 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-to-Image: Zero-Shot Depth Estimation in Colonoscopy via High-Fidelity Sim-to-Real Adaptation
Feb 25, 2026Monocular depth estimation (MDE) for colonoscopy is hampered by the domain gap between simulated and real-world images. Existing image-to-image translation methods, which use depth as a posterior constraint, often produce structural distortions and specular highlights by failing to balance realism with structure consistency. To address this, we propose a Structure-to-Image paradigm that transforms the depth map from a passive constraint into an active generative foundation. We are the first to introduce phase congruency to colonoscopic domain adaptation and design a cross-level structure constraint to co-optimize geometric structures and fine-grained details like vascular textures. In zero-shot evaluations conducted on a publicly available phantom dataset, the MDE model that was fine-tuned on our generated data achieved a maximum reduction of 44.18% in RMSE compared to competing methods. Our code is available at https://github.com/YyangJJuan/PC-S2I.git.
Global Prior Meets Local Consistency: Dual-Memory Augmented Vision-Language-Action Model for Efficient Robotic Manipulation
Feb 22, 2026Hierarchical Vision-Language-Action (VLA) models have rapidly become a dominant paradigm for robotic manipulation. It typically comprising a Vision-Language backbone for perception and understanding, together with a generative policy for action generation. However, its performance is increasingly bottlenecked by the action generation proceess. (i) Low inference efficiency. A pronounced distributional gap between isotropic noise priors and target action distributions, which increases denoising steps and the incidence of infeasible samples. (ii) Poor robustness. Existing policies condition solely on the current observation, neglecting the constraint of history sequence and thus lacking awareness of task progress and temporal consistency. To address these issues, we introduce OptimusVLA, a dual-memory VLA framework with Global Prior Memory (GPM) and Local Consistency Memory (LCM). GPM replaces Gaussian noise with task-level priors retrieved from semantically similar trajectories, thereby shortening the generative path and reducing the umber of function evaluations (NFE). LCM dynamically models executed action sequence to infer task progress and injects a learned consistency constraint that enforces temporal coherence and smoothness of trajectory. Across three simulation benchmarks, OptimusVLA consistently outperforms strong baselines: it achieves 98.6% average success rate on LIBERO, improves over pi_0 by 13.5% on CALVIN, and attains 38% average success rate on RoboTwin 2.0 Hard. In Real-World evaluation, OptimusVLA ranks best on Generalization and Long-horizon suites, surpassing pi_0 by 42.9% and 52.4%, respectively, while delivering 2.9x inference speedup.
SynQP: A Framework and Metrics for Evaluating the Quality and Privacy Risk of Synthetic Data
Jan 17, 2026The use of synthetic data in health applications raises privacy concerns, yet the lack of open frameworks for privacy evaluations has slowed its adoption. A major challenge is the absence of accessible benchmark datasets for evaluating privacy risks, due to difficulties in acquiring sensitive data. To address this, we introduce SynQP, an open framework for benchmarking privacy in synthetic data generation (SDG) using simulated sensitive data, ensuring that original data remains confidential. We also highlight the need for privacy metrics that fairly account for the probabilistic nature of machine learning models. As a demonstration, we use SynQP to