 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotus: A Unified Latent Action World Model
Dec 15, 2025While a general embodied agent must function as a unified system, current methods are built on isolated models for understanding, world modeling, and control. This fragmentation prevents unifying multimodal generative capabilities and hinders learning from large-scale, heterogeneous data. In this paper, we propose Motus, a unified latent action world model that leverages existing general pretrained models and rich, sharable motion information. Motus introduces a Mixture-of-Transformer (MoT) architecture to integrate three experts (i.e., understanding, video generation, and action) and adopts a UniDiffuser-style scheduler to enable flexible switching between different modeling modes (i.e., world models, vision-language-action models, inverse dynamics models, video generation models, and video-action joint prediction models). Motus further leverages the optical flow to learn latent actions and adopts a recipe with three-phase training pipeline and six-layer data pyramid, thereby extracting pixel-level "delta action" and enabling large-scale action pretraining. Experiments show that Motus achieves superior performance against state-of-the-art methods in both simulation (a +15% improvement over X-VLA and a +45% improvement over Pi0.5) and real-world scenarios(improved by +11~48%), demonstrating unified modeling of all functionalities and priors significantly benefits downstream robotic tasks.
DeepMesh: Auto-Regressive Artist-mesh Creation with Reinforcement Learning
Mar 19, 2025



Triangle meshes play a crucial role in 3D applications for efficient manipulation and rendering. While auto-regressive methods generate structured meshes by predicting discrete vertex tokens, they are often constrained by limited face counts and mesh incompleteness. To address these challenges, we propose DeepMesh, a framework that optimizes mesh generation through two key innovations: (1) an efficient pre-training strategy incorporating a novel tokenization algorithm, along with improvements in data curation and processing, and (2) the introduction of Reinforcement Learning (RL) into 3D mesh generation to achieve human preference alignment via Direct Preference Optimization (DPO). We design a scoring standard that combines human evaluation with 3D metrics to collect preference pairs for DPO, ensuring both visual appeal and geometric accuracy. Conditioned on point clouds and images, DeepMesh generates meshes with intricate details and precise topology, outperforming state-of-the-art methods in both precision and quality. Project page: https://zhaorw02.github.io/DeepMesh/
FlexiDreamer: Single Image-to-3D Generation with FlexiCubes
Apr 01, 20243D content generation from text prompts or single images has made remarkable progress in quality and speed recently. One of its dominant paradigms involves generating consistent multi-view images followed by a sparse-view reconstruction. However, due to the challenge of directly deforming the mesh representation to approach the target topology, most methodologies learn an implicit representation (such as NeRF) during the sparse-view reconstruction and acquire the target mesh by a post-processing extraction. Although the implicit representation can effectively model rich 3D information, its training typically entails a long convergence time. In addition, the post-extraction operation from the implicit field also leads to undesirable visual artifacts. In this paper, we propose FlexiDreamer, a novel single image-to-3d generation framework that reconstructs the target mesh in an end-to-end manner. By leveraging a flexible gradient-based extraction known as FlexiCubes, our method circumvents the defects brought by the post-processing and facilitates a direct acquisition of the target mesh. Furthermore, we incorporate a multi-resolution hash grid encoding scheme that progressively activates the encoding levels into the implicit field in FlexiCubes to help capture geometric details for per-step optimization. Notably, FlexiDreamer recovers a dense 3D structure from a single-view image in approximately 1 minute on a single NVIDIA A100 GPU, outperforming previous methodologies by a large margin.
BEVScope: Enhancing Self-Supervised Depth Estimation Leveraging Bird's-Eye-View in Dynamic Scenarios
Jun 20, 2023Depth estimation is a cornerstone of perception in autonomous driving and robotic systems. The considerable cost and relatively sparse data acquisition of LiDAR systems have led to the exploration of cost-effective alternatives, notably, self-supervised depth estimation. Nevertheless, current self-supervised depth estimation methods grapple with several limitations: (1) the failure to adequately leverage informative multi-camera views. (2) the limited capacity to handle dynamic objects effectively. To address these challenges, we present BEVScope, an innovative approach to self-supervised depth estimation that harnesses Bird's-Eye-View (BEV) features. Concurrently, we propose an adaptive loss function, specifically designed to mitigate the complexities associated with moving objects. Empirical evaluations conducted on the Nuscenes dataset validate our approach, demonstrating competitive performance. Code will be released at https://github.com/myc634/BEVScope.
