 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEE-MCP: Self-Evolving MCP-GUI Agents via Automated Environment Generation and Experience Learning
Apr 10, 2026Computer-use agents that combine GUI interaction with structured API calls via the Model Context Protocol (MCP) show promise for automating software tasks. However, existing approaches lack a principled understanding of how agents should balance these two modalities and how to enable iterative self-improvement across diverse applications. We formulate MCP-GUI interplay as a unified hybrid policy learning problem where the agent learns when each modality provides complementary advantages, and show that distillation and experience augmentation target fundamentally different failure modes - requiring application-aware mechanism selection. Built on this formulation, we propose a self-evolving framework with a fully automatic pipeline that orchestrates automatic environment generation and validation, trajectory collection, gap-driven task synthesis, and quality-filtered training - all without manual intervention. A key innovation is our experience bank, which accumulates LLM-learned rules from trajectory comparison, enabling inference-time improvement without fine-tuning. Systematic \textbf{cross-application analysis} across three desktop applications reveals that the optimal strategy depends on MCP-GUI composition: distillation achieves 77.8\% pass rate on MCP-dominant tasks (+17.8pp), while the experience bank excels on GUI-intensive tasks (+10.0pp).
A Unified Perspective on Adversarial Membership Manipulation in Vision Models
Apr 03, 2026Membership inference attacks (MIAs) aim to determine whether a specific data point was part of a model's training set, serving as effective tools for evaluating privacy leakage of vision models. However, existing MIAs implicitly assume honest query inputs, and their adversarial robustness remains unexplored. We show that MIAs for vision models expose a previously overlooked adversarial surface: adversarial membership manipulation, where imperceptible perturbations can reliably push non-member images into the "member" region of state-of-the-art MIAs. In this paper, we provide the first unified perspective on this phenomenon by analyzing its mechanism and implications. We begin by demonstrating that adversarial membership fabrication is consistently effective across diverse architectures and datasets. We then reveal a distinctive geometric signature - a characteristic gradient-norm collapse trajectory - that reliably separates fabricated from true members despite their nearly identical semantic representations. Building on this insight, we introduce a principled detection strategy grounded in gradient-geometry signals and develop a robust inference framework that substantially mitigates adversarial manipulation. Extensive experiments show that fabrication is broadly effective, while our detection and robust inference strategies significantly enhance resilience. This work establishes the first comprehensive framework for adversarial membership manipulation in vision models.
HATS: Hardness-Aware Trajectory Synthesis for GUI Agents
Mar 12, 2026Graphical user interface (GUI) agents powered by large vision-language models (VLMs) have shown remarkable potential in automating digital tasks, highlighting the need for high-quality trajectory data to support effective agent training. Yet existing trajectory synthesis pipelines often yield agents that fail to generalize beyond simple interactions. We identify this limitation as stemming from the neglect of semantically ambiguous actions, whose meanings are context-dependent, sequentially dependent, or visually ambiguous. Such actions are crucial for real-world robustness but are under-represented and poorly processed in current datasets, leading to semantic misalignment between task instructions and execution. To address these issues, we propose HATS, a Hardness-Aware Trajectory Synthesis framework designed to mitigate the impact of semantic ambiguity. We define hardness as the degree of semantic ambiguity associated with an action and develop two complementary modules: (1) hardness-driven exploration, which guides data collection toward ambiguous yet informative interactions, and (2) alignment-guided refinement, which iteratively validates and repairs instruction-execution alignment. The two modules operate in a closed loop: exploration supplies refinement with challenging trajectories, while refinement feedback updates the hardness signal to guide future exploration. Extensive experiments show that agents trained with HATS consistently outperform state-of-the-art baselines across benchmark GUI environments.
SafePro: Evaluating the Safety of Professional-Level AI Agents
Jan 13, 2026Large language model-based agents are rapidly evolving from simple conversational assistants into autonomous systems capable of performing complex, professional-level tasks in various domains. While these advancements promise significant productivity gains, they also introduce critical safety risks that remain under-explored. Existing safety evaluations primarily focus on simple, daily assistance tasks, failing to capture the intricate decision-making processes and potential consequences of misaligned behaviors in professional settings. To address this gap, we introduce \textbf{SafePro}, a comprehensive benchmark designed to evaluate the safety alignment of AI agents performing professional activities. SafePro features a dataset of high-complexity tasks across diverse professional domains with safety risks, developed through a rigorous iterative creation and review process. Our evaluation of state-of-the-art AI models reveals significant safety vulnerabilities and uncovers new unsafe behaviors in professional contexts. We further show that these models exhibit both insufficient safety judgment and weak safety alignment when executing complex professional tasks. In addition, we investigate safety mitigation strategies for improving agent safety in these scenarios and observe encouraging improvements. Together, our findings highlight the urgent need for robust safety mechanisms tailored to the next generation of professional AI agents.