benchmark CTGAN and propose a new identity disclosure risk metric that offers a more accurate estimation of privacy risks compared to existing approaches. Our work provides a critical tool for improving the transparency and reliability of privacy evaluations, enabling safer use of synthetic data in health-related applications. % In our quality evaluations, non-private models achieved near-perfect machine-learning efficacy \(\ge0.97\). Our privacy assessments (Table II) reveal that DP consistently lowers both identity disclosure risk (SD-IDR) and membership-inference attack risk (SD-MIA), with all DP-augmented models staying below the 0.09 regulatory threshold. Code available at https://github.com/CAN-SYNH/SynQP
* 7 Pages, 22nd Annual International Conference on Privacy, Security, and Trust (PST2025), Fredericton, Canada
LION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant
Mar 05, 2025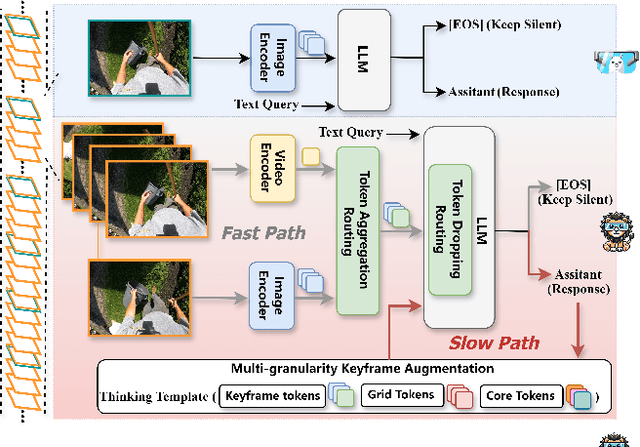
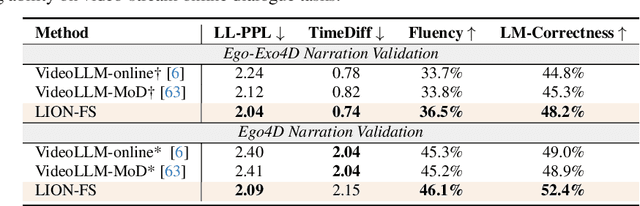
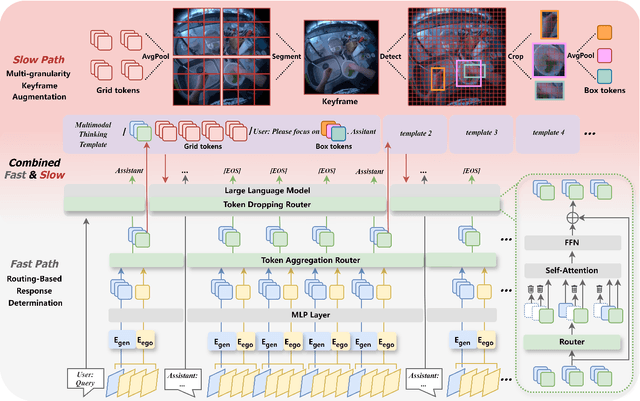
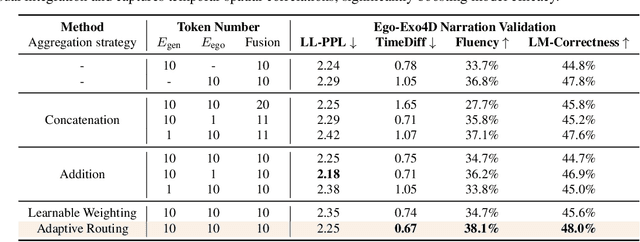
First-person video assistants are highly anticipated to enhance our daily lives through online video dialogue. However, existing online video assistants often sacrifice assistant efficacy for real-time efficiency by processing low-frame-rate videos with coarse-grained visual features.To overcome the trade-off between efficacy and efficiency, we propose "Fast & Slow Video-Language Thinker" as an onLIne videO assistaNt, LION-FS, achieving real-time, proactive, temporally accurate, and contextually precise responses. LION-FS adopts a two-stage optimization strategy: 1)Fast Path: Routing-Based Response Determination evaluates frame-by-frame whether an immediate response is necessary. To enhance response determination accuracy and handle higher frame-rate inputs efficiently, we employ Token Aggregation Routing to dynamically fuse spatiotemporal features without increasing token numbers, while utilizing Token Dropping Routing to eliminate redundant features. 2)Slow Path: Multi-granularity Keyframe Augmentation optimizes keyframes during response generation. To provide comprehensive and detailed responses beyond atomic actions constrained by training data, fine-grained spatial features and human-environment interaction features are extracted through multi-granular pooling. These features are further integrated into a meticulously designed multimodal Thinking Template to guide more precise response generation. Comprehensive evaluations on online video tasks demonstrate that LION-FS achieves state-of-the-art efficacy and efficiency.
Drug Discovery SMILES-to-Pharmacokinetics Diffusion Models with Deep Molecular Understanding
Aug 14, 2024Artificial intelligence (AI) is increasingly used in every stage of drug development. One challenge facing drug discovery AI is that drug pharmacokinetic (PK) datasets are often collected independently from each other, often with limited overlap, creating data overlap sparsity. Data sparsity makes data curation difficult for researchers looking to answer research questions in poly-pharmacy, drug combination research, and high-throughput screening. We propose Imagand, a novel SMILES-to-Pharmacokinetic (S2PK) diffusion model capable of generating an array of PK target properties conditioned on SMILES inputs. We show that Imagand-generated synthetic PK data closely resembles real data univariate and bivariate distributions, and improves performance for downstream tasks. Imagand is a promising solution for data overlap sparsity and allows researchers to efficiently generate ligand PK data for drug discovery research. Code is available at \url{https://github.com/bing1100/Imagand}.
