 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleFormer: Span Representation Cumulation for Long-Context Transformer
Nov 13, 2025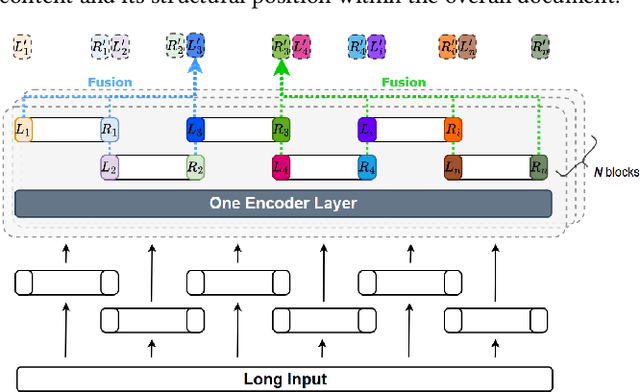


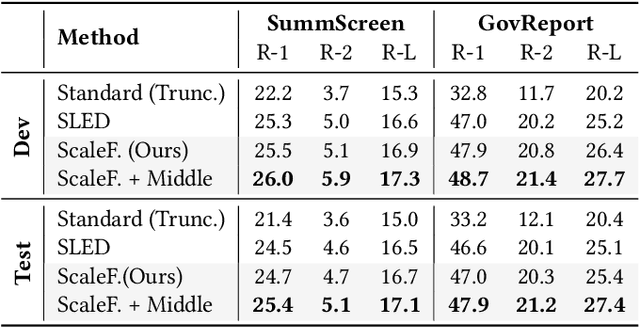
The quadratic complexity of standard self-attention severely limits the application of Transformer-based models to long-context tasks. While efficient Transformer variants exist, they often require architectural changes and costly pre-training from scratch. To circumvent this, we propose ScaleFormer(Span Representation Cumulation for Long-Context Transformer) - a simple and effective plug-and-play framework that adapts off-the-shelf pre-trained encoder-decoder models to process long sequences without requiring architectural modifications. Our approach segments long inputs into overlapping chunks and generates a compressed, context-aware representation for the decoder. The core of our method is a novel, parameter-free fusion mechanism that endows each chunk's representation with structural awareness of its position within the document. It achieves this by enriching each chunk's boundary representations with cumulative context vectors from all preceding and succeeding chunks. This strategy provides the model with a strong signal of the document's narrative flow, achieves linear complexity, and enables pre-trained models to reason effectively over long-form text. Experiments on long-document summarization show that our method is highly competitive with and often outperforms state-of-the-art approaches without requiring architectural modifications or external retrieval mechanisms.
ProjectTest: A Project-level LLM Unit Test Generation Benchmark and Impact of Error Fixing Mechanisms
Feb 11, 2025