VPTracker: Global Vision-Language Tracking via Visual Prompt and MLLM
Dec 28, 2025Vision-Language Tracking aims to continuously localize objects described by a visual template and a language description. Existing methods, however, are typically limited to local search, making them prone to failures under viewpoint changes, occlusions, and rapid target movements. In this work, we introduce the first global tracking framework based on Multimodal Large Language Models (VPTracker), exploiting their powerful semantic reasoning to locate targets across the entire image space. While global search improves robustness and reduces drift, it also introduces distractions from visually or semantically similar objects. To address this, we propose a location-aware visual prompting mechanism that incorporates spatial priors into the MLLM. Specifically, we construct a region-level prompt based on the target's previous location, enabling the model to prioritize region-level recognition and resort to global inference only when necessary. This design retains the advantages of global tracking while effectively suppressing interference from distracting visual content. Extensive experiments show that our approach significantly enhances tracking stability and target disambiguation under challenging scenarios, opening a new avenue for integrating MLLMs into visual tracking. Code is available at https://github.com/jcwang0602/VPTracker.
SemanticVLA: Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation
Nov 13, 2025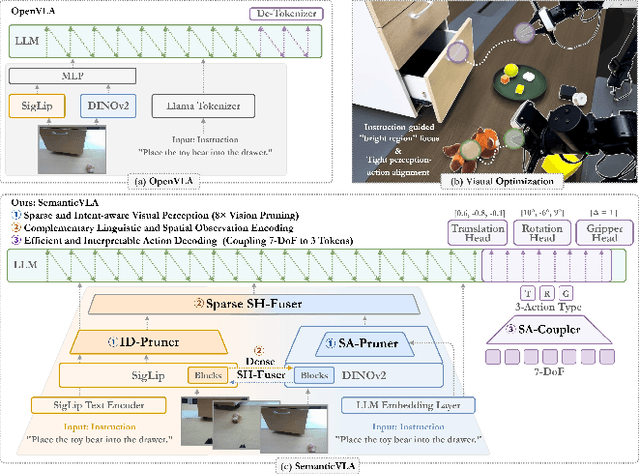
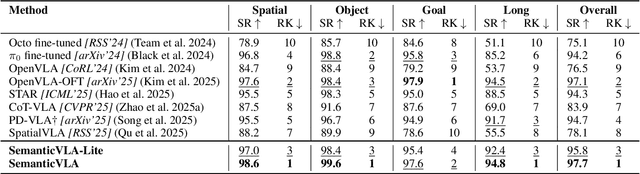
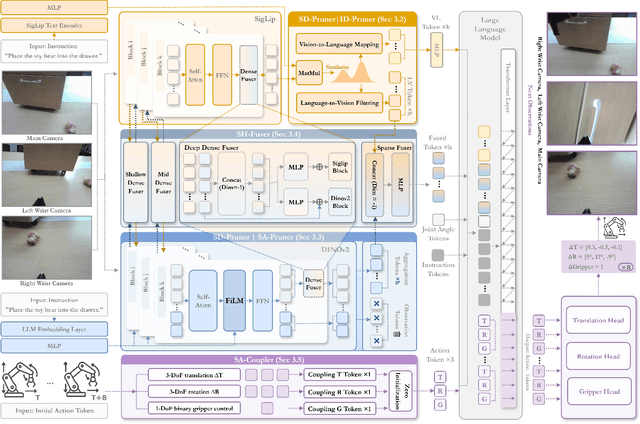

Vision-Language-Action (VLA) models have advanced in robotic manipulation, yet practical deployment remains hindered by two key limitations: 1) perceptual redundancy, where irrelevant visual inputs are processed inefficiently, and 2) superficial instruction-vision alignment, which hampers semantic grounding of actions. In this paper, we propose SemanticVLA, a novel VLA framework that performs Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation. Specifically: 1) To sparsify redundant perception while preserving semantic alignment, Semantic-guided Dual Visual Pruner (SD-Pruner) performs: Instruction-driven Pruner (ID-Pruner) extracts global action cues and local semantic anchors in SigLIP; Spatial-aggregation Pruner (SA-Pruner) compacts geometry-rich features into task-adaptive tokens in DINOv2. 2) To exploit sparsified features and integrate semantics with spatial geometry, Semantic-complementary Hierarchical Fuser (SH-Fuser) fuses dense patches and sparse tokens across SigLIP and DINOv2 for coherent representation. 3) To enhance the transformation from perception to action, Semantic-conditioned Action Coupler (SA-Coupler) replaces the conventional observation-to-DoF approach, yielding more efficient and interpretable behavior modeling for manipulation tasks. Extensive experiments on simulation and real-world tasks show that SemanticVLA sets a new SOTA in both performance and efficiency. SemanticVLA surpasses OpenVLA on LIBERO benchmark by 21.1% in success rate, while reducing training cost and inference latency by 3.0-fold and 2.7-fold.SemanticVLA is open-sourced and publicly available at https://github.com/JiuTian-VL/SemanticVLA
SIRAJ: Diverse and Efficient Red-Teaming for LLM Agents via Distilled Structured Reasoning
Oct 30, 2025The ability of LLM agents to plan and invoke tools exposes them to new safety risks, making a comprehensive red-teaming system crucial for discovering vulnerabilities and ensuring their safe deployment. We present SIRAJ: a generic red-teaming framework for arbitrary black-box LLM agents. We employ a dynamic two-step process that starts with an agent definition and generates diverse seed test cases that cover various risk outcomes, tool-use trajectories, and risk sources. Then, it iteratively constructs and refines model-based adversarial attacks based on the execution trajectories of former attempts. To optimize the red-teaming cost, we present a model distillation approach that leverages structured forms of a teacher model's reasoning to train smaller models that are equally effective. Across diverse evaluation agent settings, our seed test case generation approach yields 2 -- 2.5x boost to the coverage of risk outcomes and tool-calling trajectories. Our distilled 8B red-teamer model improves attack success rate by 100%, surpassing the 671B Deepseek-R1 model. Our ablations and analyses validate the effectiveness of the iterative framework, structured reasoning, and the generalization of our red-teamer models.
