 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenBench: A New Benchmark and Baseline for Semantic Navigation in Smart Logistics
Feb 13, 2025


The increasing demand for efficient last-mile delivery in smart logistics underscores the role of autonomous robots in enhancing operational efficiency and reducing costs. Traditional navigation methods, which depend on high-precision maps, are resource-intensive, while learning-based approaches often struggle with generalization in real-world scenarios. To address these challenges, this work proposes the Openstreetmap-enhanced oPen-air sEmantic Navigation (OPEN) system that combines foundation models with classic algorithms for scalable outdoor navigation. The system uses off-the-shelf OpenStreetMap (OSM) for flexible map representation, thereby eliminating the need for extensive pre-mapping efforts. It also employs Large Language Models (LLMs) to comprehend delivery instructions and Vision-Language Models (VLMs) for global localization, map updates, and house number recognition. To compensate the limitations of existing benchmarks that are inadequate for assessing last-mile delivery, this work introduces a new benchmark specifically designed for outdoor navigation in residential areas, reflecting the real-world challenges faced by autonomous delivery systems. Extensive experiments in simulated and real-world environments demonstrate the proposed system's efficacy in enhancing navigation efficiency and reliability. To facilitate further research, our code and benchmark are publicly available.
Towards the Unification of Generative and Discriminative Visual Foundation Model: A Survey
Dec 15, 2023The advent of foundation models, which are pre-trained on vast datasets, has ushered in a new era of computer vision, characterized by their robustness and remarkable zero-shot generalization capabilities. Mirroring the transformative impact of foundation models like large language models (LLMs) in natural language processing, visual foundation models (VFMs) have become a catalyst for groundbreaking developments in computer vision. This review paper delineates the pivotal trajectories of VFMs, emphasizing their scalability and proficiency in generative tasks such as text-to-image synthesis, as well as their adeptness in discriminative tasks including image segmentation. While generative and discriminative models have historically charted distinct paths, we undertake a comprehensive examination of the recent strides made by VFMs in both domains, elucidating their origins, seminal breakthroughs, and pivotal methodologies. Additionally, we collate and discuss the extensive resources that facilitate the development of VFMs and address the challenges that pave the way for future research endeavors. A crucial direction for forthcoming innovation is the amalgamation of generative and discriminative paradigms. The nascent application of generative models within discriminative contexts signifies the early stages of this confluence. This survey aspires to be a contemporary compendium for scholars and practitioners alike, charting the course of VFMs and illuminating their multifaceted landscape.
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
Oct 20, 2020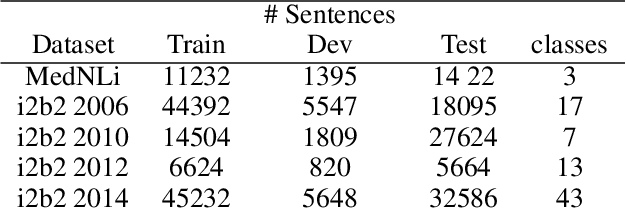
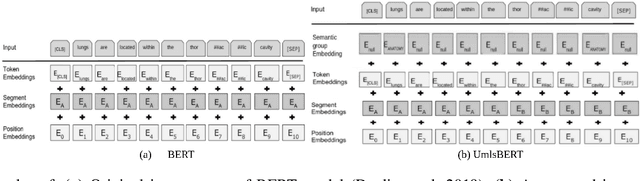
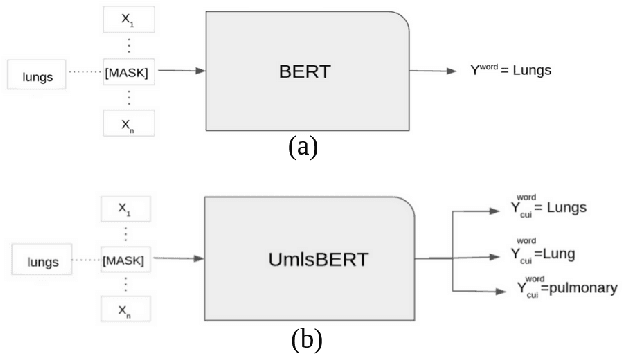
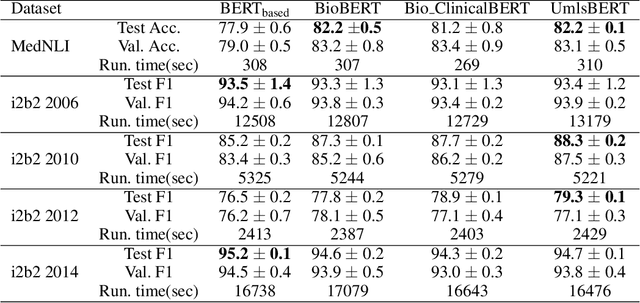
Contextual word embedding models, such as BioBERT and Bio_ClinicalBERT, have achieved state-of-the-art results in biomedical natural language processing tasks by focusing their pre-training process on domain-specific corpora. However, such models do not take into consideration expert domain knowledge. In this work, we introduced UmlsBERT, a contextual embedding model that integrates domain knowledge during the pre-training process via a novel knowledge augmentation strategy. More specifically, the augmentation on UmlsBERT with the Unified Medical Language System (UMLS) Metathesaurus was performed in two ways: i) connecting words that have the same underlying `concept' in UMLS, and ii) leveraging semantic group knowledge in UMLS to create clinically meaningful input embeddings. By applying these two strategies, UmlsBERT can encode clinical domain knowledge into word embeddings and outperform existing domain-specific models on common named-entity recognition (NER) and clinical natural language inference clinical NLP tasks.