 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCite-While-You-Generate: Training-Free Evidence Attribution for Multimodal Clinical Summarization
Jan 23, 2026Trustworthy clinical summarization requires not only fluent generation but also transparency about where each statement comes from. We propose a training-free framework for generation-time source attribution that leverages decoder attentions to directly cite supporting text spans or images, overcoming the limitations of post-hoc or retraining-based methods. We introduce two strategies for multimodal attribution: a raw image mode, which directly uses image patch attentions, and a caption-as-span mode, which substitutes images with generated captions to enable purely text-based alignment. Evaluations on two representative domains: clinician-patient dialogues (CliConSummation) and radiology reports (MIMIC-CXR), show that our approach consistently outperforms embedding-based and self-attribution baselines, improving both text-level and multimodal attribution accuracy (e.g., +15% F1 over embedding baselines). Caption-based attribution achieves competitive performance with raw-image attention while being more lightweight and practical. These findings highlight attention-guided attribution as a promising step toward interpretable and deployable clinical summarization systems.
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jul 17, 2025Video generation models have achieved remarkable progress in creating high-quality, photorealistic content. However, their ability to accurately simulate physical phenomena remains a critical and unresolved challenge. This paper presents PhyWorldBench, a comprehensive benchmark designed to evaluate video generation models based on their adherence to the laws of physics. The benchmark covers multiple levels of physical phenomena, ranging from fundamental principles like object motion and energy conservation to more complex scenarios involving rigid body interactions and human or animal motion. Additionally, we introduce a novel ""Anti-Physics"" category, where prompts intentionally violate real-world physics, enabling the assessment of whether models can follow such instructions while maintaining logical consistency. Besides large-scale human evaluation, we also design a simple yet effective method that could utilize current MLLM to evaluate the physics realism in a zero-shot fashion. We evaluate 12 state-of-the-art text-to-video generation models, including five open-source and five proprietary models, with a detailed comparison and analysis. we identify pivotal challenges models face in adhering to real-world physics. Through systematic testing of their outputs across 1,050 curated prompts-spanning fundamental, composite, and anti-physics scenarios-we identify pivotal challenges these models face in adhering to real-world physics. We then rigorously examine their performance on diverse physical phenomena with varying prompt types, deriving targeted recommendations for crafting prompts that enhance fidelity to physical principles.
Multimodal Inconsistency Reasoning (MMIR): A New Benchmark for Multimodal Reasoning Models
Feb 22, 2025Existing Multimodal Large Language Models (MLLMs) are predominantly trained and tested on consistent visual-textual inputs, leaving open the question of whether they can handle inconsistencies in real-world, layout-rich content. To bridge this gap, we propose the Multimodal Inconsistency Reasoning (MMIR) benchmark to assess MLLMs' ability to detect and reason about semantic mismatches in artifacts such as webpages, presentation slides, and posters. MMIR comprises 534 challenging samples, each containing synthetically injected errors across five reasoning-heavy categories: Factual Contradiction, Identity Misattribution, Contextual Mismatch, Quantitative Discrepancy, and Temporal/Spatial Incoherence. We evaluate six state-of-the-art MLLMs, showing that models with dedicated multimodal reasoning capabilities, such as o1, substantially outperform their counterparts while open-source models remain particularly vulnerable to inconsistency errors. Detailed error analyses further show that models excel in detecting inconsistencies confined to a single modality, particularly in text, but struggle with cross-modal conflicts and complex layouts. Probing experiments reveal that single-modality prompting, including Chain-of-Thought (CoT) and Set-of-Mark (SoM) methods, yields marginal gains, revealing a key bottleneck in cross-modal reasoning. Our findings highlight the need for advanced multimodal reasoning and point to future research on multimodal inconsistency.