Unit test generation has become a promising and important use case of LLMs. However, existing evaluation benchmarks for assessing LLM unit test generation capabilities focus on function- or class-level code rather than more practical and challenging project-level codebases. To address such limitation, we propose ProjectTest, a project-level benchmark for unit test generation covering Python, Java, and JavaScript. ProjectTest features 20 moderate-sized and high-quality projects per language. We evaluate nine frontier LLMs on ProjectTest and the results show that all frontier LLMs tested exhibit moderate performance on ProjectTest on Python and Java, highlighting the difficulty of ProjectTest. We also conduct a thorough error analysis, which shows that even frontier LLMs, such as Claude-3.5-Sonnet, have significant simple errors, including compilation and cascade errors. Motivated by this observation, we further evaluate all frontier LLMs under manual error-fixing and self-error-fixing scenarios to assess their potential when equipped with error-fixing mechanisms.
ProjectTest: A Project-level Unit Test Generation Benchmark and Impact of Error Fixing Mechanisms
Feb 10, 2025Unit test generation has become a promising and important use case of LLMs. However, existing evaluation benchmarks for assessing LLM unit test generation capabilities focus on function- or class-level code rather than more practical and challenging project-level codebases. To address such limitation, we propose ProjectTest, a project-level benchmark for unit test generation covering Python, Java, and JavaScript. ProjectTest features 20 moderate-sized and high-quality projects per language. We evaluate nine frontier LLMs on ProjectTest and the results show that all frontier LLMs tested exhibit moderate performance on ProjectTest on Python and Java, highlighting the difficulty of ProjectTest. We also conduct a thorough error analysis, which shows that even frontier LLMs, such as Claude-3.5-Sonnet, have significant simple errors, including compilation and cascade errors. Motivated by this observation, we further evaluate all frontier LLMs under manual error-fixing and self-error-fixing scenarios to assess their potential when equipped with error-fixing mechanisms.
AAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024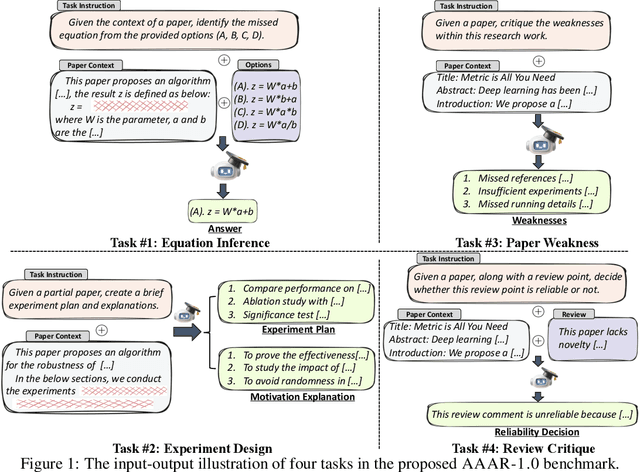
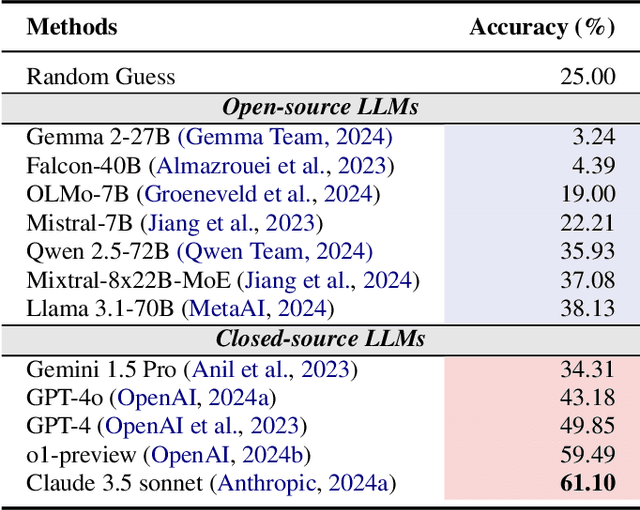
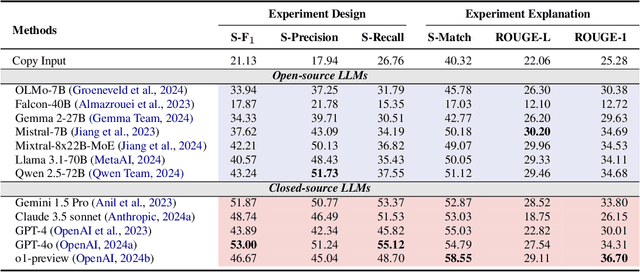
Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024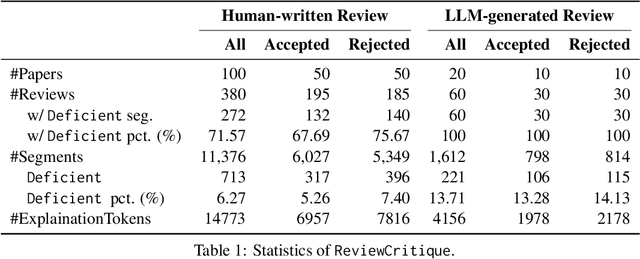
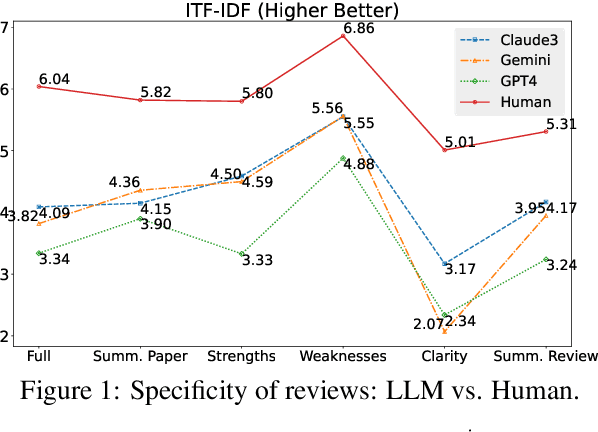

