 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticVLA: Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation
Nov 13, 2025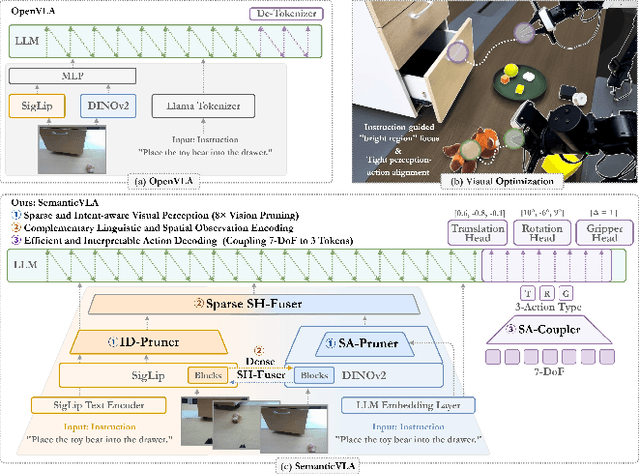
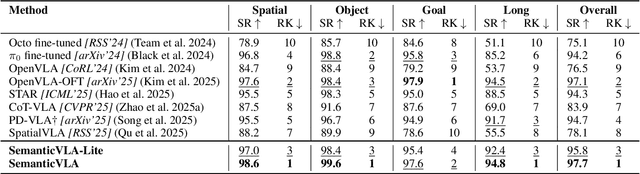
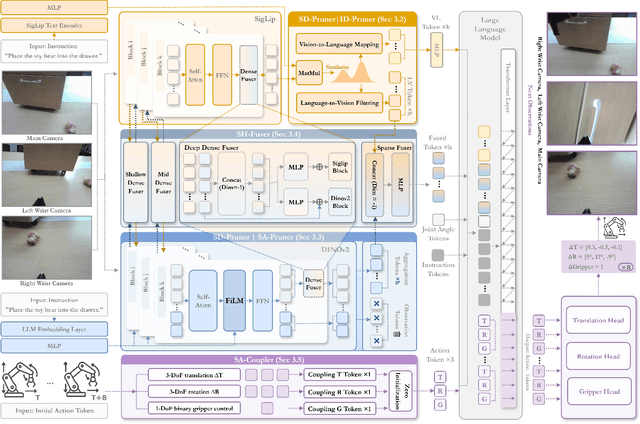

Vision-Language-Action (VLA) models have advanced in robotic manipulation, yet practical deployment remains hindered by two key limitations: 1) perceptual redundancy, where irrelevant visual inputs are processed inefficiently, and 2) superficial instruction-vision alignment, which hampers semantic grounding of actions. In this paper, we propose SemanticVLA, a novel VLA framework that performs Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation. Specifically: 1) To sparsify redundant perception while preserving semantic alignment, Semantic-guided Dual Visual Pruner (SD-Pruner) performs: Instruction-driven Pruner (ID-Pruner) extracts global action cues and local semantic anchors in SigLIP; Spatial-aggregation Pruner (SA-Pruner) compacts geometry-rich features into task-adaptive tokens in DINOv2. 2) To exploit sparsified features and integrate semantics with spatial geometry, Semantic-complementary Hierarchical Fuser (SH-Fuser) fuses dense patches and sparse tokens across SigLIP and DINOv2 for coherent representation. 3) To enhance the transformation from perception to action, Semantic-conditioned Action Coupler (SA-Coupler) replaces the conventional observation-to-DoF approach, yielding more efficient and interpretable behavior modeling for manipulation tasks. Extensive experiments on simulation and real-world tasks show that SemanticVLA sets a new SOTA in both performance and efficiency. SemanticVLA surpasses OpenVLA on LIBERO benchmark by 21.1% in success rate, while reducing training cost and inference latency by 3.0-fold and 2.7-fold.SemanticVLA is open-sourced and publicly available at https://github.com/JiuTian-VL/SemanticVLA
