 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant
Paper and Code
Mar 05, 2025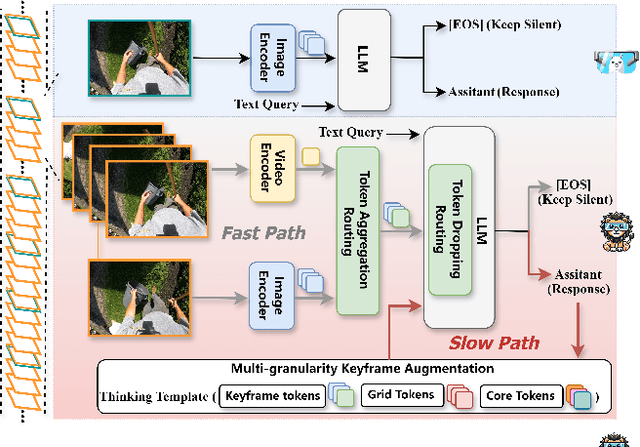
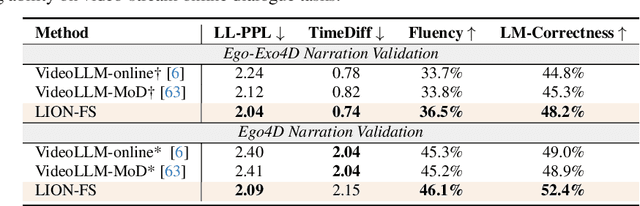
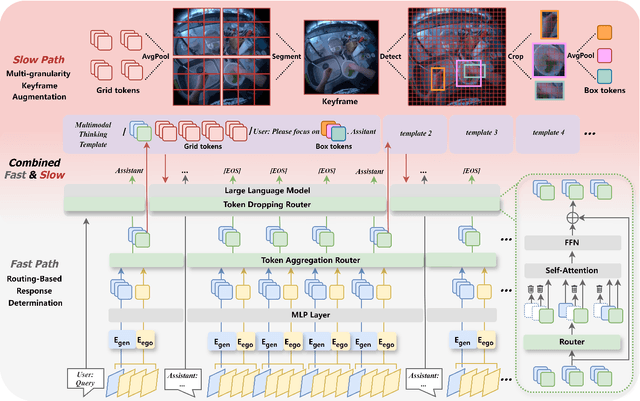
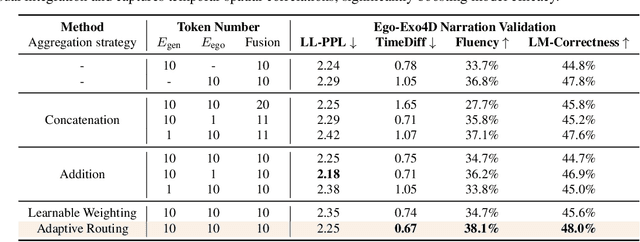
First-person video assistants are highly anticipated to enhance our daily lives through online video dialogue. However, existing online video assistants often sacrifice assistant efficacy for real-time efficiency by processing low-frame-rate videos with coarse-grained visual features.To overcome the trade-off between efficacy and efficiency, we propose "Fast & Slow Video-Language Thinker" as an onLIne videO assistaNt, LION-FS, achieving real-time, proactive, temporally accurate, and contextually precise responses. LION-FS adopts a two-stage optimization strategy: 1)Fast Path: Routing-Based Response Determination evaluates frame-by-frame whether an immediate response is necessary. To enhance response determination accuracy and handle higher frame-rate inputs efficiently, we employ Token Aggregation Routing to dynamically fuse spatiotemporal features without increasing token numbers, while utilizing Token Dropping Routing to eliminate redundant features. 2)Slow Path: Multi-granularity Keyframe Augmentation optimizes keyframes during response generation. To provide comprehensive and detailed responses beyond atomic actions constrained by training data, fine-grained spatial features and human-environment interaction features are extracted through multi-granular pooling. These features are further integrated into a meticulously designed multimodal Thinking Template to guide more precise response generation. Comprehensive evaluations on online video tasks demonstrate that LION-FS achieves state-of-the-art efficacy and efficiency.