Bug In the Code Stack: Can LLMs Find Bugs in Large Python Code Stacks
Jun 21, 2024Recent research in Needle-in-a-Haystack (NIAH) benchmarks has explored the capabilities of Large Language Models (LLMs) in retrieving contextual information from large text documents. However, as LLMs become increasingly integrated into software development processes, it is crucial to evaluate their performance in code-based environments. As LLMs are further developed for program synthesis, we need to ensure that LLMs can understand syntax and write syntactically correct code. As a step in ensuring LLMs understand syntax, LLMs can be evaluated in their ability to find and detect syntax bugs. Our benchmark, Bug In The Code Stack (BICS), is designed to assess the ability of LLMs to identify simple syntax bugs within large source code. Our findings reveal three key insights: (1) code-based environments pose significantly more challenge compared to text-based environments for retrieval tasks, (2) there is a substantial performance disparity among different models, and (3) there is a notable correlation between longer context lengths and performance degradation, though the extent of this degradation varies between models.
The Solution for CVPR2024 Foundational Few-Shot Object Detection Challenge
Jun 18, 2024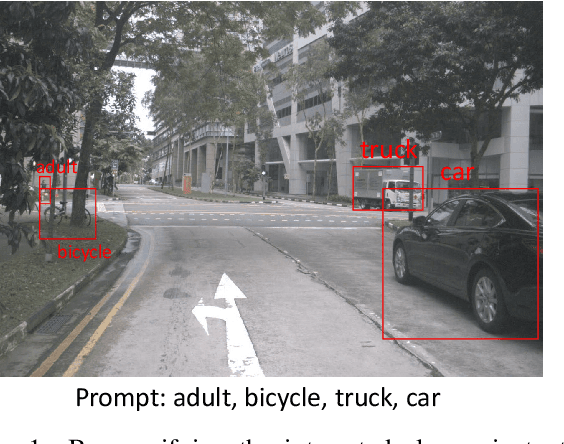
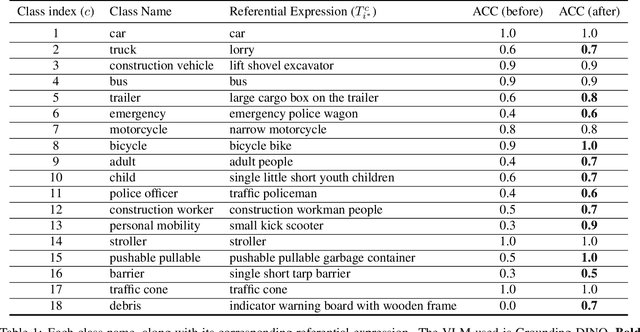
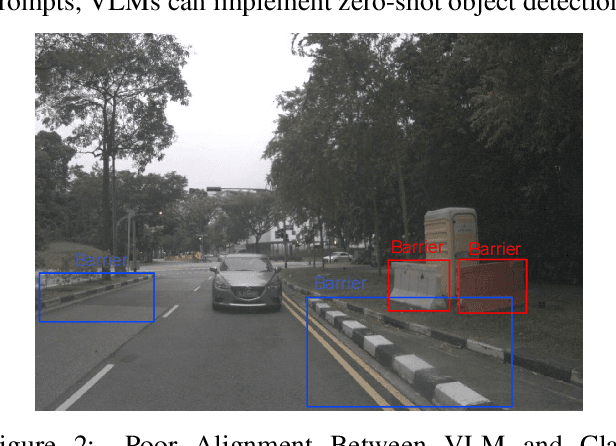
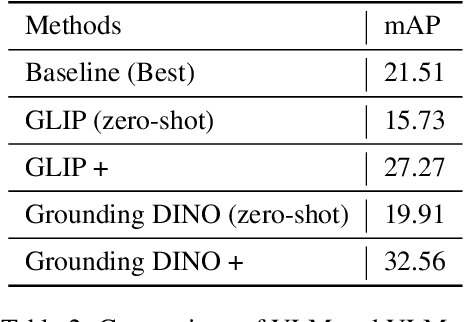
This report introduces an enhanced method for the Foundational Few-Shot Object Detection (FSOD) task, leveraging the vision-language model (VLM) for object detection. However, on specific datasets, VLM may encounter the problem where the detected targets are misaligned with the target concepts of interest. This misalignment hinders the zero-shot performance of VLM and the application of fine-tuning methods based on pseudo-labels. To address this issue, we propose the VLM+ framework, which integrates the multimodal large language model (MM-LLM). Specifically, we use MM-LLM to generate a series of referential expressions for each category. Based on the VLM predictions and the given annotations, we select the best referential expression for each category by matching the maximum IoU. Subsequently, we use these referential expressions to generate pseudo-labels for all images in the training set and then combine them with the original labeled data to fine-tune the VLM. Additionally, we employ iterative pseudo-label generation and optimization to further enhance the performance of the VLM. Our approach achieve 32.56 mAP in the final test.