CogVLA: Cognition-Aligned Vision-Language-Action Model via Instruction-Driven Routing & Sparsification
Aug 28, 2025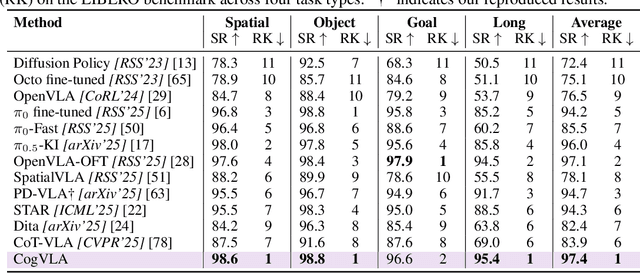
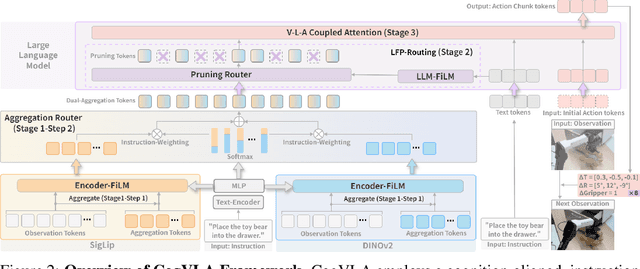
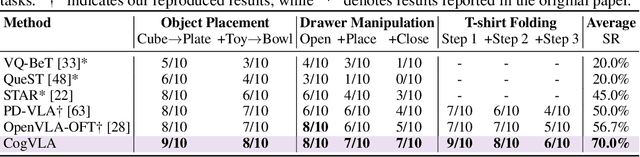
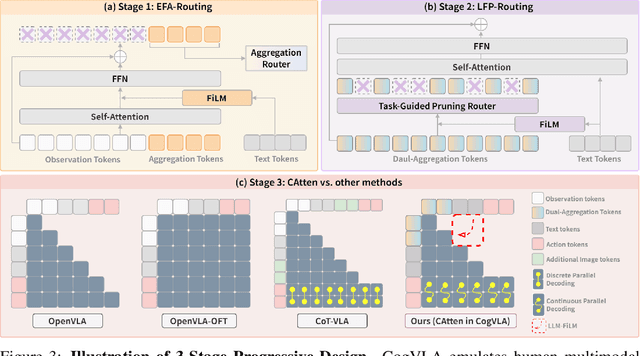
Recent Vision-Language-Action (VLA) models built on pre-trained Vision-Language Models (VLMs) require extensive post-training, resulting in high computational overhead that limits scalability and deployment.We propose CogVLA, a Cognition-Aligned Vision-Language-Action framework that leverages instruction-driven routing and sparsification to improve both efficiency and performance. CogVLA draws inspiration from human multimodal coordination and introduces a 3-stage progressive architecture. 1) Encoder-FiLM based Aggregation Routing (EFA-Routing) injects instruction information into the vision encoder to selectively aggregate and compress dual-stream visual tokens, forming a instruction-aware latent representation. 2) Building upon this compact visual encoding, LLM-FiLM based Pruning Routing (LFP-Routing) introduces action intent into the language model by pruning instruction-irrelevant visually grounded tokens, thereby achieving token-level sparsity. 3) To ensure that compressed perception inputs can still support accurate and coherent action generation, we introduce V-L-A Coupled Attention (CAtten), which combines causal vision-language attention with bidirectional action parallel decoding. Extensive experiments on the LIBERO benchmark and real-world robotic tasks demonstrate that CogVLA achieves state-of-the-art performance with success rates of 97.4% and 70.0%, respectively, while reducing training costs by 2.5-fold and decreasing inference latency by 2.8-fold compared to OpenVLA. CogVLA is open-sourced and publicly available at https://github.com/JiuTian-VL/CogVLA.
