 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF-Based Transparent Object Grasping Enhanced by Shape Priors
Paper and Code
Apr 14, 2025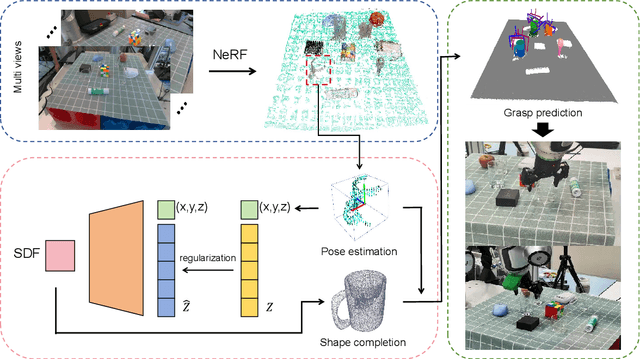
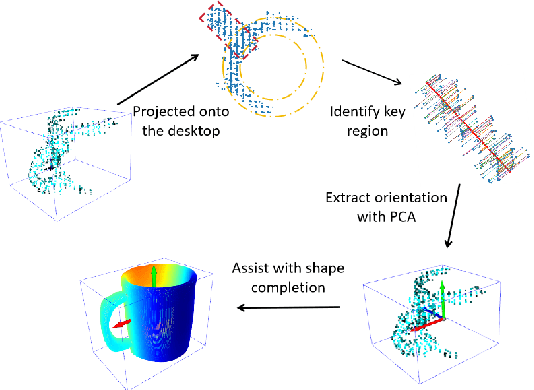
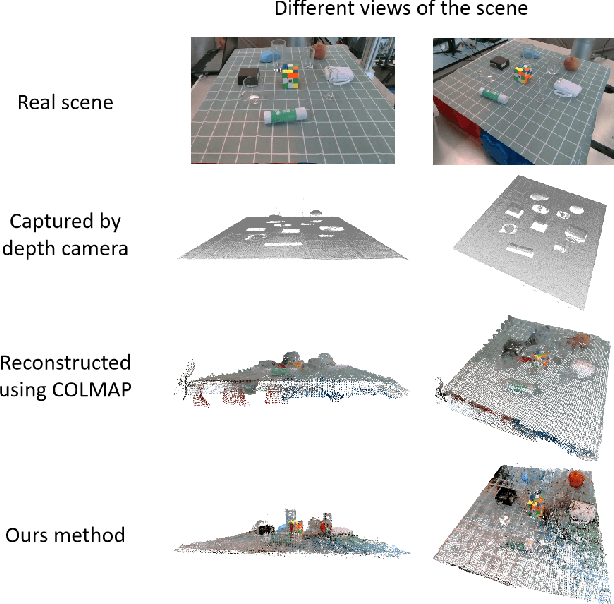
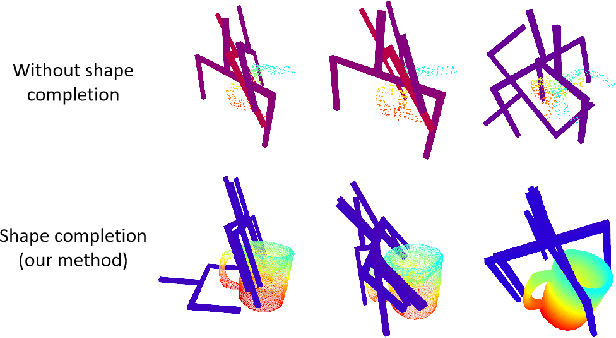
Transparent object grasping remains a persistent challenge in robotics, largely due to the difficulty of acquiring precise 3D information. Conventional optical 3D sensors struggle to capture transparent objects, and machine learning methods are often hindered by their reliance on high-quality datasets. Leveraging NeRF's capability for continuous spatial opacity modeling, our proposed architecture integrates a NeRF-based approach for reconstructing the 3D information of transparent objects. Despite this, certain portions of the reconstructed 3D information may remain incomplete. To address these deficiencies, we introduce a shape-prior-driven completion mechanism, further refined by a geometric pose estimation method we have developed. This allows us to obtain a complete and reliable 3D information of transparent objects. Utilizing this refined data, we perform scene-level grasp prediction and deploy the results in real-world robotic systems. Experimental validation demonstrates the efficacy of our architecture, showcasing its capability to reliably capture 3D information of various transparent objects in cluttered scenes, and correspondingly, achieve high-quality, stables, and executable grasp predictions.