 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHATS: Hardness-Aware Trajectory Synthesis for GUI Agents
Mar 12, 2026Graphical user interface (GUI) agents powered by large vision-language models (VLMs) have shown remarkable potential in automating digital tasks, highlighting the need for high-quality trajectory data to support effective agent training. Yet existing trajectory synthesis pipelines often yield agents that fail to generalize beyond simple interactions. We identify this limitation as stemming from the neglect of semantically ambiguous actions, whose meanings are context-dependent, sequentially dependent, or visually ambiguous. Such actions are crucial for real-world robustness but are under-represented and poorly processed in current datasets, leading to semantic misalignment between task instructions and execution. To address these issues, we propose HATS, a Hardness-Aware Trajectory Synthesis framework designed to mitigate the impact of semantic ambiguity. We define hardness as the degree of semantic ambiguity associated with an action and develop two complementary modules: (1) hardness-driven exploration, which guides data collection toward ambiguous yet informative interactions, and (2) alignment-guided refinement, which iteratively validates and repairs instruction-execution alignment. The two modules operate in a closed loop: exploration supplies refinement with challenging trajectories, while refinement feedback updates the hardness signal to guide future exploration. Extensive experiments show that agents trained with HATS consistently outperform state-of-the-art baselines across benchmark GUI environments.
Global Prior Meets Local Consistency: Dual-Memory Augmented Vision-Language-Action Model for Efficient Robotic Manipulation
Feb 22, 2026Hierarchical Vision-Language-Action (VLA) models have rapidly become a dominant paradigm for robotic manipulation. It typically comprising a Vision-Language backbone for perception and understanding, together with a generative policy for action generation. However, its performance is increasingly bottlenecked by the action generation proceess. (i) Low inference efficiency. A pronounced distributional gap between isotropic noise priors and target action distributions, which increases denoising steps and the incidence of infeasible samples. (ii) Poor robustness. Existing policies condition solely on the current observation, neglecting the constraint of history sequence and thus lacking awareness of task progress and temporal consistency. To address these issues, we introduce OptimusVLA, a dual-memory VLA framework with Global Prior Memory (GPM) and Local Consistency Memory (LCM). GPM replaces Gaussian noise with task-level priors retrieved from semantically similar trajectories, thereby shortening the generative path and reducing the umber of function evaluations (NFE). LCM dynamically models executed action sequence to infer task progress and injects a learned consistency constraint that enforces temporal coherence and smoothness of trajectory. Across three simulation benchmarks, OptimusVLA consistently outperforms strong baselines: it achieves 98.6% average success rate on LIBERO, improves over pi_0 by 13.5% on CALVIN, and attains 38% average success rate on RoboTwin 2.0 Hard. In Real-World evaluation, OptimusVLA ranks best on Generalization and Long-horizon suites, surpassing pi_0 by 42.9% and 52.4%, respectively, while delivering 2.9x inference speedup.
PersonalAlign: Hierarchical Implicit Intent Alignment for Personalized GUI Agent with Long-Term User-Centric Records
Jan 14, 2026While GUI agents have shown strong performance under explicit and completion instructions, real-world deployment requires aligning with users' more complex implicit intents. In this work, we highlight Hierarchical Implicit Intent Alignment for Personalized GUI Agent (PersonalAlign), a new agent task that requires agents to leverage long-term user records as persistent context to resolve omitted preferences in vague instructions and anticipate latent routines by user state for proactive assistance. To facilitate this study, we introduce AndroidIntent, a benchmark designed to evaluate agents' ability in resolving vague instructions and providing proactive suggestions through reasoning over long-term user records. We annotated 775 user-specific preferences and 215 routines from 20k long-term records across different users for evaluation. Furthermore, we introduce Hierarchical Intent Memory Agent (HIM-Agent), which maintains a continuously updating personal memory and hierarchically organizes user preferences and routines for personalization. Finally, we evaluate a range of GUI agents on AndroidIntent, including GPT-5, Qwen3-VL, and UI-TARS, further results show that HIM-Agent significantly improves both execution and proactive performance by 15.7% and 7.3%.
