 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynQP: A Framework and Metrics for Evaluating the Quality and Privacy Risk of Synthetic Data
Jan 17, 2026The use of synthetic data in health applications raises privacy concerns, yet the lack of open frameworks for privacy evaluations has slowed its adoption. A major challenge is the absence of accessible benchmark datasets for evaluating privacy risks, due to difficulties in acquiring sensitive data. To address this, we introduce SynQP, an open framework for benchmarking privacy in synthetic data generation (SDG) using simulated sensitive data, ensuring that original data remains confidential. We also highlight the need for privacy metrics that fairly account for the probabilistic nature of machine learning models. As a demonstration, we use SynQP to benchmark CTGAN and propose a new identity disclosure risk metric that offers a more accurate estimation of privacy risks compared to existing approaches. Our work provides a critical tool for improving the transparency and reliability of privacy evaluations, enabling safer use of synthetic data in health-related applications. % In our quality evaluations, non-private models achieved near-perfect machine-learning efficacy \(\ge0.97\). Our privacy assessments (Table II) reveal that DP consistently lowers both identity disclosure risk (SD-IDR) and membership-inference attack risk (SD-MIA), with all DP-augmented models staying below the 0.09 regulatory threshold. Code available at https://github.com/CAN-SYNH/SynQP
* 7 Pages, 22nd Annual International Conference on Privacy, Security, and Trust (PST2025), Fredericton, Canada
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Drug Discovery SMILES-to-Pharmacokinetics Diffusion Models with Deep Molecular Understanding
Aug 14, 2024Artificial intelligence (AI) is increasingly used in every stage of drug development. One challenge facing drug discovery AI is that drug pharmacokinetic (PK) datasets are often collected independently from each other, often with limited overlap, creating data overlap sparsity. Data sparsity makes data curation difficult for researchers looking to answer research questions in poly-pharmacy, drug combination research, and high-throughput screening. We propose Imagand, a novel SMILES-to-Pharmacokinetic (S2PK) diffusion model capable of generating an array of PK target properties conditioned on SMILES inputs. We show that Imagand-generated synthetic PK data closely resembles real data univariate and bivariate distributions, and improves performance for downstream tasks. Imagand is a promising solution for data overlap sparsity and allows researchers to efficiently generate ligand PK data for drug discovery research. Code is available at \url{https://github.com/bing1100/Imagand}.
Synthetic Data from Diffusion Models Improve Drug Discovery Prediction
May 06, 2024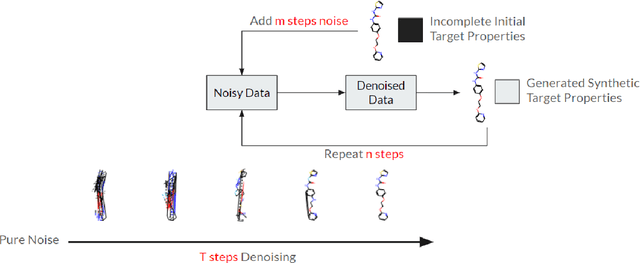

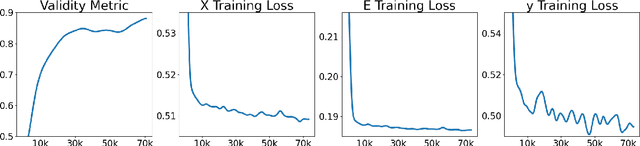
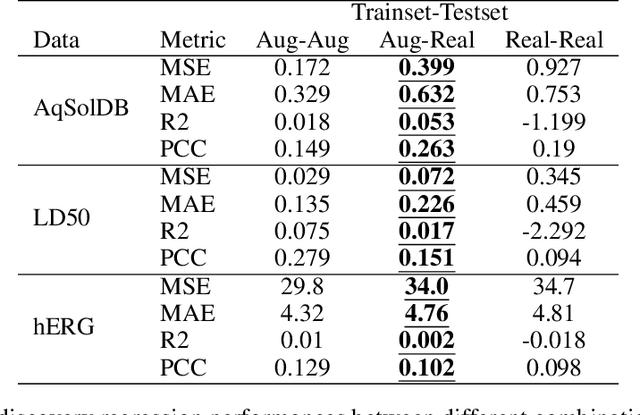
Artificial intelligence (AI) is increasingly used in every stage of drug development. Continuing breakthroughs in AI-based methods for drug discovery require the creation, improvement, and refinement of drug discovery data. We posit a new data challenge that slows the advancement of drug discovery AI: datasets are often collected independently from each other, often with little overlap, creating data sparsity. Data sparsity makes data curation difficult for researchers looking to answer key research questions requiring values posed across multiple datasets. We propose a novel diffusion GNN model Syngand capable of generating ligand and pharmacokinetic data end-to-end. We show and provide a methodology for sampling pharmacokinetic data for existing ligands using our Syngand model. We show the initial promising results on the efficacy of the Syngand-generated synthetic target property data on downstream regression tasks with AqSolDB, LD50, and hERG central. Using our proposed model and methodology, researchers can easily generate synthetic ligand data to help them explore research questions that require data spanning multiple datasets.