LODE: Locally Conditioned Eikonal Implicit Scene Completion from Sparse LiDAR
Feb 27, 2023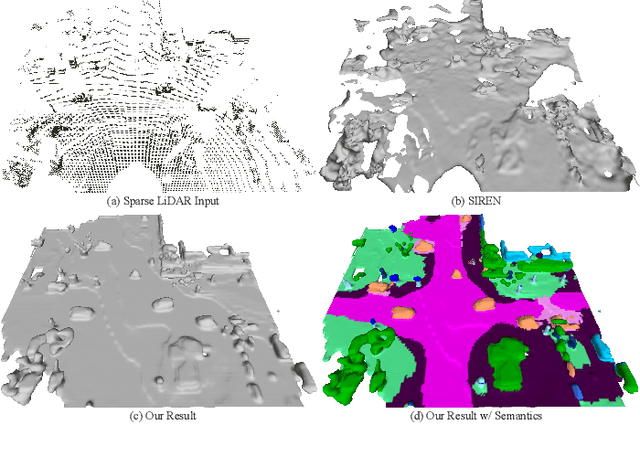
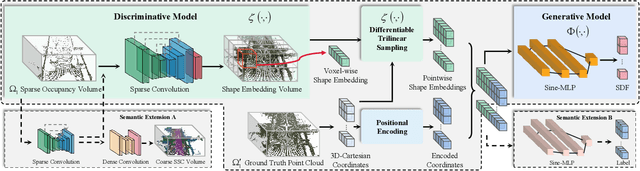
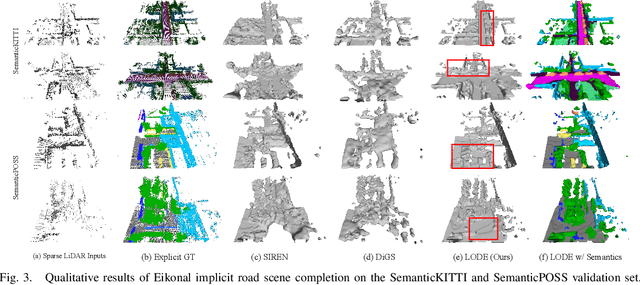
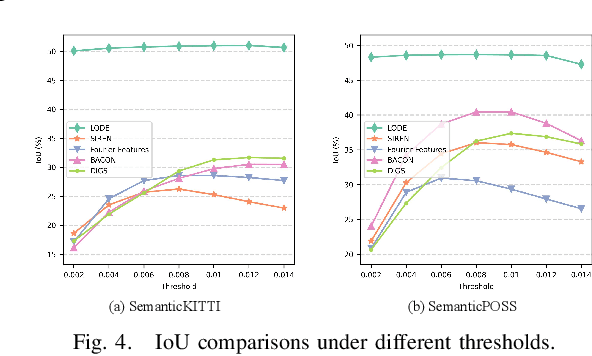
Scene completion refers to obtaining dense scene representation from an incomplete perception of complex 3D scenes. This helps robots detect multi-scale obstacles and analyse object occlusions in scenarios such as autonomous driving. Recent advances show that implicit representation learning can be leveraged for continuous scene completion and achieved through physical constraints like Eikonal equations. However, former Eikonal completion methods only demonstrate results on watertight meshes at a scale of tens of meshes. None of them are successfully done for non-watertight LiDAR point clouds of open large scenes at a scale of thousands of scenes. In this paper, we propose a novel Eikonal formulation that conditions the implicit representation on localized shape priors which function as dense boundary value constraints, and demonstrate it works on SemanticKITTI and SemanticPOSS. It can also be extended to semantic Eikonal scene completion with only small modifications to the network architecture. With extensive quantitative and qualitative results, we demonstrate the benefits and drawbacks of existing Eikonal methods, which naturally leads to the new locally conditioned formulation. Notably, we improve IoU from 31.7% to 51.2% on SemanticKITTI and from 40.5% to 48.7% on SemanticPOSS. We extensively ablate our methods and demonstrate that the proposed formulation is robust to a wide spectrum of implementation hyper-parameters. Codes and models are publicly available at https://github.com/AIR-DISCOVER/LODE.