Worse than Random? An Embarrassingly Simple Probing Evaluation of Large Multimodal Models in Medical VQA
May 30, 2024



Large Multimodal Models (LMMs) have shown remarkable progress in the field of medical Visual Question Answering (Med-VQA), achieving high accuracy on existing benchmarks. However, their reliability under robust evaluation is questionable. This study reveals that state-of-the-art models, when subjected to simple probing evaluation, perform worse than random guessing on medical diagnosis questions. To address this critical evaluation problem, we introduce the Probing Evaluation for Medical Diagnosis (ProbMed) dataset to rigorously assess LMM performance in medical imaging through probing evaluation and procedural diagnosis. Particularly, probing evaluation features pairing original questions with negation questions with hallucinated attributes, while procedural diagnosis requires reasoning across various diagnostic dimensions for each image, including modality recognition, organ identification, clinical findings, abnormalities, and positional grounding. Our evaluation reveals that top-performing models like GPT-4V and Gemini Pro perform worse than random guessing on specialized diagnostic questions, indicating significant limitations in handling fine-grained medical inquiries. Besides, models like LLaVA-Med struggle even with more general questions, and results from CheXagent demonstrate the transferability of expertise across different modalities of the same organ, showing that specialized domain knowledge is still crucial for improving performance. This study underscores the urgent need for more robust evaluation to ensure the reliability of LMMs in critical fields like medical diagnosis, and current LMMs are still far from applicable to those fields.
Muffin or Chihuahua? Challenging Large Vision-Language Models with Multipanel VQA
Jan 29, 2024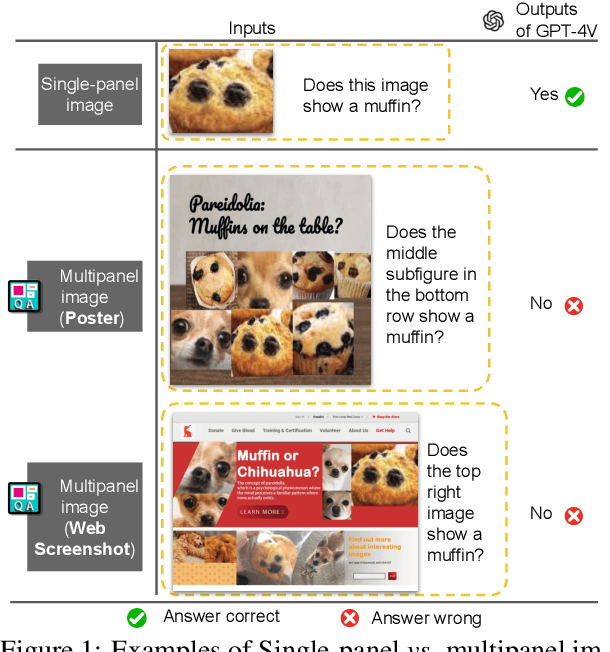
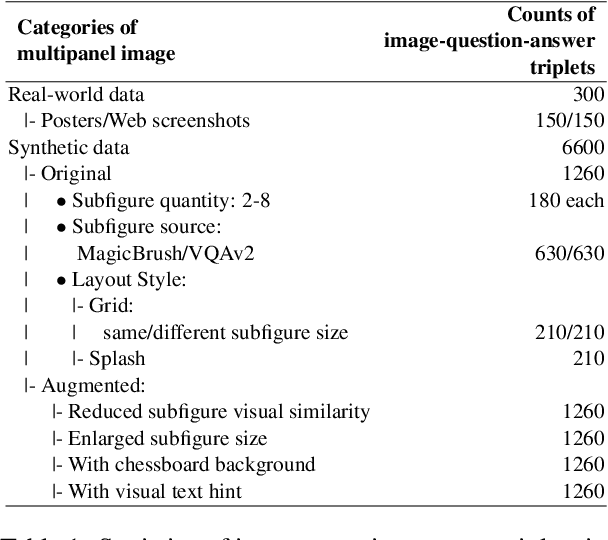


Multipanel images, commonly seen as web screenshots, posters, etc., pervade our daily lives. These images, characterized by their composition of multiple subfigures in distinct layouts, effectively convey information to people. Toward building advanced multimodal AI applications, such as agents that understand complex scenes and navigate through webpages, the skill of multipanel visual reasoning is essential, and a comprehensive evaluation of models in this regard is important. Therefore, our paper introduces Multipanel Visual Question Answering (MultipanelVQA), a novel benchmark that specifically challenges models in comprehending multipanel images. The benchmark comprises 6,600 questions and answers related to multipanel images. While these questions are straightforward for average humans, achieving nearly perfect correctness, they pose significant challenges to the state-of-the-art Large Vision Language Models (LVLMs) we tested. In our study, we utilized synthetically curated multipanel images specifically designed to isolate and evaluate the impact of diverse factors on model performance, revealing the sensitivity of LVLMs to various interferences in multipanel images, such as adjacent subfigures and layout complexity. As a result, MultipanelVQA highlights the need and direction for improving LVLMs' ability to understand complex visual-language contexts. Code and data are released at https://sites.google.com/view/multipanelvqa/home.