Proposing a conceptual framework: social media listening for public health behavior
Jul 30, 2023



Existing communications and behavioral theories have been adopted to address health misinformation. Although various theories and models have been used to investigate the COVID-19 pandemic, there is no framework specially designed for social listening or misinformation studies using social media data and natural language processing techniques. This study aimed to propose a novel yet theory-based conceptual framework for misinformation research. We collected theories and models used in COVID-19 related studies published in peer-reviewed journals. The theories and models ranged from health behaviors, communications, to misinformation. They are analyzed and critiqued for their components, followed by proposing a conceptual framework with a demonstration. We reviewed Health Belief Model, Theory of Planned Behavior/Reasoned Action, Communication for Behavioral Impact, Transtheoretical Model, Uses and Gratifications Theory, Social Judgment Theory, Risk Information Seeking and Processing Model, Behavioral and Social Drivers, and Hype Loop. Accordingly, we proposed the Social Media Listening for Public Health Behavior Conceptual Framework by not only integrating important attributes of existing theories, but also adding new attributes. The proposed conceptual framework was demonstrated in the Freedom Convoy social media listening. The proposed conceptual framework can be used to better understand public discourse on social media, and it can be integrated with other data analyses to gather a more comprehensive picture. The framework will continue to be revised and adopted as health misinformation evolves.
ICDBigBird: A Contextual Embedding Model for ICD Code Classification
Apr 21, 2022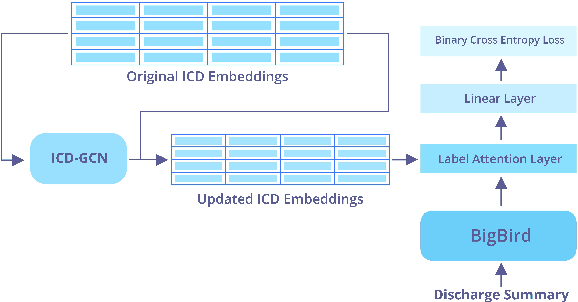
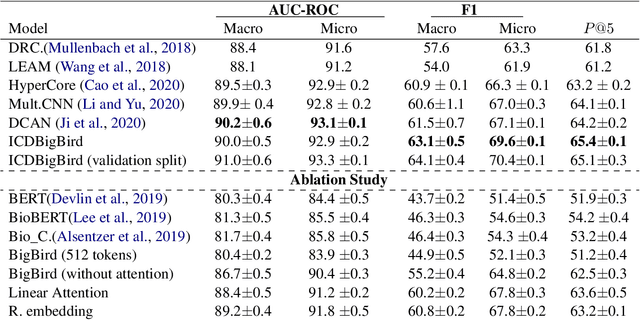
The International Classification of Diseases (ICD) system is the international standard for classifying diseases and procedures during a healthcare encounter and is widely used for healthcare reporting and management purposes. Assigning correct codes for clinical procedures is important for clinical, operational, and financial decision-making in healthcare. Contextual word embedding models have achieved state-of-the-art results in multiple NLP tasks. However, these models have yet to achieve state-of-the-art results in the ICD classification task since one of their main disadvantages is that they can only process documents that contain a small number of tokens which is rarely the case with real patient notes. In this paper, we introduce ICDBigBird a BigBird-based model which can integrate a Graph Convolutional Network (GCN), that takes advantage of the relations between ICD codes in order to create 'enriched' representations of their embeddings, with a BigBird contextual model that can process larger documents. Our experiments on a real-world clinical dataset demonstrate the effectiveness of our BigBird-based model on the ICD classification task as it outperforms the previous state-of-the-art models.
