 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-X-MLLM: Part-aware 3D Multimodal Large Language Model
Nov 17, 2025We introduce Part-X-MLLM, a native 3D multimodal large language model that unifies diverse 3D tasks by formulating them as programs in a structured, executable grammar. Given an RGB point cloud and a natural language prompt, our model autoregressively generates a single, coherent token sequence encoding part-level bounding boxes, semantic descriptions, and edit commands. This structured output serves as a versatile interface to drive downstream geometry-aware modules for part-based generation and editing. By decoupling the symbolic planning from the geometric synthesis, our approach allows any compatible geometry engine to be controlled through a single, language-native frontend. We pre-train a dual-encoder architecture to disentangle structure from semantics and instruction-tune the model on a large-scale, part-centric dataset. Experiments demonstrate that our model excels at producing high-quality, structured plans, enabling state-of-the-art performance in grounded Q\&A, compositional generation, and localized editing through one unified interface. Project page: https://chunshi.wang/Part-X-MLLM/
FreqSelect: Frequency-Aware fMRI-to-Image Reconstruction
May 18, 2025Reconstructing natural images from functional magnetic resonance imaging (fMRI) data remains a core challenge in natural decoding due to the mismatch between the richness of visual stimuli and the noisy, low resolution nature of fMRI signals. While recent two-stage models, combining deep variational autoencoders (VAEs) with diffusion models, have advanced this task, they treat all spatial-frequency components of the input equally. This uniform treatment forces the model to extract meaning features and suppress irrelevant noise simultaneously, limiting its effectiveness. We introduce FreqSelect, a lightweight, adaptive module that selectively filters spatial-frequency bands before encoding. By dynamically emphasizing frequencies that are most predictive of brain activity and suppressing those that are uninformative, FreqSelect acts as a content-aware gate between image features and natural data. It integrates seamlessly into standard very deep VAE-diffusion pipelines and requires no additional supervision. Evaluated on the Natural Scenes dataset, FreqSelect consistently improves reconstruction quality across both low- and high-level metrics. Beyond performance gains, the learned frequency-selection patterns offer interpretable insights into how different visual frequencies are represented in the brain. Our method generalizes across subjects and scenes, and holds promise for extension to other neuroimaging modalities, offering a principled approach to enhancing both decoding accuracy and neuroscientific interpretability.
DeepMesh: Auto-Regressive Artist-mesh Creation with Reinforcement Learning
Mar 19, 2025



Triangle meshes play a crucial role in 3D applications for efficient manipulation and rendering. While auto-regressive methods generate structured meshes by predicting discrete vertex tokens, they are often constrained by limited face counts and mesh incompleteness. To address these challenges, we propose DeepMesh, a framework that optimizes mesh generation through two key innovations: (1) an efficient pre-training strategy incorporating a novel tokenization algorithm, along with improvements in data curation and processing, and (2) the introduction of Reinforcement Learning (RL) into 3D mesh generation to achieve human preference alignment via Direct Preference Optimization (DPO). We design a scoring standard that combines human evaluation with 3D metrics to collect preference pairs for DPO, ensuring both visual appeal and geometric accuracy. Conditioned on point clouds and images, DeepMesh generates meshes with intricate details and precise topology, outperforming state-of-the-art methods in both precision and quality. Project page: https://zhaorw02.github.io/DeepMesh/
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model
Aug 29, 2024Advancements in 3D scene reconstruction have transformed 2D images from the real world into 3D models, producing realistic 3D results from hundreds of input photos. Despite great success in dense-view reconstruction scenarios, rendering a detailed scene from insufficient captured views is still an ill-posed optimization problem, often resulting in artifacts and distortions in unseen areas. In this paper, we propose ReconX, a novel 3D scene reconstruction paradigm that reframes the ambiguous reconstruction challenge as a temporal generation task. The key insight is to unleash the strong generative prior of large pre-trained video diffusion models for sparse-view reconstruction. However, 3D view consistency struggles to be accurately preserved in directly generated video frames from pre-trained models. To address this, given limited input views, the proposed ReconX first constructs a global point cloud and encodes it into a contextual space as the 3D structure condition. Guided by the condition, the video diffusion model then synthesizes video frames that are both detail-preserved and exhibit a high degree of 3D consistency, ensuring the coherence of the scene from various perspectives. Finally, we recover the 3D scene from the generated video through a confidence-aware 3D Gaussian Splatting optimization scheme. Extensive experiments on various real-world datasets show the superiority of our ReconX over state-of-the-art methods in terms of quality and generalizability.
DreamReward: Text-to-3D Generation with Human Preference
Mar 21, 2024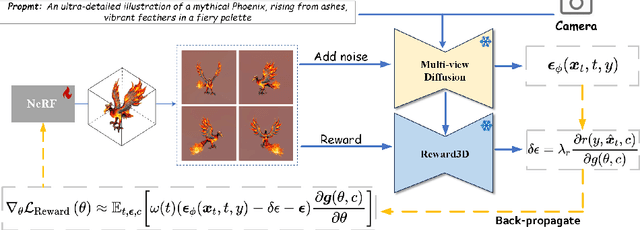


