 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Visual Experience and Mapping Semantics through Whole-Brain Analysis Using fMRI Foundation Models
Nov 11, 2024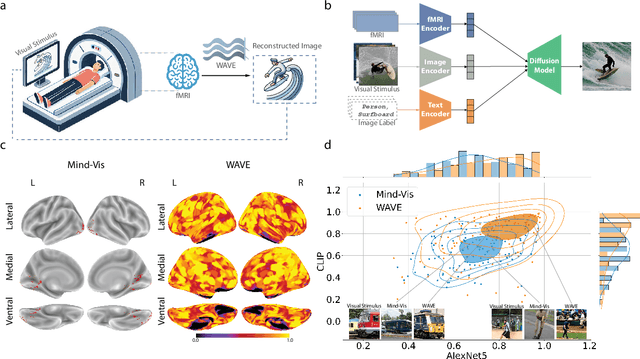



Neural decoding, the process of understanding how brain activity corresponds to different stimuli, has been a primary objective in cognitive sciences. Over the past three decades, advancements in functional Magnetic Resonance Imaging and machine learning have greatly improved our ability to map visual stimuli to brain activity, especially in the visual cortex. Concurrently, research has expanded into decoding more complex processes like language and memory across the whole brain, utilizing techniques to handle greater variability and improve signal accuracy. We argue that "seeing" involves more than just mapping visual stimuli onto the visual cortex; it engages the entire brain, as various emotions and cognitive states can emerge from observing different scenes. In this paper, we develop algorithms to enhance our understanding of visual processes by incorporating whole-brain activation maps while individuals are exposed to visual stimuli. We utilize large-scale fMRI encoders and Image generative models pre-trained on large public datasets, which are then fine-tuned through Image-fMRI contrastive learning. Our models hence can decode visual experience across the entire cerebral cortex, surpassing the traditional confines of the visual cortex. We first compare our method with state-of-the-art approaches to decoding visual processing and show improved predictive semantic accuracy by 43%. A network ablation analysis suggests that beyond the visual cortex, the default mode network contributes most to decoding stimuli, in line with the proposed role of this network in sense-making and semantic processing. Additionally, we implemented zero-shot imagination decoding on an extra validation dataset, achieving a p-value of 0.0206 for mapping the reconstructed images and ground-truth text stimuli, which substantiates the model's capability to capture semantic meanings across various scenarios.
kNN-ICL: Compositional Task-Oriented Parsing Generalization with Nearest Neighbor In-Context Learning
Dec 17, 2023



Task-Oriented Parsing (TOP) enables conversational assistants to interpret user commands expressed in natural language, transforming them into structured outputs that combine elements of both natural language and intent/slot tags. Recently, Large Language Models (LLMs) have achieved impressive performance in synthesizing computer programs based on a natural language prompt, mitigating the gap between natural language and structured programs. Our paper focuses on harnessing the capabilities of LLMs for semantic parsing tasks, addressing the following three key research questions: 1) How can LLMs be effectively utilized for semantic parsing tasks? 2) What defines an effective prompt? and 3) How can LLM overcome the length constraint and streamline prompt design by including all examples as prompts? We introduce k Nearest Neighbor In-Context Learning(kNN-ICL), which simplifies prompt engineering by allowing it to be built on top of any design strategy while providing access to all demo examples. Extensive experiments show that: 1)Simple ICL without kNN search can achieve a comparable performance with strong supervised models on the TOP tasks, and 2) kNN-ICL significantly improves the comprehension of complex requests by seamlessly integrating ICL with a nearest-neighbor approach. Notably, this enhancement is achieved without the need for additional data or specialized prompts.
