 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and High-Fidelity 3D Gaussian Splatting: Fusing Pose Priors and Geometry Constraints for Texture-Deficient Outdoor Scenes
Nov 10, 20253D Gaussian Splatting (3DGS) has emerged as a key rendering pipeline for digital asset creation due to its balance between efficiency and visual quality. To address the issues of unstable pose estimation and scene representation distortion caused by geometric texture inconsistency in large outdoor scenes with weak or repetitive textures, we approach the problem from two aspects: pose estimation and scene representation. For pose estimation, we leverage LiDAR-IMU Odometry to provide prior poses for cameras in large-scale environments. These prior pose constraints are incorporated into COLMAP's triangulation process, with pose optimization performed via bundle adjustment. Ensuring consistency between pixel data association and prior poses helps maintain both robustness and accuracy. For scene representation, we introduce normal vector constraints and effective rank regularization to enforce consistency in the direction and shape of Gaussian primitives. These constraints are jointly optimized with the existing photometric loss to enhance the map quality. We evaluate our approach using both public and self-collected datasets. In terms of pose optimization, our method requires only one-third of the time while maintaining accuracy and robustness across both datasets. In terms of scene representation, the results show that our method significantly outperforms conventional 3DGS pipelines. Notably, on self-collected datasets characterized by weak or repetitive textures, our approach demonstrates enhanced visualization capabilities and achieves superior overall performance. Codes and data will be publicly available at https://github.com/justinyeah/normal_shape.git.
Semi-distributed Cross-modal Air-Ground Relative Localization
Nov 10, 2025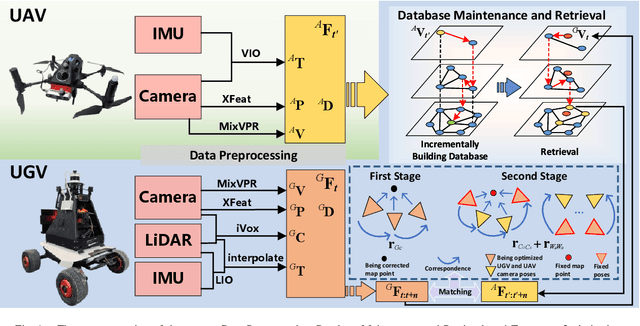
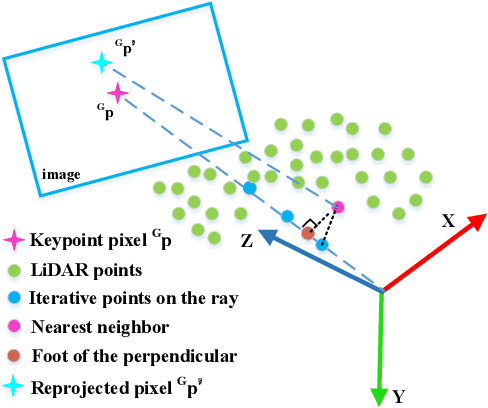

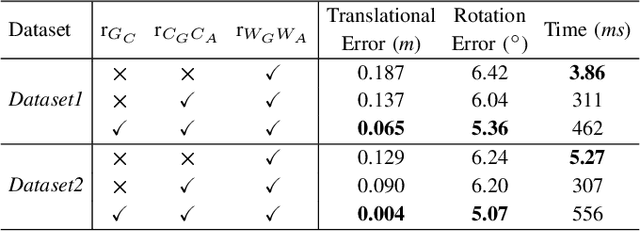
Efficient, accurate, and flexible relative localization is crucial in air-ground collaborative tasks. However, current approaches for robot relative localization are primarily realized in the form of distributed multi-robot SLAM systems with the same sensor configuration, which are tightly coupled with the state estimation of all robots, limiting both flexibility and accuracy. To this end, we fully leverage the high capacity of Unmanned Ground Vehicle (UGV) to integrate multiple sensors, enabling a semi-distributed cross-modal air-ground relative localization framework. In this work, both the UGV and the Unmanned Aerial Vehicle (UAV) independently perform SLAM while extracting deep learning-based keypoints and global descriptors, which decouples the relative localization from the state estimation of all agents. The UGV employs a local Bundle Adjustment (BA) with LiDAR, camera, and an IMU to rapidly obtain accurate relative pose estimates. The BA process adopts sparse keypoint optimization and is divided into two stages: First, optimizing camera poses interpolated from LiDAR-Inertial Odometry (LIO), followed by estimating the relative camera poses between the UGV and UAV. Additionally, we implement an incremental loop closure detection algorithm using deep learning-based descriptors to maintain and retrieve keyframes efficiently. Experimental results demonstrate that our method achieves outstanding performance in both accuracy and efficiency. Unlike traditional multi-robot SLAM approaches that transmit images or point clouds, our method only transmits keypoint pixels and their descriptors, effectively constraining the communication bandwidth under 0.3 Mbps. Codes and data will be publicly available on https://github.com/Ascbpiac/cross-model-relative-localization.git.
