 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
LION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant
Mar 05, 2025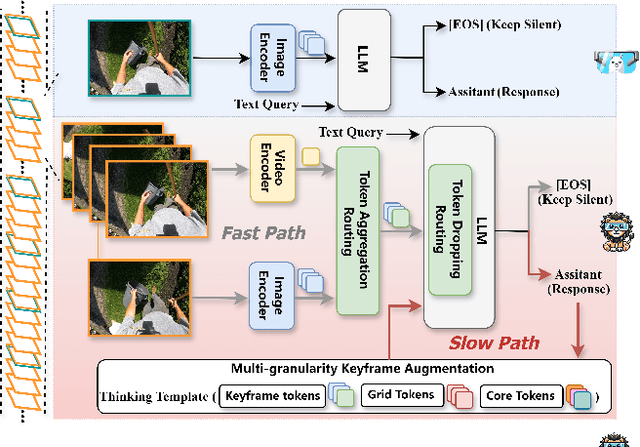
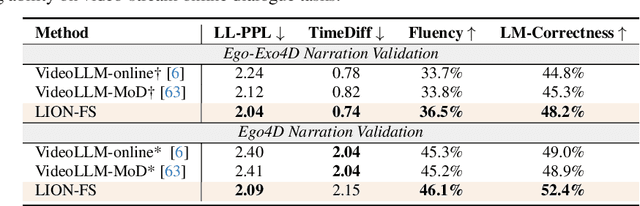
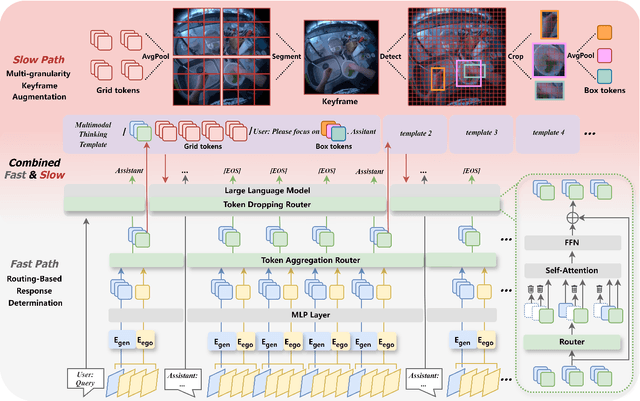
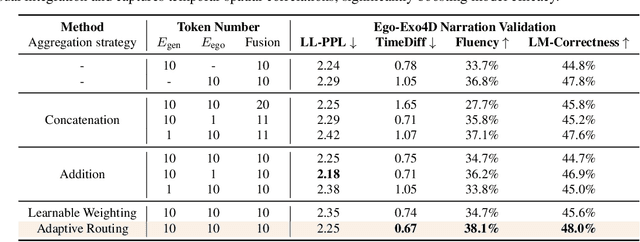
First-person video assistants are highly anticipated to enhance our daily lives through online video dialogue. However, existing online video assistants often sacrifice assistant efficacy for real-time efficiency by processing low-frame-rate videos with coarse-grained visual features.To overcome the trade-off between efficacy and efficiency, we propose "Fast & Slow Video-Language Thinker" as an onLIne videO assistaNt, LION-FS, achieving real-time, proactive, temporally accurate, and contextually precise responses. LION-FS adopts a two-stage optimization strategy: 1)Fast Path: Routing-Based Response Determination evaluates frame-by-frame whether an immediate response is necessary. To enhance response determination accuracy and handle higher frame-rate inputs efficiently, we employ Token Aggregation Routing to dynamically fuse spatiotemporal features without increasing token numbers, while utilizing Token Dropping Routing to eliminate redundant features. 2)Slow Path: Multi-granularity Keyframe Augmentation optimizes keyframes during response generation. To provide comprehensive and detailed responses beyond atomic actions constrained by training data, fine-grained spatial features and human-environment interaction features are extracted through multi-granular pooling. These features are further integrated into a meticulously designed multimodal Thinking Template to guide more precise response generation. Comprehensive evaluations on online video tasks demonstrate that LION-FS achieves state-of-the-art efficacy and efficiency.
MoME: Mixture of Multimodal Experts for Generalist Multimodal Large Language Models
Jul 17, 2024Multimodal large language models (MLLMs) have demonstrated impressive capabilities across various vision-language tasks. However, a generalist MLLM typically underperforms compared with a specialist MLLM on most VL tasks, which can be attributed to task interference. In this paper, we propose a mixture of multimodal experts (MoME) to mitigate task interference and obtain a generalist MLLM. Our MoME is composed of two key components, a mixture of vision experts (MoVE) and a mixture of language experts (MoLE). MoVE can adaptively modulate the features transformed from various vision encoders, and has a strong compatibility in transformation architecture. MoLE incorporates sparsely gated experts into LLMs to achieve painless improvements with roughly unchanged inference costs. In response to task interference, our MoME specializes in both vision and language modality to adapt to task discrepancies. Extensive experiments show that MoME significantly improves the performance of generalist MLLMs across various VL tasks. The source code is released at https://github.com/JiuTian-VL/MoME
LION : Empowering Multimodal Large Language Model with Dual-Level Visual Knowledge
Nov 26, 2023



Multimodal Large Language Models (MLLMs) have endowed LLMs with the ability to perceive and understand multi-modal signals. However, most of the existing MLLMs mainly adopt vision encoders pretrained on coarsely aligned image-text pairs, leading to insufficient extraction and reasoning of visual knowledge. To address this issue, we devise a dual-Level vIsual knOwledge eNhanced Multimodal Large Language Model (LION), which empowers the MLLM by injecting visual knowledge in two levels. 1) Progressive incorporation of fine-grained spatial-aware visual knowledge. We design a vision aggregator cooperated with region-level vision-language (VL) tasks to incorporate fine-grained spatial-aware visual knowledge into the MLLM. To alleviate the conflict between image-level and region-level VL tasks during incorporation, we devise a dedicated stage-wise instruction-tuning strategy with mixture-of-adapters. This progressive incorporation scheme contributes to the mutual promotion between these two kinds of VL tasks. 2) Soft prompting of high-level semantic visual evidence. We facilitate the MLLM with high-level semantic visual evidence by leveraging diverse image tags. To mitigate the potential influence caused by imperfect predicted tags, we propose a soft prompting method by embedding a learnable token into the tailored text instruction. Comprehensive experiments on several multi-modal benchmarks demonstrate the superiority of our model (e.g., improvement of 5% accuracy on VSR and 3% CIDEr on TextCaps over InstructBLIP, 5% accuracy on RefCOCOg over Kosmos-2).