Cohort Characteristics and Factors Associated with Cannabis Use among Adolescents in Canada Using Pattern Discovery and Disentanglement Method
Sep 03, 2021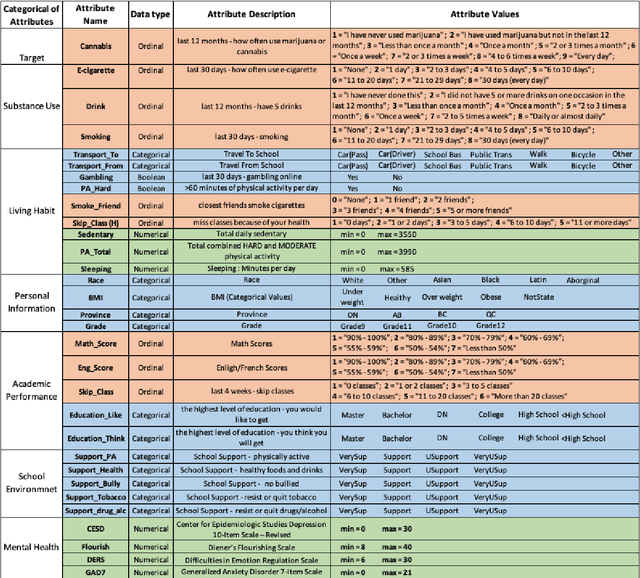
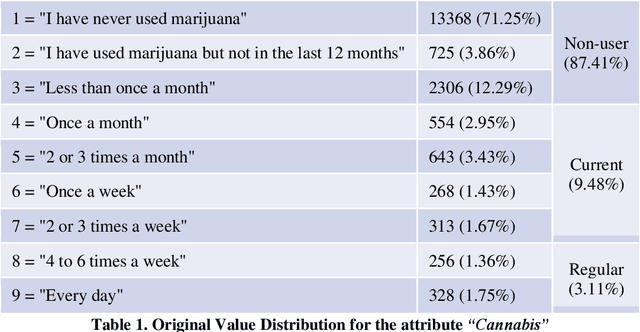


COMPASS is a longitudinal, prospective cohort study collecting data annually from students attending high school in jurisdictions across Canada. We aimed to discover significant frequent/rare associations of behavioral factors among Canadian adolescents related to cannabis use. We use a subset of COMPASS dataset which contains 18,761 records of students in grades 9 to 12 with 31 selected features (attributes) involving various characteristics, from living habits to academic performance. We then used the Pattern Discovery and Disentanglement (PDD) algorithm that we have developed to detect strong and rare (yet statistically significant) associations from the dataset. PDD used the criteria derived from disentangled statistical spaces (known as Re-projected Adjusted-Standardized Residual Vector Spaces, notated as RARV). It outperformed methods using other criteria (i.e. support and confidence) popular as reported in the literature. Association results showed that PDD can discover: i) a smaller set of succinct significant associations in clusters; ii) frequent and rare, yet significant, patterns supported by population health relevant study; iii) patterns from a dataset with extremely imbalanced groups (majority class: minority class = 88.3%: 11.7%).
LexSubCon: Integrating Knowledge from Lexical Resources into Contextual Embeddings for Lexical Substitution
Jul 11, 2021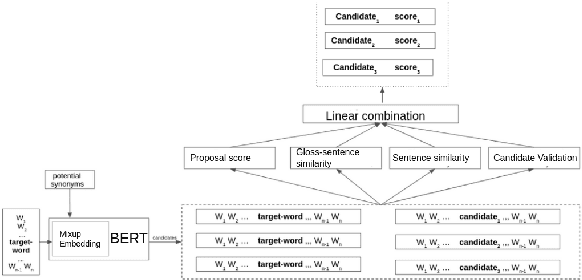
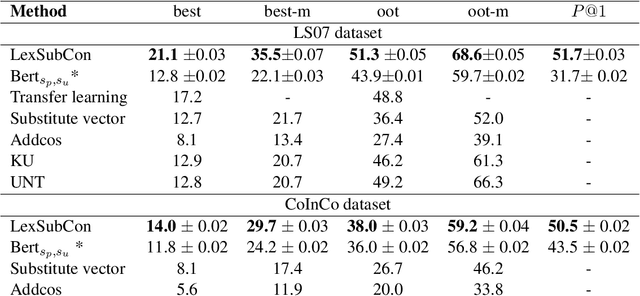
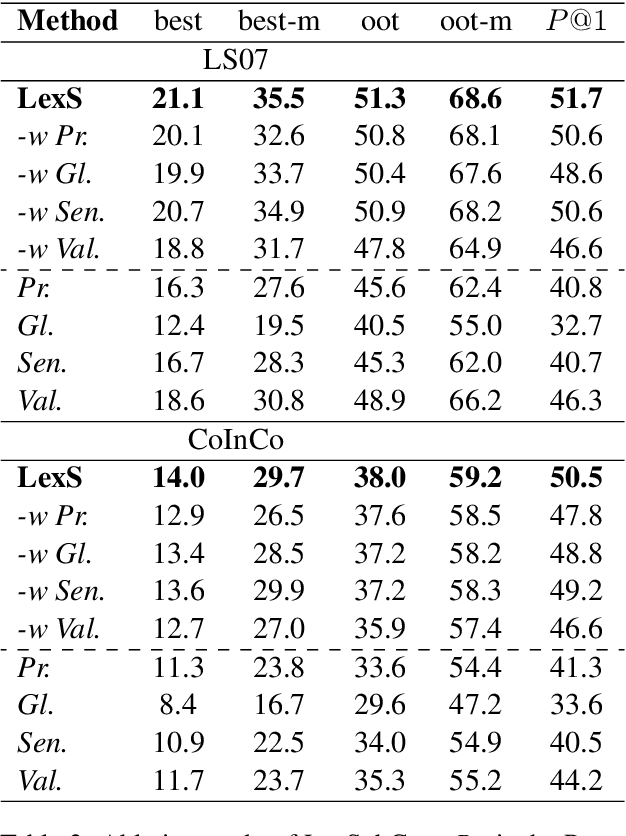
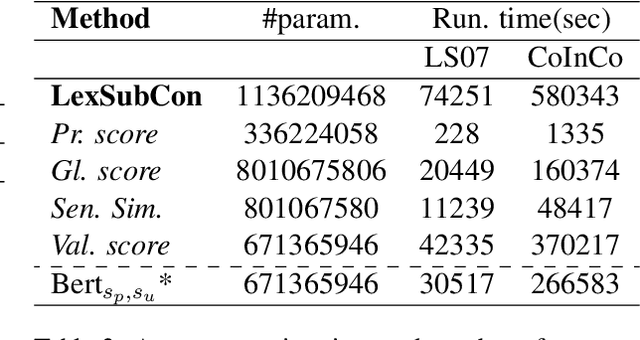
Lexical substitution is the task of generating meaningful substitutes for a word in a given textual context. Contextual word embedding models have achieved state-of-the-art results in the lexical substitution task by relying on contextual information extracted from the replaced word within the sentence. However, such models do not take into account structured knowledge that exists in external