 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimatableDreamer: Text-Guided Non-rigid 3D Model Generation and Reconstruction with Canonical Score Distillation
Paper and Code

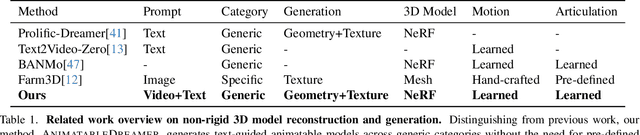


Text-to-3D model adaptations have advanced static 3D model quality, but sequential 3D model generation, particularly for animatable objects with large motions, is still scarce. Our work proposes AnimatableDreamer, a text-to-4D generation framework capable of generating diverse categories of non-rigid objects while adhering to the object motions extracted from a monocular video. At its core, AnimatableDreamer is equipped with our novel optimization design dubbed Canonical Score Distillation (CSD), which simplifies the generation dimension from 4D to 3D by denoising over different frames in the time-varying camera spaces while conducting the distillation process in a unique canonical space shared per video. Concretely, CSD ensures that score gradients back-propagate to the canonical space through differentiable warping, hence guaranteeing the time-consistent generation and maintaining morphological plausibility across different poses. By lifting the 3D generator to 4D with warping functions, AnimatableDreamer offers a novel perspective on non-rigid 3D model generation and reconstruction. Besides, with inductive knowledge from a multi-view consistent diffusion model, CSD regularizes reconstruction from novel views, thus cyclically enhancing the generation process. Extensive experiments demonstrate the capability of our method in generating high-flexibility text-guided 3D models from the monocular video, while also showing improved reconstruction performance over typical non-rigid reconstruction methods. Project page https://AnimatableDreamer.github.io.