Recurrent Transformer Encoders for Vision-based Estimation of Fatigue and Engagement in Cognitive Training Sessions
Apr 24, 2023
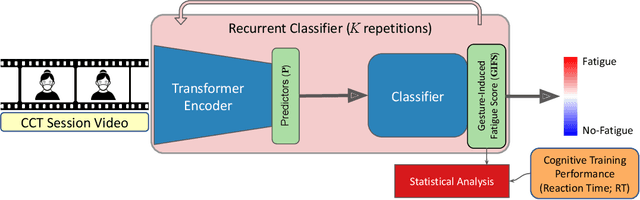
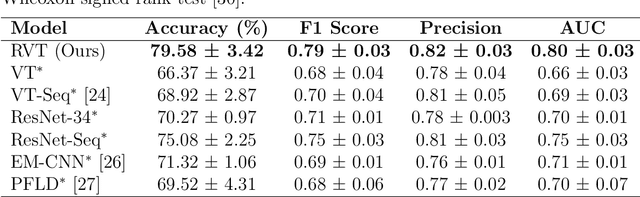
The effectiveness of computerized cognitive training in slowing cognitive decline and brain aging in dementia is often limited by the engagement of participants in the training. Monitoring older users' real-time engagement in domains of attention, motivation, and affect is crucial to understanding the overall effectiveness of such training. In this paper, we propose to predict engagement, quantified via an established mental fatigue measure assessing users' perceived attention, motivation, and affect throughout computerized cognitive training sessions, in older adults with mild cognitive impairment (MCI), by monitoring their real-time video-recorded facial gestures in training sessions. To achieve the goal, we used computer vision, analyzing video frames every 5 seconds to optimize the balance between information retention and data size, and developed a novel Recurrent Video Transformer (RVT). Our RVT model, which combines a clip-wise transformer encoder module and a session-wise Recurrent Neural Network (RNN) classifier, achieved the highest balanced accuracy, F1 score, and precision compared to other state-of-the-art models for both detecting mental fatigue/disengagement cases (binary classification) and rating the level of mental fatigue (multi-class classification). By leveraging dynamic temporal information, the RVT model demonstrates the potential to accurately predict engagement among computerized cognitive training users, which lays the foundation for future work to modulate the level of engagement in computerized cognitive training interventions. The code will be released.
PICASSO: Unleashing the Potential of GPU-centric Training for Wide-and-deep Recommender Systems
Apr 17, 2022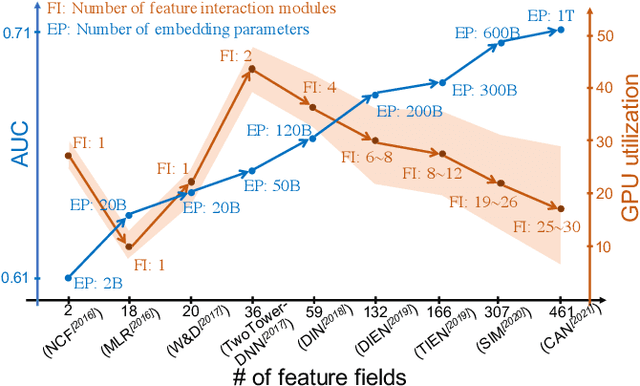

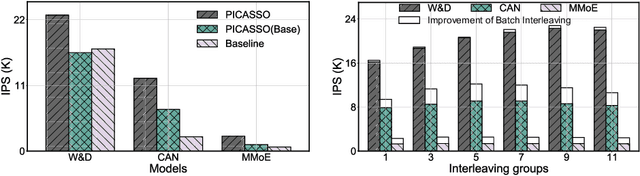
The development of personalized recommendation has significantly improved the accuracy of information matching and the revenue of e-commerce platforms. Recently, it has 2 trends: 1) recommender systems must be trained timely to cope with ever-growing new products and ever-changing user interests from online marketing and social network; 2) SOTA recommendation models introduce DNN modules to improve prediction accuracy. Traditional CPU-based recommender systems cannot meet these two trends, and GPU- centric training has become a trending approach. However, we observe that GPU devices in training recommender systems are underutilized, and they cannot attain an expected throughput improvement as what it has achieved in CV and NLP areas. This issue can be explained by two characteristics of these recommendation models: First, they contain up to a thousand input feature fields, introducing fragmentary and memory-intensive operations; Second, the multiple constituent feature interaction submodules introduce substantial small-sized compute kernels. To remove this roadblock to the development of recommender systems, we propose a novel framework named PICASSO to accelerate the training of recommendation models on commodity hardware. Specifically, we conduct a systematic analysis to reveal the bottlenecks encountered in training recommendation models. We leverage the model structure and data distribution to unleash the potential of hardware through our packing, interleaving, and caching optimization. Experiments show that PICASSO increases the hardware utilization by an order of magnitude on the basis of SOTA baselines and brings up to 6x throughput improvement for a variety of industrial recommendation models. Using the same hardware budget in production, PICASSO on average shortens the walltime of daily training tasks by 7 hours, significantly reducing the delay of continuous delivery.