MESH -- Understanding Videos Like Human: Measuring Hallucinations in Large Video Models
Sep 10, 2025Large Video Models (LVMs) build on the semantic capabilities of Large Language Models (LLMs) and vision modules by integrating temporal information to better understand dynamic video content. Despite their progress, LVMs are prone to hallucinations-producing inaccurate or irrelevant descriptions. Current benchmarks for video hallucination depend heavily on manual categorization of video content, neglecting the perception-based processes through which humans naturally interpret videos. We introduce MESH, a benchmark designed to evaluate hallucinations in LVMs systematically. MESH uses a Question-Answering framework with binary and multi-choice formats incorporating target and trap instances. It follows a bottom-up approach, evaluating basic objects, coarse-to-fine subject features, and subject-action pairs, aligning with human video understanding. We demonstrate that MESH offers an effective and comprehensive approach for identifying hallucinations in videos. Our evaluations show that while LVMs excel at recognizing basic objects and features, their susceptibility to hallucinations increases markedly when handling fine details or aligning multiple actions involving various subjects in longer videos.
Uncertainty-Aware GUI Agent: Adaptive Perception through Component Recommendation and Human-in-the-Loop Refinement
Aug 06, 2025Graphical user interface (GUI) agents have shown promise in automating mobile tasks but still struggle with input redundancy and decision ambiguity. In this paper, we present \textbf{RecAgent}, an uncertainty-aware agent that addresses these issues through adaptive perception. We distinguish two types of uncertainty in GUI navigation: (1) perceptual uncertainty, caused by input redundancy and noise from comprehensive screen information, and (2) decision uncertainty, arising from ambiguous tasks and complex reasoning. To reduce perceptual uncertainty, RecAgent employs a component recommendation mechanism that identifies and focuses on the most relevant UI elements. For decision uncertainty, it uses an interactive module to request user feedback in ambiguous situations, enabling intent-aware decisions. These components are integrated into a unified framework that proactively reduces input complexity and reacts to high-uncertainty cases via human-in-the-loop refinement. Additionally, we propose a dataset called \textbf{ComplexAction} to evaluate the success rate of GUI agents in executing specified single-step actions within complex scenarios. Extensive experiments validate the effectiveness of our approach. The dataset and code will be available at https://github.com/Fanye12/RecAgent.
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jul 17, 2025Video generation models have achieved remarkable progress in creating high-quality, photorealistic content. However, their ability to accurately simulate physical phenomena remains a critical and unresolved challenge. This paper presents PhyWorldBench, a comprehensive benchmark designed to evaluate video generation models based on their adherence to the laws of physics. The benchmark covers multiple levels of physical phenomena, ranging from fundamental principles like object motion and energy conservation to more complex scenarios involving rigid body interactions and human or animal motion. Additionally, we introduce a novel ""Anti-Physics"" category, where prompts intentionally violate real-world physics, enabling the assessment of whether models can follow such instructions while maintaining logical consistency. Besides large-scale human evaluation, we also design a simple yet effective method that could utilize current MLLM to evaluate the physics realism in a zero-shot fashion. We evaluate 12 state-of-the-art text-to-video generation models, including five open-source and five proprietary models, with a detailed comparison and analysis. we identify pivotal challenges models face in adhering to real-world physics. Through systematic testing of their outputs across 1,050 curated prompts-spanning fundamental, composite, and anti-physics scenarios-we identify pivotal challenges these models face in adhering to real-world physics. We then rigorously examine their performance on diverse physical phenomena with varying prompt types, deriving targeted recommendations for crafting prompts that enhance fidelity to physical principles.