lexical databases. We introduce LexSubCon, an end-to-end lexical substitution framework based on contextual embedding models that can identify highly accurate substitute candidates. This is achieved by combining contextual information with knowledge from structured lexical resources. Our approach involves: (i) introducing a novel mix-up embedding strategy in the creation of the input embedding of the target word through linearly interpolating the pair of the target input embedding and the average embedding of its probable synonyms; (ii) considering the similarity of the sentence-definition embeddings of the target word and its proposed candidates; and, (iii) calculating the effect of each substitution in the semantics of the sentence through a fine-tuned sentence similarity model. Our experiments show that LexSubCon outperforms previous state-of-the-art methods on LS07 and CoInCo benchmark datasets that are widely used for lexical substitution tasks.
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
Oct 20, 2020
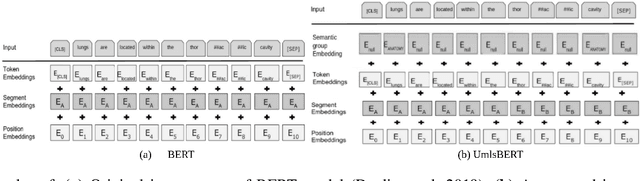
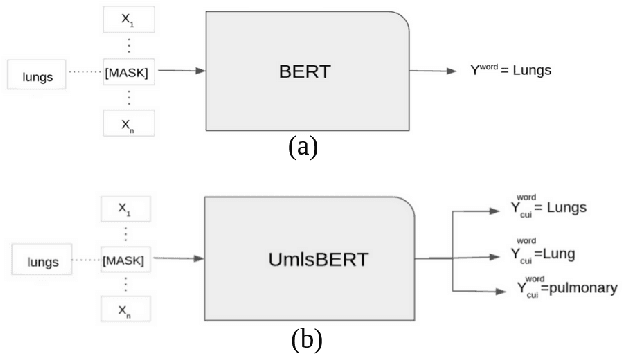
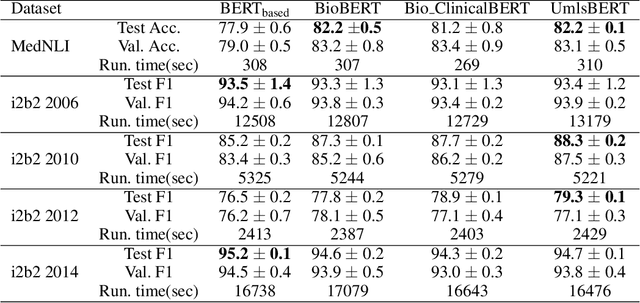
Contextual word embedding models, such as BioBERT and Bio_ClinicalBERT, have achieved state-of-the-art results in biomedical natural language processing tasks by focusing their pre-training process on domain-specific corpora. However, such models do not take into consideration expert domain knowledge. In this work, we introduced UmlsBERT, a contextual embedding model that integrates domain knowledge during the pre-training process via a novel knowledge augmentation strategy. More specifically, the augmentation on UmlsBERT with the Unified Medical Language System (UMLS) Metathesaurus was performed in two ways: i) connecting words that have the same underlying `concept' in UMLS, and ii) leveraging semantic group knowledge in UMLS to create clinically meaningful input embeddings. By applying these two strategies, UmlsBERT can encode clinical domain knowledge into word embeddings and outperform existing domain-specific models on common named-entity recognition (NER) and clinical natural language inference clinical NLP tasks.