Optimus-3: Towards Generalist Multimodal Minecraft Agents with Scalable Task Experts
Jun 12, 2025



Recently, agents based on multimodal large language models (MLLMs) have achieved remarkable progress across various domains. However, building a generalist agent with capabilities such as perception, planning, action, grounding, and reflection in open-world environments like Minecraft remains challenges: insufficient domain-specific data, interference among heterogeneous tasks, and visual diversity in open-world settings. In this paper, we address these challenges through three key contributions. 1) We propose a knowledge-enhanced data generation pipeline to provide scalable and high-quality training data for agent development. 2) To mitigate interference among heterogeneous tasks, we introduce a Mixture-of-Experts (MoE) architecture with task-level routing. 3) We develop a Multimodal Reasoning-Augmented Reinforcement Learning approach to enhance the agent's reasoning ability for visual diversity in Minecraft. Built upon these innovations, we present Optimus-3, a general-purpose agent for Minecraft. Extensive experimental results demonstrate that Optimus-3 surpasses both generalist multimodal large language models and existing state-of-the-art agents across a wide range of tasks in the Minecraft environment. Project page: https://cybertronagent.github.io/Optimus-3.github.io/
Mirage-1: Augmenting and Updating GUI Agent with Hierarchical Multimodal Skills
Jun 12, 2025



Recent efforts to leverage the Multi-modal Large Language Model (MLLM) as GUI agents have yielded promising outcomes. However, these agents still struggle with long-horizon tasks in online environments, primarily due to insufficient knowledge and the inherent gap between offline and online domains. In this paper, inspired by how humans generalize knowledge in open-ended environments, we propose a Hierarchical Multimodal Skills (HMS) module to tackle the issue of insufficient knowledge. It progressively abstracts trajectories into execution skills, core skills, and ultimately meta-skills, providing a hierarchical knowledge structure for long-horizon task planning. To bridge the domain gap, we propose the Skill-Augmented Monte Carlo Tree Search (SA-MCTS) algorithm, which efficiently leverages skills acquired in offline environments to reduce the action search space during online tree exploration. Building on HMS, we propose Mirage-1, a multimodal, cross-platform, plug-and-play GUI agent. To validate the performance of Mirage-1 in real-world long-horizon scenarios, we constructed a new benchmark, AndroidLH. Experimental results show that Mirage-1 outperforms previous agents by 32\%, 19\%, 15\%, and 79\% on AndroidWorld, MobileMiniWob++, Mind2Web-Live, and AndroidLH, respectively. Project page: https://cybertronagent.github.io/Mirage-1.github.io/
D2AF: A Dual-Driven Annotation and Filtering Framework for Visual Grounding
May 30, 2025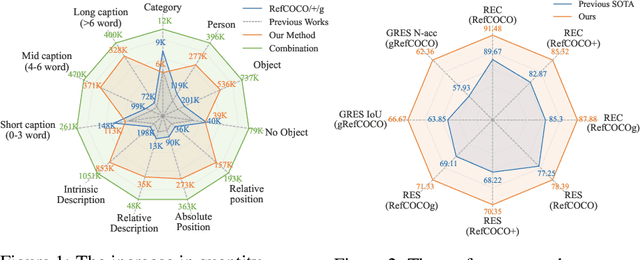
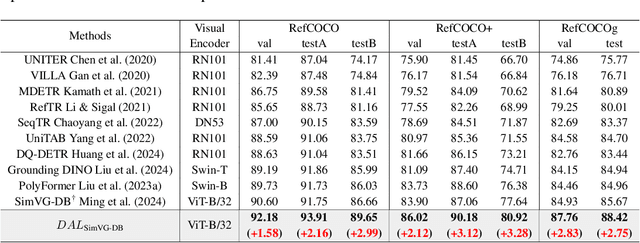
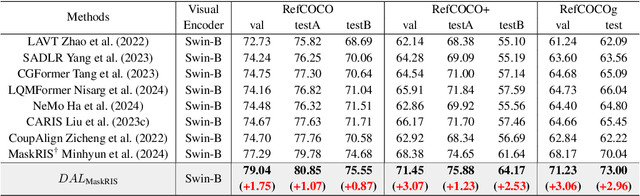
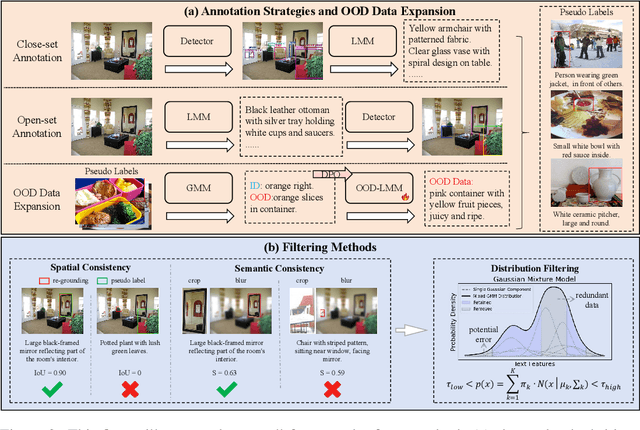