TopoDiffuser: A Diffusion-Based Multimodal Trajectory Prediction Model with Topometric Maps
Aug 01, 2025This paper introduces TopoDiffuser, a diffusion-based framework for multimodal trajectory prediction that incorporates topometric maps to generate accurate, diverse, and road-compliant future motion forecasts. By embedding structural cues from topometric maps into the denoising process of a conditional diffusion model, the proposed approach enables trajectory generation that naturally adheres to road geometry without relying on explicit constraints. A multimodal conditioning encoder fuses LiDAR observations, historical motion, and route information into a unified bird's-eye-view (BEV) representation. Extensive experiments on the KITTI benchmark demonstrate that TopoDiffuser outperforms state-of-the-art methods, while maintaining strong geometric consistency. Ablation studies further validate the contribution of each input modality, as well as the impact of denoising steps and the number of trajectory samples. To support future research, we publicly release our code at https://github.com/EI-Nav/TopoDiffuser.
NeRF-Based Transparent Object Grasping Enhanced by Shape Priors
Apr 14, 2025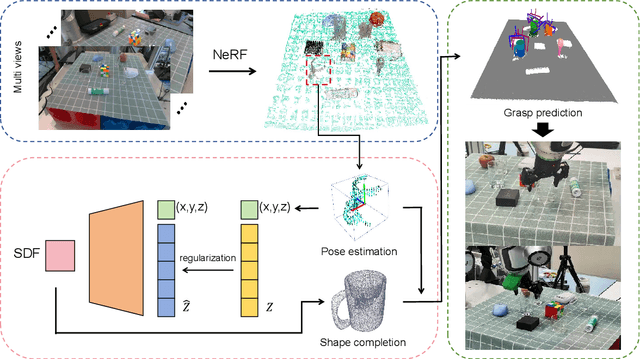
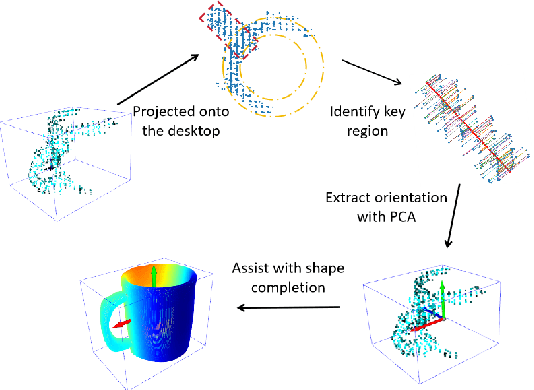
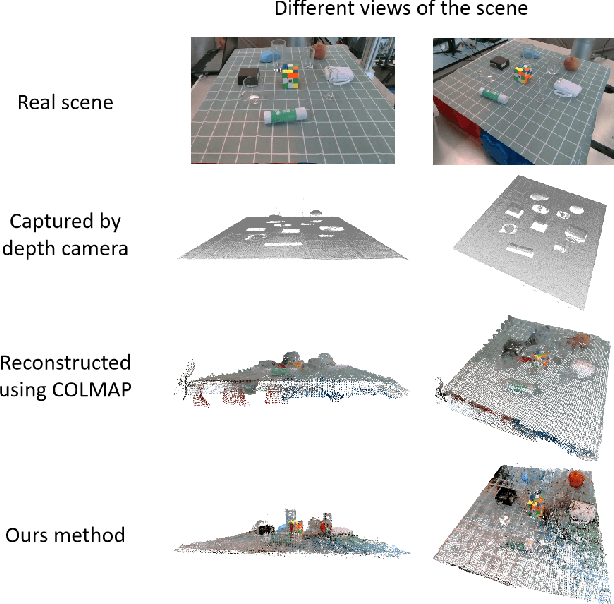
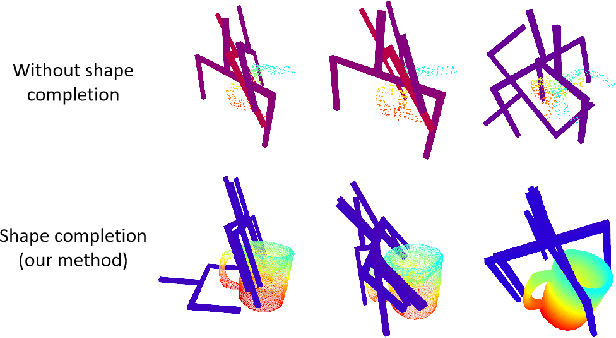
Transparent object grasping remains a persistent challenge in robotics, largely due to the difficulty of acquiring precise 3D information. Conventional optical 3D sensors struggle to capture transparent objects, and machine learning methods are often hindered by their reliance on high-quality datasets. Leveraging NeRF's capability for continuous spatial opacity modeling, our proposed architecture integrates a NeRF-based approach for reconstructing the 3D information of transparent objects. Despite this, certain portions of the reconstructed 3D information may remain incomplete. To address these deficiencies, we introduce a shape-prior-driven completion mechanism, further refined by a geometric pose