 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrug Discovery SMILES-to-Pharmacokinetics Diffusion Models with Deep Molecular Understanding
Aug 14, 2024Artificial intelligence (AI) is increasingly used in every stage of drug development. One challenge facing drug discovery AI is that drug pharmacokinetic (PK) datasets are often collected independently from each other, often with limited overlap, creating data overlap sparsity. Data sparsity makes data curation difficult for researchers looking to answer research questions in poly-pharmacy, drug combination research, and high-throughput screening. We propose Imagand, a novel SMILES-to-Pharmacokinetic (S2PK) diffusion model capable of generating an array of PK target properties conditioned on SMILES inputs. We show that Imagand-generated synthetic PK data closely resembles real data univariate and bivariate distributions, and improves performance for downstream tasks. Imagand is a promising solution for data overlap sparsity and allows researchers to efficiently generate ligand PK data for drug discovery research. Code is available at \url{https://github.com/bing1100/Imagand}.
Synthetic Data from Diffusion Models Improve Drug Discovery Prediction
May 06, 2024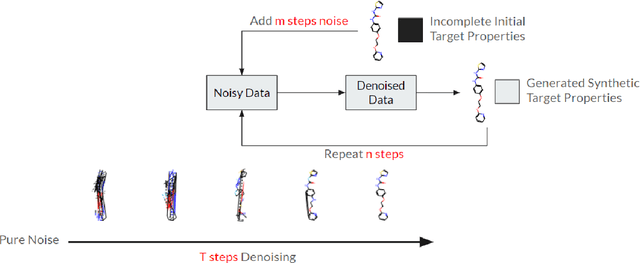

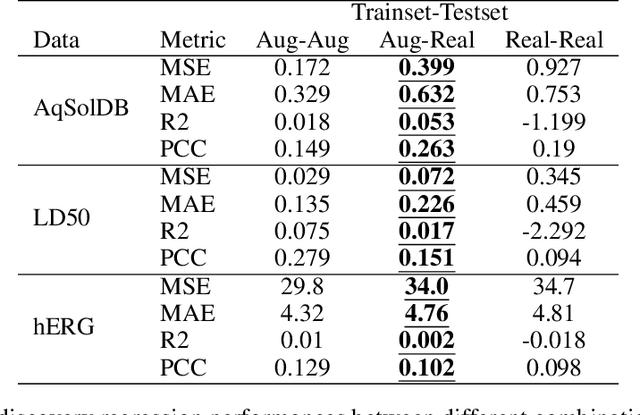
Artificial intelligence (AI) is increasingly used in every stage of drug development. Continuing breakthroughs in AI-based methods for drug discovery require the creation, improvement, and refinement of drug discovery data. We posit a new data challenge that slows the advancement of drug discovery AI: datasets are often collected independently from each other, often with little overlap, creating data sparsity. Data sparsity makes data curation difficult for researchers looking to answer key research questions requiring values posed across multiple datasets. We propose a novel diffusion GNN model Syngand capable of generating ligand and pharmacokinetic data end-to-end. We show and provide a methodology for sampling pharmacokinetic data for existing ligands using our Syngand model. We show the initial promising results on the efficacy of the Syngand-generated synthetic target property data on downstream regression tasks with AqSolDB, LD50, and hERG central. Using our proposed model and methodology, researchers can easily generate synthetic ligand data to help them explore research questions that require data spanning multiple datasets.