Visual Grounding is a task that aims to localize a target region in an image based on a free-form natural language description. With the rise of Transformer architectures, there is an increasing need for larger datasets to boost performance. However, the high cost of manual annotation poses a challenge, hindering the scale of data and the ability of large models to enhance their effectiveness. Previous pseudo label generation methods heavily rely on human-labeled captions of the original dataset, limiting scalability and diversity. To address this, we propose D2AF, a robust annotation framework for visual grounding using only input images. This approach overcomes dataset size limitations and enriches both the quantity and diversity of referring expressions. Our approach leverages multimodal large models and object detection models. By implementing dual-driven annotation strategies, we effectively generate detailed region-text pairs using both closed-set and open-set approaches. We further conduct an in-depth analysis of data quantity and data distribution. Our findings demonstrate that increasing data volume enhances model performance. However, the degree of improvement depends on how well the pseudo labels broaden the original data distribution. Based on these insights, we propose a consistency and distribution aware filtering method to further improve data quality by effectively removing erroneous and redundant data. This approach effectively eliminates noisy data, leading to improved performance. Experiments on three visual grounding tasks demonstrate that our method significantly improves the performance of existing models and achieves state-of-the-art results.
GUI-explorer: Autonomous Exploration and Mining of Transition-aware Knowledge for GUI Agent
May 22, 2025GUI automation faces critical challenges in dynamic environments. MLLMs suffer from two key issues: misinterpreting UI components and outdated knowledge. Traditional fine-tuning methods are costly for app-specific knowledge updates. We propose GUI-explorer, a training-free GUI agent that incorporates two fundamental mechanisms: (1) Autonomous Exploration of Function-aware Trajectory. To comprehensively cover all application functionalities, we design a Function-aware Task Goal Generator that automatically constructs exploration goals by analyzing GUI structural information (e.g., screenshots and activity hierarchies). This enables systematic exploration to collect diverse trajectories. (2) Unsupervised Mining of Transition-aware Knowledge. To establish precise screen-operation logic, we develop a Transition-aware Knowledge Extractor that extracts effective screen-operation logic through unsupervised analysis the state transition of structured interaction triples (observation, action, outcome). This eliminates the need for human involvement in knowledge extraction. With a task success rate of 53.7% on SPA-Bench and 47.4% on AndroidWorld, GUI-explorer shows significant improvements over SOTA agents. It requires no parameter updates for new apps. GUI-explorer is open-sourced and publicly available at https://github.com/JiuTian-VL/GUI-explorer.