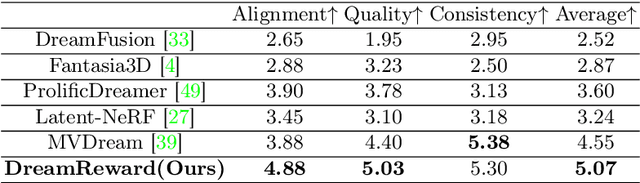
3D content creation from text prompts has shown remarkable success recently. However, current text-to-3D methods often generate 3D results that do not align well with human preferences. In this paper, we present a comprehensive framework, coined DreamReward, to learn and improve text-to-3D models from human preference feedback. To begin with, we collect 25k expert comparisons based on a systematic annotation pipeline including rating and ranking. Then, we build Reward3D -- the first general-purpose text-to-3D human preference reward model to effectively encode human preferences. Building upon the 3D reward model, we finally perform theoretical analysis and present the Reward3D Feedback Learning (DreamFL), a direct tuning algorithm to optimize the multi-view diffusion models with a redefined scorer. Grounded by theoretical proof and extensive experiment comparisons, our DreamReward successfully generates high-fidelity and 3D consistent results with significant boosts in prompt alignment with human intention. Our results demonstrate the great potential for learning from human feedback to improve text-to-3D models.
AnimatableDreamer: Text-Guided Non-rigid 3D Model Generation and Reconstruction with Canonical Score Distillation
Dec 20, 2023
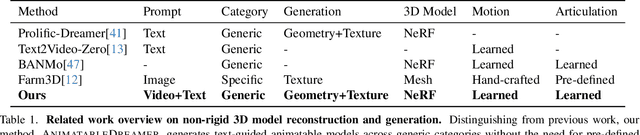


Text-to-3D model adaptations have advanced static 3D model quality, but sequential 3D model generation, particularly for animatable objects with large motions, is still scarce. Our work proposes AnimatableDreamer, a text-to-4D generation framework capable of generating diverse categories of non-rigid objects while adhering to the object motions extracted from a monocular video. At its core, AnimatableDreamer is equipped with our novel optimization design dubbed Canonical Score Distillation (CSD), which simplifies the generation dimension from 4D to 3D by denoising over different frames in the time-varying camera spaces while conducting the distillation process in a unique canonical space shared per video. Concretely, CSD ensures that score gradients back-propagate to the canonical space through differentiable warping, hence guaranteeing the time-consistent generation and maintaining morphological plausibility across different poses. By lifting the 3D generator to 4D with warping functions, AnimatableDreamer offers a novel perspective on non-rigid 3D model generation and reconstruction. Besides, with inductive knowledge from a multi-view consistent diffusion model, CSD regularizes reconstruction from novel views, thus cyclically enhancing the generation process. Extensive experiments demonstrate the capability of our method in generating high-flexibility text-guided 3D models from the monocular video, while also showing improved reconstruction performance over typical non-rigid reconstruction methods. Project page https://AnimatableDreamer.github.io.