 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolving 3D Scene Generation from a Single Image
Dec 09, 2025Generating high-quality, textured 3D scenes from a single image remains a fundamental challenge in vision and graphics. Recent image-to-3D generators recover reasonable geometry from single views, but their object-centric training limits generalization to complex, large-scale scenes with faithful structure and texture. We present EvoScene, a self-evolving, training-free framework that progressively reconstructs complete 3D scenes from single images. The key idea is combining the complementary strengths of existing models: geometric reasoning from 3D generation models and visual knowledge from video generation models. Through three iterative stages--Spatial Prior Initialization, Visual-guided 3D Scene Mesh Generation, and Spatial-guided Novel View Generation--EvoScene alternates between 2D and 3D domains, gradually improving both structure and appearance. Experiments on diverse scenes demonstrate that EvoScene achieves superior geometric stability, view-consistent textures, and unseen-region completion compared to strong baselines, producing ready-to-use 3D meshes for practical applications.
WALT: Web Agents that Learn Tools
Oct 01, 2025Web agents promise to automate complex browser tasks, but current methods remain brittle -- relying on step-by-step UI interactions and heavy LLM reasoning that break under dynamic layouts and long horizons. Humans, by contrast, exploit website-provided functionality through high-level operations like search, filter, and sort. We introduce WALT (Web Agents that Learn Tools), a framework that reverse-engineers latent website functionality into reusable invocable tools. Rather than hypothesizing ad-hoc skills, WALT exposes robust implementations of automations already designed into websites -- spanning discovery (search, filter, sort), communication (post, comment, upvote), and content management (create, edit, delete). Tools abstract away low-level execution: instead of reasoning about how to click and type, agents simply call search(query) or create(listing). This shifts the computational burden from fragile step-by-step reasoning to reliable tool invocation. On VisualWebArena and WebArena, WALT achieves higher success with fewer steps and less LLM-dependent reasoning, establishing a robust and generalizable paradigm for browser automation.
SCUBA: Salesforce Computer Use Benchmark
Sep 30, 2025

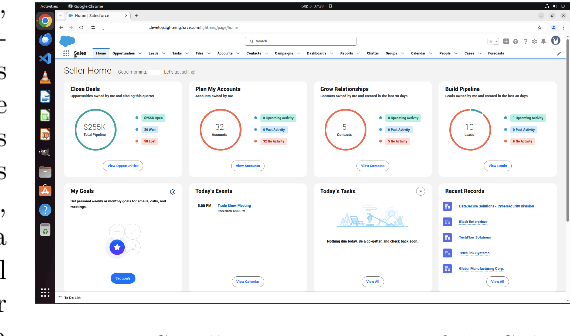

We introduce SCUBA, a benchmark designed to evaluate computer-use agents on customer relationship management (CRM) workflows within the Salesforce platform. SCUBA contains 300 task instances derived from real user interviews, spanning three primary personas, platform administrators, sales representatives, and service agents. The tasks test a range of enterprise-critical abilities, including Enterprise Software UI navigation, data manipulation, workflow automation, information retrieval, and troubleshooting. To ensure realism, SCUBA operates in Salesforce sandbox environments with support for parallel execution and fine-grained evaluation metrics to capture milestone progress. We benchmark a diverse set of agents under both zero-shot and demonstration-augmented settings. We observed huge performance gaps in different agent design paradigms and gaps between the open-source model and the closed-source model. In the zero-shot setting, open-source model powered computer-use agents that have strong performance on related benchmarks like OSWorld only have less than 5\% success rate on SCUBA, while methods built on closed-source models can still have up to 39% task success rate. In the demonstration-augmented settings, task success rates can be improved to 50\% while simultaneously reducing time and costs by 13% and 16%, respectively. These findings highlight both the challenges of enterprise tasks automation and the promise of agentic solutions. By offering a realistic benchmark with interpretable evaluation, SCUBA aims to accelerate progress in building reliable computer-use agents for complex business software ecosystems.