Where's the Question? A Multi-channel Deep Convolutional Neural Network for Question Identification in Textual Data
Oct 15, 2020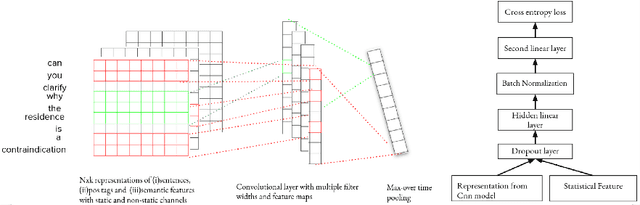
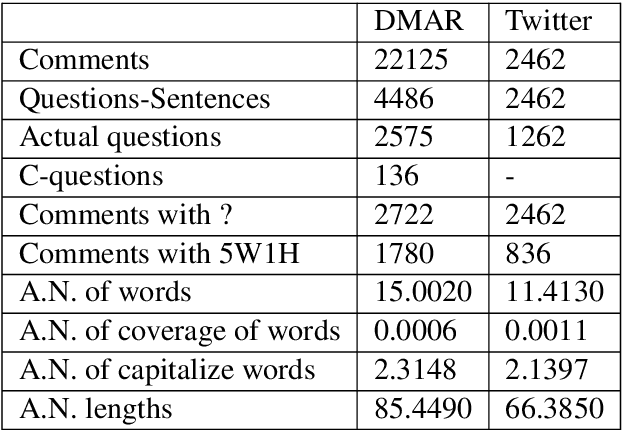
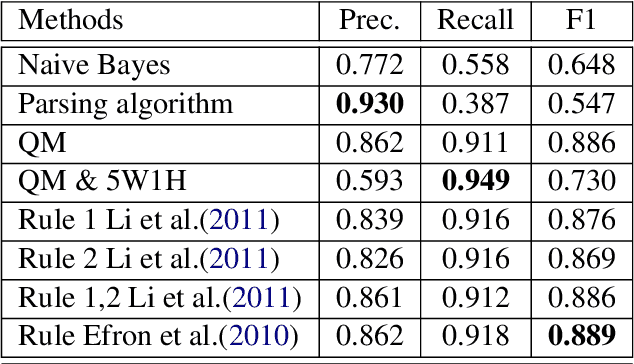
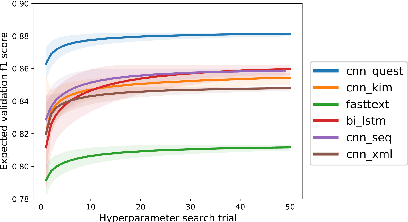
In most clinical practice settings, there is no rigorous reviewing of the clinical documentation, resulting in inaccurate information captured in the patient medical records. The gold standard in clinical data capturing is achieved via "expert-review", where clinicians can have a dialogue with a domain expert (reviewers) and ask them questions about data entry rules. Automatically identifying "real questions" in these dialogues could uncover ambiguities or common problems in data capturing in a given clinical setting. In this study, we proposed a novel multi-channel deep convolutional neural network architecture, namely Quest-CNN, for the purpose of separating real questions that expect an answer (information or help) about an issue from sentences that are not questions, as well as from questions referring to an issue mentioned in a nearby sentence (e.g., can you clarify this?), which we will refer as "c-questions". We conducted a comprehensive performance comparison analysis of the proposed multi-channel deep convolutional neural network against other deep neural networks. Furthermore, we evaluated the performance of traditional rule-based and learning-based methods for detecting question sentences. The proposed Quest-CNN achieved the best F1 score both on a dataset of data entry-review dialogue in a dialysis care setting, and on a general domain dataset.