estimation method we have developed. This allows us to obtain a complete and reliable 3D information of transparent objects. Utilizing this refined data, we perform scene-level grasp prediction and deploy the results in real-world robotic systems. Experimental validation demonstrates the efficacy of our architecture, showcasing its capability to reliably capture 3D information of various transparent objects in cluttered scenes, and correspondingly, achieve high-quality, stables, and executable grasp predictions.
OpenBench: A New Benchmark and Baseline for Semantic Navigation in Smart Logistics
Feb 13, 2025
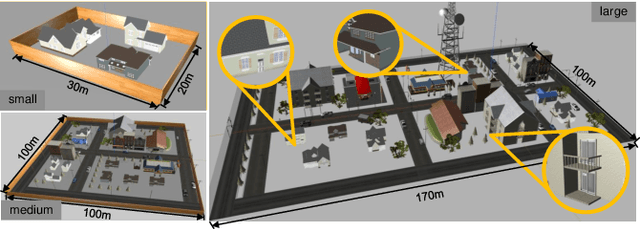


The increasing demand for efficient last-mile delivery in smart logistics underscores the role of autonomous robots in enhancing operational efficiency and reducing costs. Traditional navigation methods, which depend on high-precision maps, are resource-intensive, while learning-based approaches often struggle with generalization in real-world scenarios. To address these challenges, this work proposes the Openstreetmap-enhanced oPen-air sEmantic Navigation (OPEN) system that combines foundation models with classic algorithms for scalable outdoor navigation. The system uses off-the-shelf OpenStreetMap (OSM) for flexible map representation, thereby eliminating the need for extensive pre-mapping efforts. It also employs Large Language Models (LLMs) to comprehend delivery instructions and Vision-Language Models (VLMs) for global localization, map updates, and house number recognition. To compensate the limitations of existing benchmarks that are inadequate for assessing last-mile delivery, this work introduces a new benchmark specifically designed for outdoor navigation in residential areas, reflecting the real-world challenges faced by autonomous delivery systems. Extensive experiments in simulated and real-world environments demonstrate the proposed system's efficacy in enhancing navigation efficiency and reliability. To facilitate further research, our code and benchmark are publicly available.