FALCON: Resolving Visual Redundancy and Fragmentation in High-resolution Multimodal Large Language Models via Visual Registers
Jan 27, 2025



The incorporation of high-resolution visual input equips multimodal large language models (MLLMs) with enhanced visual perception capabilities for real-world tasks. However, most existing high-resolution MLLMs rely on a cropping-based approach to process images, which leads to fragmented visual encoding and a sharp increase in redundant tokens. To tackle these issues, we propose the FALCON model. FALCON introduces a novel visual register technique to simultaneously: 1) Eliminate redundant tokens at the stage of visual encoding. To directly address the visual redundancy present in the output of vision encoder, we propose a Register-based Representation Compacting (ReCompact) mechanism. This mechanism introduces a set of learnable visual registers designed to adaptively aggregate essential information while discarding redundancy. It enables the encoder to produce a more compact visual representation with a minimal number of output tokens, thus eliminating the need for an additional compression module. 2) Ensure continuity in visual encoding. To address the potential encoding errors caused by fragmented visual inputs, we develop a Register Interactive Attention (ReAtten) module. This module facilitates effective and efficient information exchange across sub-images by enabling interactions between visual registers. It ensures the continuity of visual semantics throughout the encoding. We conduct comprehensive experiments with FALCON on high-resolution benchmarks across a wide range of scenarios. FALCON demonstrates superior performance with a remarkable 9-fold and 16-fold reduction in visual tokens.
Token-level Correlation-guided Compression for Efficient Multimodal Document Understanding
Jul 19, 2024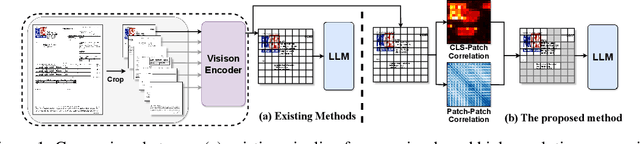
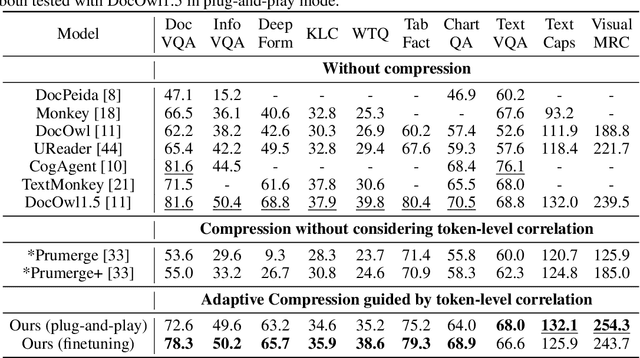

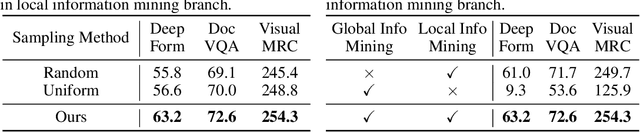
Cropping high-resolution document images into multiple sub-images is the most widely used approach for current Multimodal Large Language Models (MLLMs) to do document understanding. Most of current document understanding methods preserve all tokens within sub-images and treat them equally. This neglects their different informativeness and leads to a significant increase in the number of image tokens. To perform a more adaptive and efficient document understanding, we propose Token-level Correlation-guided Compression, a parameter-free and plug-and-play methodology to optimize token processing. Firstly, we propose an innovative approach for assessing the pattern repetitiveness based on the correlation between each patch tokens. This method identifies redundant tokens, allowing for the determination of the sub-image's information density. Secondly, we present a token-level sampling method that efficiently captures the most informative tokens by delving into the correlation between the [CLS] token and patch tokens. By integrating these strategies, we develop a plug-and-play adaptive compressor module that can be seamlessly incorporated into MLLMs utilizing cropping techniques. This module not only enhances the processing speed during training and inference but also maintains comparable performance. We conduct experiments with the SOTA document understanding model mPLUG-DocOwl1.5 and the effectiveness is demonstrated through extensive comparisons with other compression methods.