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jul 17, 2025Video generation models have achieved remarkable progress in creating high-quality, photorealistic content. However, their ability to accurately simulate physical phenomena remains a critical and unresolved challenge. This paper presents PhyWorldBench, a comprehensive benchmark designed to evaluate video generation models based on their adherence to the laws of physics. The benchmark covers multiple levels of physical phenomena, ranging from fundamental principles like object motion and energy conservation to more complex scenarios involving rigid body interactions and human or animal motion. Additionally, we introduce a novel ""Anti-Physics"" category, where prompts intentionally violate real-world physics, enabling the assessment of whether models can follow such instructions while maintaining logical consistency. Besides large-scale human evaluation, we also design a simple yet effective method that could utilize current MLLM to evaluate the physics realism in a zero-shot fashion. We evaluate 12 state-of-the-art text-to-video generation models, including five open-source and five proprietary models, with a detailed comparison and analysis. we identify pivotal challenges models face in adhering to real-world physics. Through systematic testing of their outputs across 1,050 curated prompts-spanning fundamental, composite, and anti-physics scenarios-we identify pivotal challenges these models face in adhering to real-world physics. We then rigorously examine their performance on diverse physical phenomena with varying prompt types, deriving targeted recommendations for crafting prompts that enhance fidelity to physical principles.
Struct2D: A Perception-Guided Framework for Spatial Reasoning in Large Multimodal Models
Jun 04, 2025Unlocking spatial reasoning in Large Multimodal Models (LMMs) is crucial for enabling intelligent interaction with 3D environments. While prior efforts often rely on explicit 3D inputs or specialized model architectures, we ask: can LMMs reason about 3D space using only structured 2D representations derived from perception? We introduce Struct2D, a perception-guided prompting framework that combines bird's-eye-view (BEV) images with object marks and object-centric metadata, optionally incorporating egocentric keyframes when needed. Using Struct2D, we conduct an in-depth zero-shot analysis of closed-source LMMs (e.g., GPT-o3) and find that they exhibit surprisingly strong spatial reasoning abilities when provided with structured 2D inputs, effectively handling tasks such as relative direction estimation and route planning. Building on these insights, we construct Struct2D-Set, a large-scale instruction tuning dataset with 200K fine-grained QA pairs across eight spatial reasoning categories, generated automatically from 3D indoor scenes. We fine-tune an open-source LMM (Qwen2.5VL) on Struct2D-Set, achieving competitive performance on multiple benchmarks, including 3D question answering, dense captioning, and object grounding. Our approach demonstrates that structured 2D inputs can effectively bridge perception and language reasoning in LMMs-without requiring explicit 3D representations as input. We will release both our code and dataset to support future research.
Constructing a 3D Town from a Single Image
May 21, 2025Acquiring detailed 3D scenes typically demands costly equipment, multi-view data, or labor-intensive modeling. Therefore, a lightweight alternative, generating complex 3D scenes from a single top-down image, plays an essential role in real-world applications. While recent 3D generative models have achieved remarkable results at the object level, their extension to full-scene generation often leads to inconsistent geometry, layout hallucinations, and low-quality meshes. In this work, we introduce 3DTown, a training-free framework designed to synthesize realistic and coherent 3D scenes from a single top-down view. Our method is grounded in two principles: region-based generation to improve image-to-3D alignment and resolution, and spatial-aware 3D inpainting to ensure global scene coherence and high-quality geometry generation. Specifically, we decompose the input image into overlapping regions and generate each using a pretrained 3D object generator, followed by a masked rectified flow inpainting process that fills in missing geometry while maintaining structural continuity. This modular design allows us to overcome resolution bottlenecks and preserve spatial structure without requiring 3D supervision or fine-tuning. Extensive experiments across diverse scenes show that 3DTown outperforms state-of-the-art baselines, including Trellis, Hunyuan3D-2, and TripoSG, in terms of geometry quality, spatial coherence, and texture fidelity. Our results demonstrate that high-quality 3D town generation is achievable from a single image using a principled, training-free approach.