Drone-assisted Road Gaussian Splatting with Cross-view Uncertainty
Aug 27, 2024
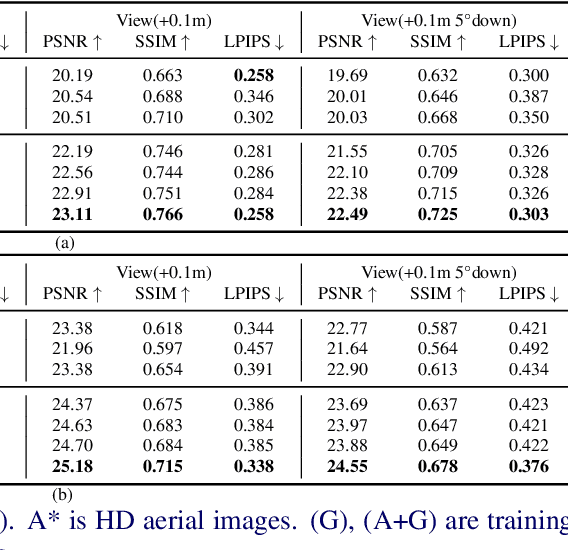
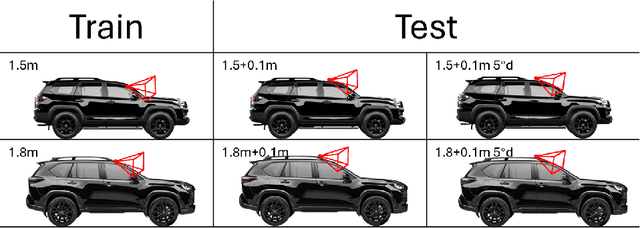
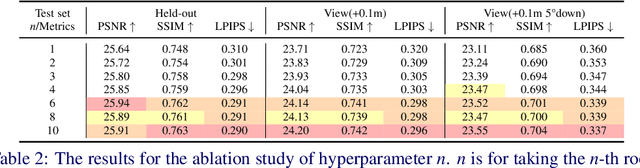
Robust and realistic rendering for large-scale road scenes is essential in autonomous driving simulation. Recently, 3D Gaussian Splatting (3D-GS) has made groundbreaking progress in neural rendering, but the general fidelity of large-scale road scene renderings is often limited by the input imagery, which usually has a narrow field of view and focuses mainly on the street-level local area. Intuitively, the data from the drone's perspective can provide a complementary viewpoint for the data from the ground vehicle's perspective, enhancing the completeness of scene reconstruction and rendering. However, training naively with aerial and ground images, which exhibit large view disparity, poses a significant convergence challenge for 3D-GS, and does not demonstrate remarkable improvements in performance on road views. In order to enhance the novel view synthesis of road views and to effectively use the aerial information, we design an uncertainty-aware training method that allows aerial images to assist in the synthesis of areas where ground images have poor learning outcomes instead of weighting all pixels equally in 3D-GS training like prior work did. We are the first to introduce the cross-view uncertainty to 3D-GS by matching the car-view ensemble-based rendering uncertainty to aerial images, weighting the contribution of each pixel to the training process. Additionally, to systematically quantify evaluation metrics, we assemble a high-quality synthesized dataset comprising both aerial and ground images for road scenes.