Approximate Nearest Neighbor Search under Neural Similarity Metric for Large-Scale Recommendation
Feb 28, 2022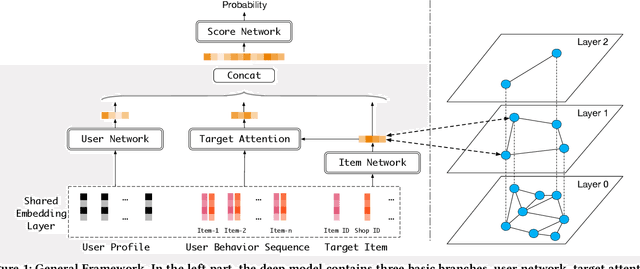

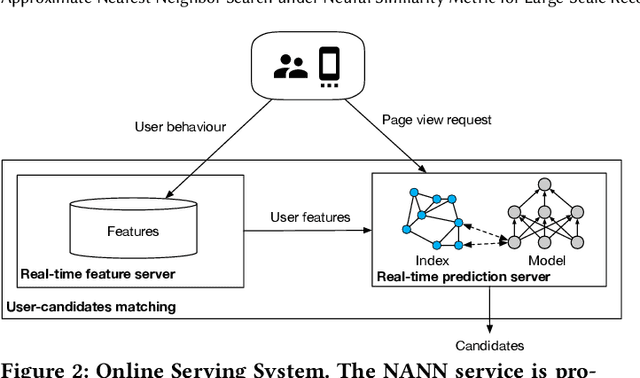
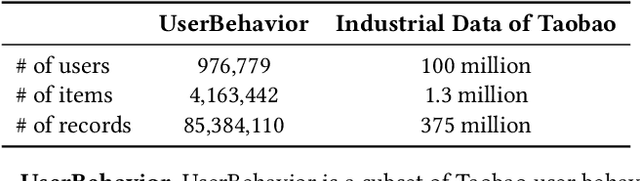
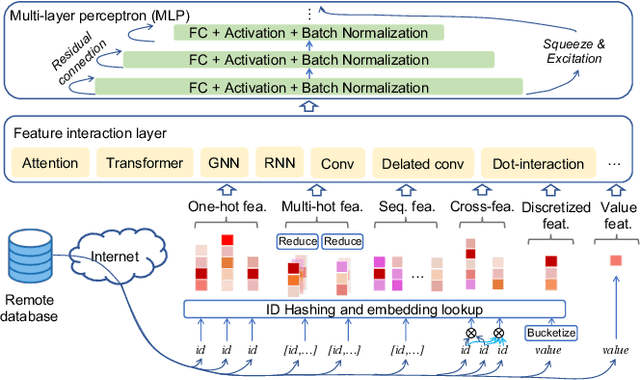
Model-based methods for recommender systems have been studied extensively for years. Modern recommender systems usually resort to 1) representation learning models which define user-item preference as the distance between their embedding representations, and 2) embedding-based Approximate Nearest Neighbor (ANN) search to tackle the efficiency problem introduced by large-scale corpus. While providing efficient retrieval, the embedding-based retrieval pattern also limits the model capacity since the form of user-item preference measure is restricted to the distance between their embedding representations. However, for other more precise user-item preference measures, e.g., preference scores directly derived from a deep neural network, they are computationally intractable because of the lack of an efficient retrieval method, and an exhaustive search for all user-item pairs is impractical. In this paper, we propose a novel method to extend ANN search to arbitrary matching functions, e.g., a deep neural network. Our main idea is to perform a greedy walk with a matching function in a similarity graph constructed from all items. To solve the problem that the similarity measures of graph construction and user-item matching function are heterogeneous, we propose a pluggable adversarial training task to ensure the graph search with arbitrary matching function can achieve fairly high precision. Experimental results in both open source and industry datasets demonstrate the effectiveness of our method. The proposed method has been fully deployed in the Taobao display advertising platform and brings a considerable advertising revenue increase. We also summarize our detailed experiences in deployment in this paper.