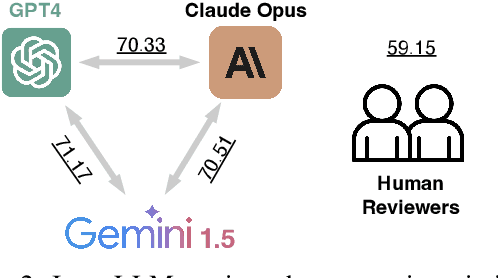
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
LLMs' Classification Performance is Overclaimed
Jun 23, 2024In many classification tasks designed for AI or human to solve, gold labels are typically included within the label space by default, often posed as "which of the following is correct?" This standard setup has traditionally highlighted the strong performance of advanced AI, particularly top-performing Large Language Models (LLMs), in routine classification tasks. However, when the gold label is intentionally excluded from the label space, it becomes evident that LLMs still attempt to select from the available label candidates, even when none are correct. This raises a pivotal question: Do LLMs truly demonstrate their intelligence in understanding the essence of classification tasks? In this study, we evaluate both closed-source and open-source LLMs across representative classification tasks, arguing that the perceived performance of LLMs is overstated due to their inability to exhibit the expected comprehension of the task. This paper makes a threefold contribution: i) To our knowledge, this is the first work to identify the limitations of LLMs in classification tasks when gold labels are absent. We define this task as Classify-w/o-Gold and propose it as a new testbed for LLMs. ii) We introduce a benchmark, Know-No, comprising two existing classification tasks and one new task, to evaluate Classify-w/o-Gold. iii) This work defines and advocates for a new evaluation metric, OmniAccuracy, which assesses LLMs' performance in classification tasks both when gold labels are present and absent.
FOFO: A Benchmark to Evaluate LLMs' Format-Following Capability
Feb 28, 2024This paper presents FoFo, a pioneering benchmark for evaluating large language models' (LLMs) ability to follow complex, domain-specific formats, a crucial yet underexamined capability for their application as AI agents. Despite LLMs' advancements, existing benchmarks fail to assess their format-following proficiency adequately. FoFo fills this gap with a diverse range of real-world formats and instructions, developed through an AI-Human collaborative method. Our evaluation across both open-source (e.g., Llama 2, WizardLM) and closed-source (e.g., GPT-4, PALM2, Gemini) LLMs highlights three key findings: open-source models significantly lag behind closed-source ones in format adherence; LLMs' format-following performance is independent of their content generation quality; and LLMs' format proficiency varies across different domains. These insights suggest the need for specialized tuning for format-following skills and highlight FoFo's role in guiding the selection of domain-specific AI agents. FoFo is released here at https://github.com/SalesforceAIResearch/FoFo.
kNN-ICL: Compositional Task-Oriented Parsing Generalization with Nearest Neighbor In-Context Learning
Dec 17, 2023



Task-Oriented Parsing (TOP) enables conversational assistants to interpret user commands expressed in natural language, transforming them into structured outputs that combine elements of both natural language and intent/slot tags. Recently, Large Language Models (LLMs) have achieved impressive performance in synthesizing computer programs based on a natural language prompt, mitigating the gap between natural language and structured programs. Our paper focuses on harnessing the capabilities of LLMs for semantic parsing tasks, addressing the following three key research questions: 1) How can LLMs be effectively utilized for semantic parsing tasks? 2) What defines an effective prompt? and 3) How can LLM overcome the length constraint and streamline prompt design by including all examples as prompts? We introduce k Nearest Neighbor In-Context Learning(kNN-ICL), which simplifies prompt engineering by allowing it to be built on top of any design strategy while providing access to all demo examples. Extensive experiments show that: 1)Simple ICL without kNN search can achieve a comparable performance with strong supervised models on the TOP tasks, and 2) kNN-ICL significantly improves the comprehension of complex requests by seamlessly integrating ICL with a nearest-neighbor approach. Notably, this enhancement is achieved without the need for additional data or specialized prompts.
All Labels Together: Low-shot Intent Detection with an Efficient Label Semantic Encoding Paradigm
Sep 08, 2023



In intent detection tasks, leveraging meaningful semantic information from intent labels can be particularly beneficial for few-shot scenarios. However, existing few-shot intent detection methods either ignore the intent labels, (e.g. treating intents as indices) or do not fully utilize this information (e.g. only using part of the intent labels). In this work, we present an end-to-end One-to-All system that enables the comparison of an input utterance with all label candidates. The system can then fully utilize label semantics in this way. Experiments on three few-shot intent detection tasks demonstrate that One-to-All is especially effective when the training resource is extremely scarce, achieving state-of-the-art performance in 1-, 3- and 5-shot settings. Moreover, we present a novel pretraining strategy for our model that utilizes indirect supervision from paraphrasing, enabling zero-shot cross-domain generalization on intent detection tasks. Our code is at https://github.com/jiangshdd/AllLablesTogether.
Learning to Select from Multiple Options
Dec 01, 2022



Many NLP tasks can be regarded as a selection problem from a set of options, such as classification tasks, multi-choice question answering, etc. Textual entailment (TE) has been shown as the state-of-the-art (SOTA) approach to dealing with those selection problems. TE treats input texts as premises (P), options as hypotheses (H), then handles the selection problem by modeling (P, H) pairwise. Two limitations: first, the pairwise modeling is unaware of other options, which is less intuitive since humans often determine the best options by comparing competing candidates; second, the inference process of pairwise TE is time-consuming, especially when the option space is large. To deal with the two issues, this work first proposes a contextualized TE model (Context-TE) by appending other k options as the context of the current (P, H) modeling. Context-TE is able to learn more reliable decision for the H since it considers various context. Second, we speed up Context-TE by coming up with Parallel-TE, which learns the decisions of multiple options simultaneously. Parallel-TE significantly improves the inference speed while keeping comparable performance with Context-TE. Our methods are evaluated on three tasks (ultra-fine entity typing, intent detection and multi-choice QA) that are typical selection problems with different sizes of options. Experiments show our models set new SOTA performance; particularly, Parallel-TE is faster than the pairwise TE by k times in inference. Our code is publicly available at https://github.com/jiangshdd/LearningToSelect.