A Novel Dual Quaternion Based Dynamic Motion Primitives for Acrobatic Flight
Jul 13, 2021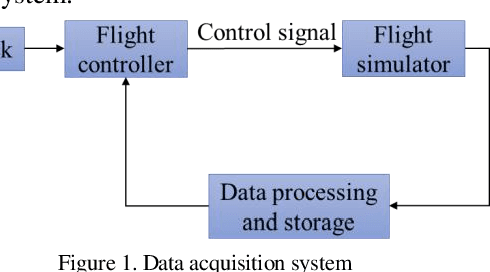
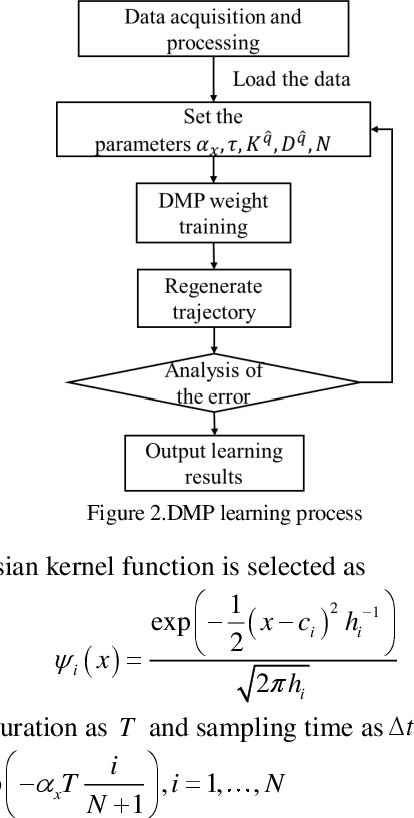
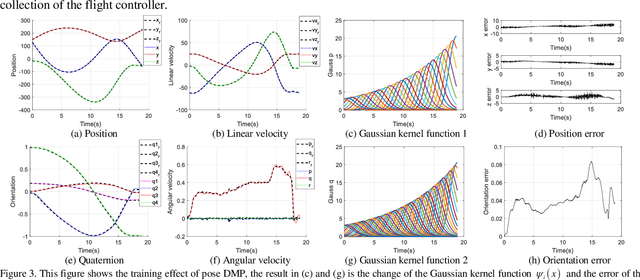
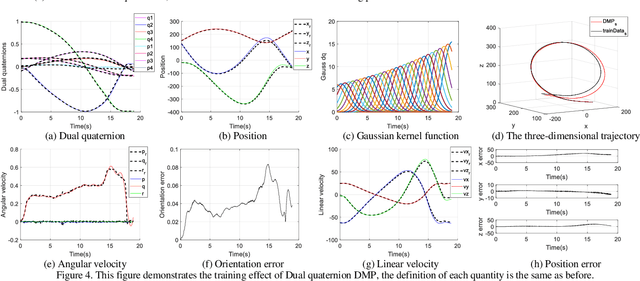
The realization of motion description is a challenging work for fixed-wing Unmanned Aerial Vehicle (UAV) acrobatic flight, due to the inherent coupling problem in ranslational-rotational motion. This paper aims to develop a novel maneuver description method through the idea of imitation learning, and there are two main contributions of our work: 1) A dual quaternion based dynamic motion primitives (DQ-DMP) is proposed and the state equations of the position and attitude can be combined without loss of accuracy. 2) An online hardware-inthe-loop (HITL) training system is established. Based on the DQDMP method, the geometric features of the demonstrated maneuver can be obtained in real-time, and the stability of the DQ-DMP is theoretically proved. The simulation results illustrate the superiority of the proposed method compared to the traditional position/attitude decoupling method.