text-to-3D methods often generate 3D results that do not align well with human preferences. In this paper, we present a comprehensive framework, coined DreamReward, to learn and improve text-to-3D models from human preference feedback. To begin with, we collect 25k expert comparisons based on a systematic annotation pipeline including rating and ranking. Then, we build Reward3D -- the first general-purpose text-to-3D human preference reward model to effectively encode human preferences. Building upon the 3D reward model, we finally perform theoretical analysis and present the Reward3D Feedback Learning (DreamFL), a direct tuning algorithm to optimize the multi-view diffusion models with a redefined scorer. Grounded by theoretical proof and extensive experiment comparisons, our DreamReward successfully generates high-fidelity and 3D consistent results with significant boosts in prompt alignment with human intention. Our results demonstrate the great potential for learning from human feedback to improve text-to-3D models.
Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
Mar 15, 2024Encouraged by the growing availability of pre-trained 2D diffusion models, image-to-3D generation by leveraging Score Distillation Sampling (SDS) is making remarkable progress. Most existing methods combine novel-view lifting from 2D diffusion models which usually take the reference image as a condition while applying hard L2 image supervision at the reference view. Yet heavily adhering to the image is prone to corrupting the inductive knowledge of the 2D diffusion model leading to flat or distorted 3D generation frequently. In this work, we reexamine image-to-3D in a novel perspective and present Isotropic3D, an image-to-3D generation pipeline that takes only an image CLIP embedding as input. Isotropic3D allows the optimization to be isotropic w.r.t. the azimuth angle by solely resting on the SDS loss. The core of our framework lies in a two-stage diffusion model fine-tuning. Firstly, we fine-tune a text-to-3D diffusion model by substituting its text encoder with an image encoder, by which the model preliminarily acquires image-to-image capabilities. Secondly, we perform fine-tuning using our Explicit Multi-view Attention (EMA) which combines noisy multi-view images with the noise-free reference image as an explicit condition. CLIP embedding is sent to the diffusion model throughout the whole process while reference images are discarded once after fine-tuning. As a result, with a single image CLIP embedding, Isotropic3D is capable of generating multi-view mutually consistent images and also a 3D model with more symmetrical and neat content, well-proportioned geometry, rich colored texture, and less distortion compared with existing image-to-3D methods while still preserving the similarity to the reference image to a large extent. The project page is available at https://isotropic3d.github.io/. The code and models are available at https://github.com/pkunliu/Isotropic3D.
AnimatableDreamer: Text-Guided Non-rigid 3D Model Generation and Reconstruction with Canonical Score Distillation
Dec 20, 2023
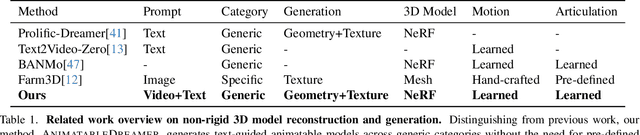


Text-to-3D model adaptations have advanced static 3D model quality, but sequential 3D model generation, particularly for animatable objects with large motions, is still scarce. Our work proposes AnimatableDreamer, a text-to-4D generation framework capable of generating diverse categories of non-rigid objects while adhering to the object motions extracted from a monocular video. At its core, AnimatableDreamer is equipped with our novel optimization design dubbed Canonical Score Distillation (CSD), which simplifies the generation dimension from 4D to 3D by denoising over different frames in the time-varying camera spaces while conducting the distillation process in a unique canonical space shared per video. Concretely, CSD ensures that score gradients back-propagate to the canonical space through differentiable warping, hence guaranteeing the time-consistent generation and maintaining morphological plausibility across different poses. By lifting the 3D generator to 4D with warping functions, AnimatableDreamer offers a novel perspective on non-rigid 3D model generation and reconstruction. Besides, with inductive knowledge from a multi-view consistent diffusion model, CSD regularizes reconstruction from novel views, thus cyclically enhancing the generation process. Extensive experiments demonstrate the capability of our method in generating high-flexibility text-guided 3D models from the monocular video, while also showing improved reconstruction performance over typical non-rigid reconstruction methods. Project page https://AnimatableDreamer.github.io.