Reconfigurable legged metamachines that run on autonomous modular legs
May 01, 2025
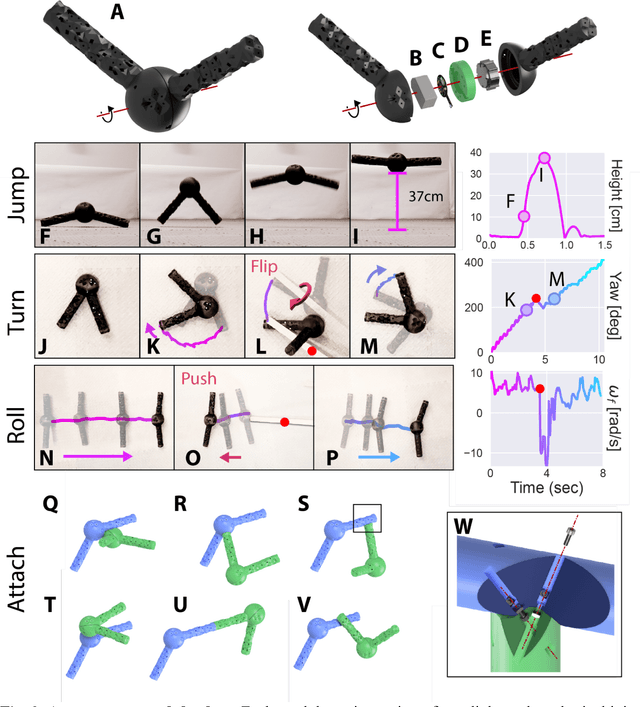
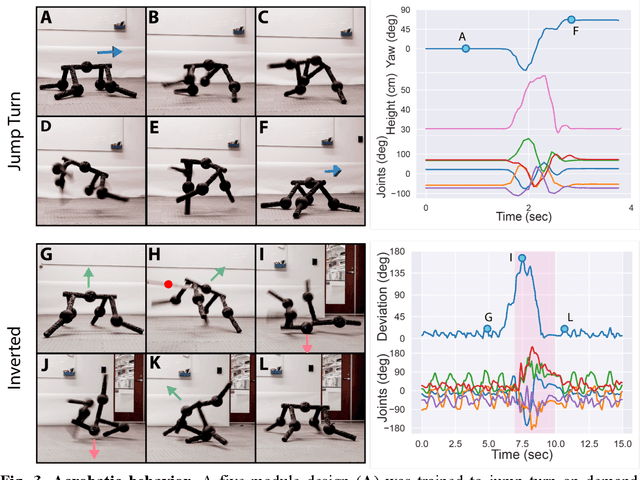
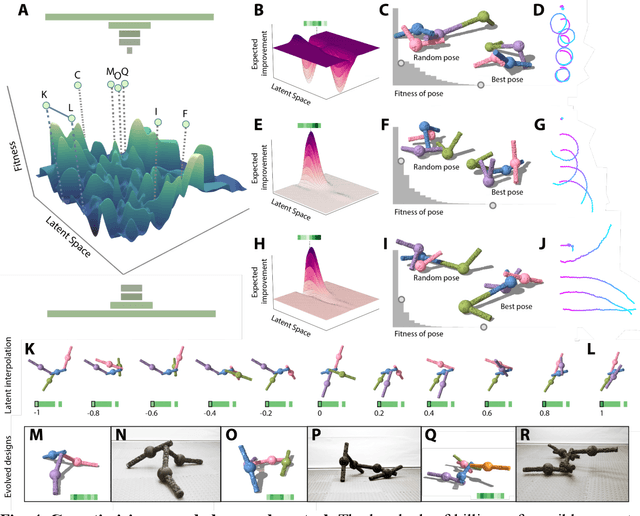
Legged machines are becoming increasingly agile and adaptive but they have so far lacked the basic reconfigurability of legged animals, which have been rearranged and reshaped to fill millions of niches. Unlike their biological counterparts, legged machines have largely converged over the past decade to canonical quadrupedal and bipedal architectures that cannot be easily reconfigured to meet new tasks or recover from injury. Here we introduce autonomous modular legs: agile yet minimal, single-degree-of-freedom jointed links that can learn complex dynamic behaviors and may be freely attached to form legged metamachines at the meter scale. This enables rapid repair, redesign, and recombination of highly-dynamic modular agents that move quickly and acrobatically (non-quasistatically) through unstructured environments. Because each module is itself a complete agent, legged metamachines are able to sustain deep structural damage that would completely disable other legged robots. We also show how to encode the vast space of possible body configurations into a compact latent design genome that can be efficiently explored, revealing a wide diversity of novel legged forms.
Klein Model for Hyperbolic Neural Networks
Oct 22, 2024Hyperbolic neural networks (HNNs) have been proved effective in modeling complex data structures. However, previous works mainly focused on the Poincar\'e ball model and the hyperboloid model as coordinate representations of the hyperbolic space, often neglecting the Klein model. Despite this, the Klein model offers its distinct advantages thanks to its straight-line geodesics, which facilitates the well-known Einstein midpoint construction, previously leveraged to accompany HNNs in other models. In this work, we introduce a framework for hyperbolic neural networks based on the Klein model. We provide detailed formulation for representing useful operations using the Klein model. We further study the Klein linear layer and prove that the "tangent space construction" of the scalar multiplication and parallel transport are exactly the Einstein scalar multiplication and the Einstein addition, analogous to the M\"obius operations used in the Poincar\'e ball model. We show numerically that the Klein HNN performs on par with the Poincar\'e ball model, providing a third option for HNN that works as a building block for more complicated architectures.
TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
Oct 15, 2024



Understanding fine-grained temporal dynamics is crucial for multimodal video comprehension and generation. Due to the lack of fine-grained temporal annotations, existing video benchmarks mostly resemble static image benchmarks and are incompetent at evaluating models for temporal understanding. In this paper, we introduce TemporalBench, a new benchmark dedicated to evaluating fine-grained temporal understanding in videos. TemporalBench consists of ~10K video question-answer pairs, derived from ~2K high-quality human annotations detailing the temporal dynamics in video clips. As a result, our benchmark provides a unique testbed for evaluating various temporal understanding and reasoning abilities such as action frequency, motion magnitude, event order, etc. Moreover, it enables evaluations on various tasks like both video question answering and captioning, both short and long video understanding, as well as different models such as multimodal video embedding models and text generation models. Results show that state-of-the-art models like GPT-4o achieve only 38.5% question answering accuracy on TemporalBench, demonstrating a significant gap (~30%) between humans and AI in temporal understanding. Furthermore, we notice a critical pitfall for multi-choice QA where LLMs can detect the subtle changes in negative captions and find a centralized description as a cue for its prediction, where we propose Multiple Binary Accuracy (MBA) to correct such bias. We hope that TemporalBench can foster research on improving models' temporal reasoning capabilities. Both dataset and evaluation code will be made available.
EditRoom: LLM-parameterized Graph Diffusion for Composable 3D Room Layout Editing
Oct 03, 2024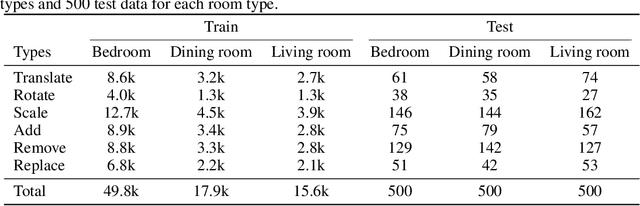
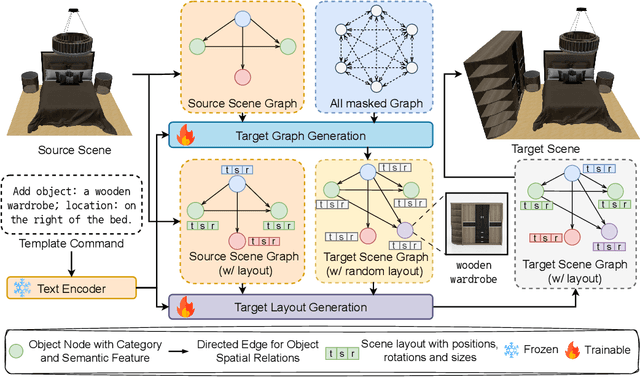

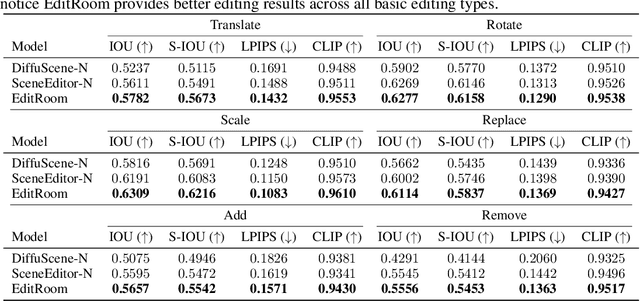
Given the steep learning curve of professional 3D software and the time-consuming process of managing large 3D assets, language-guided 3D scene editing has significant potential in fields such as virtual reality, augmented reality, and gaming. However, recent approaches to language-guided 3D scene editing either require manual interventions or focus only on appearance modifications without supporting comprehensive scene layout changes. In response, we propose Edit-Room, a unified framework capable of executing a variety of layout edits through natural language commands, without requiring manual intervention. Specifically, EditRoom leverages Large Language Models (LLMs) for command planning and generates target scenes using a diffusion-based method, enabling six types of edits: rotate, translate, scale, replace, add, and remove. To address the lack of data for language-guided 3D scene editing, we have developed an automatic pipeline to augment existing 3D scene synthesis datasets and introduced EditRoom-DB, a large-scale dataset with 83k editing pairs, for training and evaluation. Our experiments demonstrate that our approach consistently outperforms other baselines across all metrics, indicating higher accuracy and coherence in language-guided scene layout editing.