Curriculum Coarse-to-Fine Selection for High-IPC Dataset Distillation
Mar 24, 2025Dataset distillation (DD) excels in synthesizing a small number of images per class (IPC) but struggles to maintain its effectiveness in high-IPC settings. Recent works on dataset distillation demonstrate that combining distilled and real data can mitigate the effectiveness decay. However, our analysis of the combination paradigm reveals that the current one-shot and independent selection mechanism induces an incompatibility issue between distilled and real images. To address this issue, we introduce a novel curriculum coarse-to-fine selection (CCFS) method for efficient high-IPC dataset distillation. CCFS employs a curriculum selection framework for real data selection, where we leverage a coarse-to-fine strategy to select appropriate real data based on the current synthetic dataset in each curriculum. Extensive experiments validate CCFS, surpassing the state-of-the-art by +6.6\% on CIFAR-10, +5.8\% on CIFAR-100, and +3.4\% on Tiny-ImageNet under high-IPC settings. Notably, CCFS achieves 60.2\% test accuracy on ResNet-18 with a 20\% compression ratio of Tiny-ImageNet, closely matching full-dataset training with only 0.3\% degradation. Code: https://github.com/CYDaaa30/CCFS.
Optimus-2: Multimodal Minecraft Agent with Goal-Observation-Action Conditioned Policy
Feb 27, 2025



Building an agent that can mimic human behavior patterns to accomplish various open-world tasks is a long-term goal. To enable agents to effectively learn behavioral patterns across diverse tasks, a key challenge lies in modeling the intricate relationships among observations, actions, and language. To this end, we propose Optimus-2, a novel Minecraft agent that incorporates a Multimodal Large Language Model (MLLM) for high-level planning, alongside a Goal-Observation-Action Conditioned Policy (GOAP) for low-level control. GOAP contains (1) an Action-guided Behavior Encoder that models causal relationships between observations and actions at each timestep, then dynamically interacts with the historical observation-action sequence, consolidating it into fixed-length behavior tokens, and (2) an MLLM that aligns behavior tokens with open-ended language instructions to predict actions auto-regressively. Moreover, we introduce a high-quality Minecraft Goal-Observation-Action (MGOA)} dataset, which contains 25,000 videos across 8 atomic tasks, providing about 30M goal-observation-action pairs. The automated construction method, along with the MGOA dataset, can contribute to the community's efforts to train Minecraft agents. Extensive experimental results demonstrate that Optimus-2 exhibits superior performance across atomic tasks, long-horizon tasks, and open-ended instruction tasks in Minecraft.
FALCON: Resolving Visual Redundancy and Fragmentation in High-resolution Multimodal Large Language Models via Visual Registers
Jan 27, 2025



The incorporation of high-resolution visual input equips multimodal large language models (MLLMs) with enhanced visual perception capabilities for real-world tasks. However, most existing high-resolution MLLMs rely on a cropping-based approach to process images, which leads to fragmented visual encoding and a sharp increase in redundant tokens. To tackle these issues, we propose the FALCON model. FALCON introduces a novel visual register technique to simultaneously: 1) Eliminate redundant tokens at the stage of visual encoding. To directly address the visual redundancy present in the output of vision encoder, we propose a Register-based Representation Compacting (ReCompact) mechanism. This mechanism introduces a set of learnable visual registers designed to adaptively aggregate essential information while discarding redundancy. It enables the encoder to produce a more compact visual representation with a minimal number of output tokens, thus eliminating the need for an additional compression module. 2) Ensure continuity in visual encoding. To address the potential encoding errors caused by fragmented visual inputs, we develop a Register Interactive Attention (ReAtten) module. This module facilitates effective and efficient information exchange across sub-images by enabling interactions between visual registers. It ensures the continuity of visual semantics throughout the encoding. We conduct comprehensive experiments with FALCON on high-resolution benchmarks across a wide range of scenarios. FALCON demonstrates superior performance with a remarkable 9-fold and 16-fold reduction in visual tokens.