Robo-GS: A Physics Consistent Spatial-Temporal Model for Robotic Arm with Hybrid Representation
Aug 27, 2024Real2Sim2Real plays a critical role in robotic arm control and reinforcement learning, yet bridging this gap remains a significant challenge due to the complex physical properties of robots and the objects they manipulate. Existing methods lack a comprehensive solution to accurately reconstruct real-world objects with spatial representations and their associated physics attributes. We propose a Real2Sim pipeline with a hybrid representation model that integrates mesh geometry, 3D Gaussian kernels, and physics attributes to enhance the digital asset representation of robotic arms. This hybrid representation is implemented through a Gaussian-Mesh-Pixel binding technique, which establishes an isomorphic mapping between mesh vertices and Gaussian models. This enables a fully differentiable rendering pipeline that can be optimized through numerical solvers, achieves high-fidelity rendering via Gaussian Splatting, and facilitates physically plausible simulation of the robotic arm's interaction with its environment using mesh-based methods. The code,full presentation and datasets will be made publicly available at our website https://robostudioapp.com
Camera Relocalization in Shadow-free Neural Radiance Fields
May 23, 2024



Camera relocalization is a crucial problem in computer vision and robotics. Recent advancements in neural radiance fields (NeRFs) have shown promise in synthesizing photo-realistic images. Several works have utilized NeRFs for refining camera poses, but they do not account for lighting changes that can affect scene appearance and shadow regions, causing a degraded pose optimization process. In this paper, we propose a two-staged pipeline that normalizes images with varying lighting and shadow conditions to improve camera relocalization. We implement our scene representation upon a hash-encoded NeRF which significantly boosts up the pose optimization process. To account for the noisy image gradient computing problem in grid-based NeRFs, we further propose a re-devised truncated dynamic low-pass filter (TDLF) and a numerical gradient averaging technique to smoothen the process. Experimental results on several datasets with varying lighting conditions demonstrate that our method achieves state-of-the-art results in camera relocalization under varying lighting conditions. Code and data will be made publicly available.
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
May 05, 2024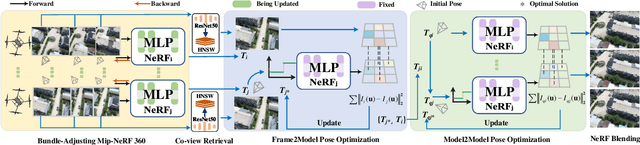
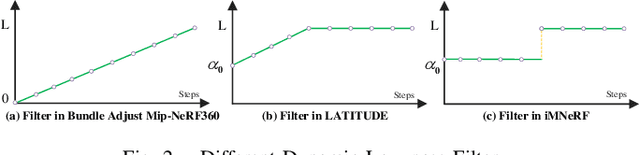

Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
An Onboard Framework for Staircases Modeling Based on Point Clouds
May 03, 2024
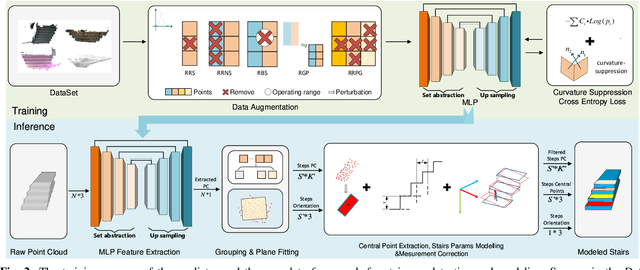
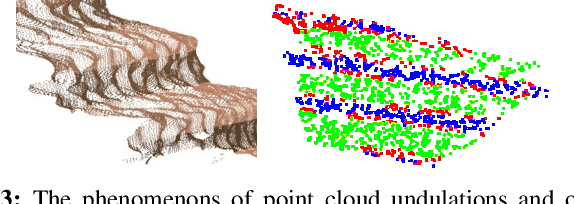
The detection of traversable regions on staircases and the physical modeling constitutes pivotal aspects of the mobility of legged robots. This paper presents an onboard framework tailored to the detection of traversable regions and the modeling of physical attributes of staircases by point cloud data. To mitigate the influence of illumination variations and the overfitting due to the dataset diversity, a series of data augmentations are introduced to enhance the training of the fundamental network. A curvature suppression cross-entropy(CSCE) loss is proposed to reduce the ambiguity of prediction on the boundary between traversable and non-traversable regions. Moreover, a measurement correction based on the pose estimation of stairs is introduced to calibrate the output of raw modeling that is influenced by tilted perspectives. Lastly, we collect a dataset pertaining to staircases and introduce new evaluation criteria. Through a series of rigorous experiments conducted on this dataset, we substantiate the superior accuracy and generalization capabilities of our proposed method. Codes, models, and datasets will be available at https://github.com/szturobotics/Stair-detection-and-modeling-project.