Synthetic Data from Diffusion Models Improve Drug Discovery Prediction
May 06, 2024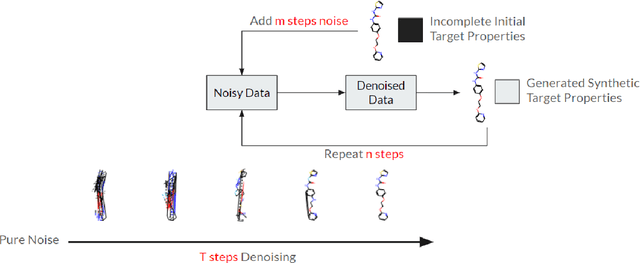

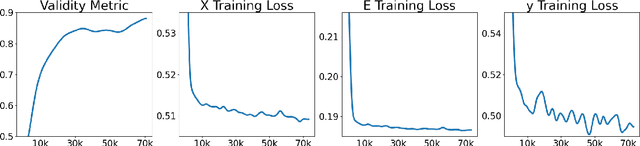
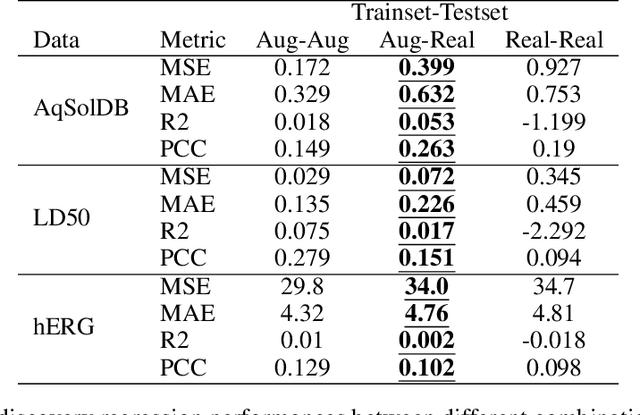
Artificial intelligence (AI) is increasingly used in every stage of drug development. Continuing breakthroughs in AI-based methods for drug discovery require the creation, improvement, and refinement of drug discovery data. We posit a new data challenge that slows the advancement of drug discovery AI: datasets are often collected independently from each other, often with little overlap, creating data sparsity. Data sparsity makes data curation difficult for researchers looking to answer key research questions requiring values posed across multiple datasets. We propose a novel diffusion GNN model Syngand capable of generating ligand and pharmacokinetic data end-to-end. We show and provide a methodology for sampling pharmacokinetic data for existing ligands using our Syngand model. We show the initial promising results on the efficacy of the Syngand-generated synthetic target property data on downstream regression tasks with AqSolDB, LD50, and hERG central. Using our proposed model and methodology, researchers can easily generate synthetic ligand data to help them explore research questions that require data spanning multiple datasets.
Restricted Deformable Convolution based Road Scene Semantic Segmentation Using Surround View Cameras
Jan 03, 2018
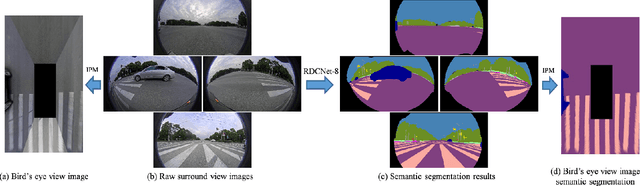

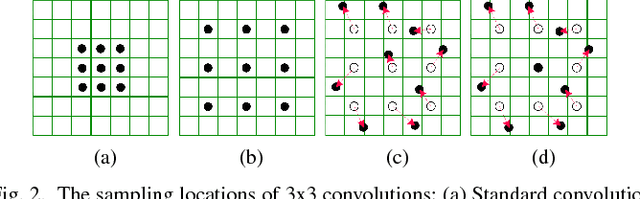
Understanding the surrounding environment of the vehicle is still one of the challenges for autonomous driving. This paper addresses 360-degree road scene semantic segmentation using surround view cameras, which are widely equipped in existing production cars. First, in order to address large distortion problem in the fisheye images, Restricted Deformable Convolution (RDC) is proposed for semantic segmentation, which can effectively model geometric transformations by learning the shapes of convolutional filters conditioned on the input feature map. Second, in order to obtain a large-scale training set of surround view images, a novel method called zoom augmentation is proposed to transform conventional images to fisheye images. Finally, an RDC based semantic segmentation model is built. The model is trained for real-world surround view images through a multi-task learning architecture by combining real-world images with transformed images. Experiments demonstrate the effectiveness of the RDC to handle images with large distortions, and the proposed approach shows a good performance using surround view cameras with the help of the transformed images.