 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveyLens: A Research Discipline-Aware Benchmark for Automatic Survey Generation
Feb 11, 2026The exponential growth of scientific literature has driven the evolution of Automatic Survey Generation (ASG) from simple pipelines to multi-agent frameworks and commercial Deep Research agents. However, current ASG evaluation methods rely on generic metrics and are heavily biased toward Computer Science (CS), failing to assess whether ASG methods adhere to the distinct standards of various academic disciplines. Consequently, researchers, especially those outside CS, lack clear guidance on using ASG systems to yield high-quality surveys compliant with specific discipline standards. To bridge this gap, we introduce SurveyLens, the first discipline-aware benchmark evaluating ASG methods across diverse research disciplines. We construct SurveyLens-1k, a curated dataset of 1,000 high-quality human-written surveys spanning 10 disciplines. Subsequently, we propose a dual-lens evaluation framework: (1) Discipline-Aware Rubric Evaluation, which utilizes LLMs with human preference-aligned weights to assess adherence to domain-specific writing standards; and (2) Canonical Alignment Evaluation to rigorously measure content coverage and synthesis quality against human-written survey papers. We conduct extensive experiments by evaluating 11 state-of-the-art ASG methods on SurveyLens, including Vanilla LLMs, ASG systems, and Deep Research agents. Our analysis reveals the distinct strengths and weaknesses of each paradigm across fields, providing essential guidance for selecting tools tailored to specific disciplinary requirements.
Self-assessment, Exhibition, and Recognition: a Review of Personality in Large Language Models
Jun 25, 2024



As large language models (LLMs) appear to behave increasingly human-like in text-based interactions, more and more researchers become interested in investigating personality in LLMs. However, the diversity of psychological personality research and the rapid development of LLMs have led to a broad yet fragmented landscape of studies in this interdisciplinary field. Extensive studies across different research focuses, different personality psychometrics, and different LLMs make it challenging to have a holistic overview and further pose difficulties in applying findings to real-world applications. In this paper, we present a comprehensive review by categorizing current studies into three research problems: self-assessment, exhibition, and recognition, based on the intrinsic characteristics and external manifestations of personality in LLMs. For each problem, we provide a thorough analysis and conduct in-depth comparisons of their corresponding solutions. Besides, we summarize research findings and open challenges from current studies and further discuss their underlying causes. We also collect extensive publicly available resources to facilitate interested researchers and developers. Lastly, we discuss the potential future research directions and application scenarios. Our paper is the first comprehensive survey of up-to-date literature on personality in LLMs. By presenting a clear taxonomy, in-depth analysis, promising future directions, and extensive resource collections, we aim to provide a better understanding and facilitate further advancements in this emerging field.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024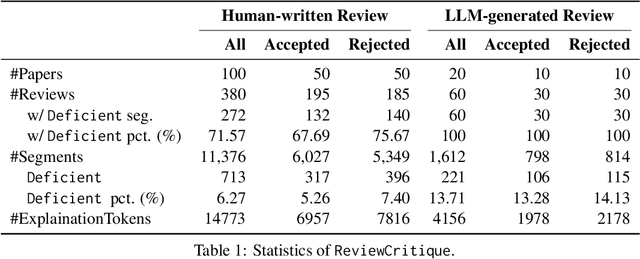
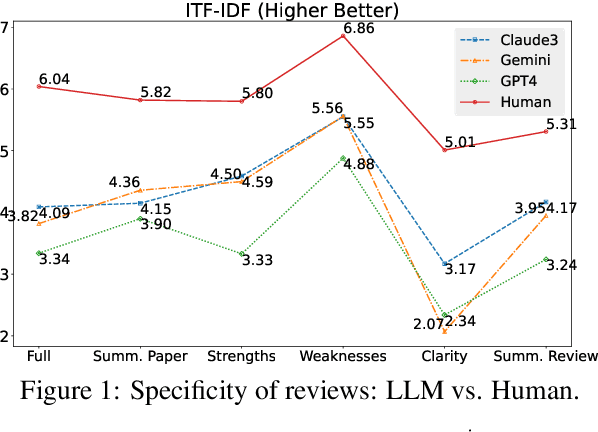

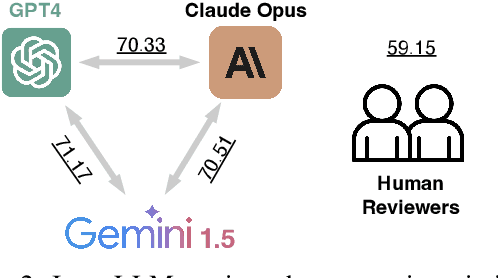
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
Toward Structure Fairness in Dynamic Graph Embedding: A Trend-aware Dual Debiasing Approach
Jun 19, 2024



Recent studies successfully learned static graph embeddings that are structurally fair by preventing the effectiveness disparity of high- and low-degree vertex groups in downstream graph mining tasks. However, achieving structure fairness in dynamic graph embedding remains an open problem. Neglecting degree changes in dynamic graphs will significantly impair embedding effectiveness without notably improving structure fairness. This is because the embedding performance of high-degree and low-to-high-degree vertices will significantly drop close to the generally poorer embedding performance of most slightly changed vertices in the long-tail part of the power-law distribution. We first identify biased structural evolutions in a dynamic graph based on the evolving trend of vertex degree and then propose FairDGE, the first structurally Fair Dynamic Graph Embedding algorithm. FairDGE learns biased structural evolutions by jointly embedding the connection changes among vertices and the long-short-term evolutionary trend of vertex degrees. Furthermore, a novel dual debiasing approach is devised to encode fair embeddings contrastively, customizing debiasing strategies for different biased structural evolutions. This innovative debiasing strategy breaks the effectiveness bottleneck of embeddings without notable fairness loss. Extensive experiments demonstrate that FairDGE achieves simultaneous improvement in the effectiveness and fairness of embeddings.
Personality-affected Emotion Generation in Dialog Systems
Apr 03, 2024



Generating appropriate emotions for responses is essential for dialog systems to provide human-like interaction in various application scenarios. Most previous dialog systems tried to achieve this goal by learning empathetic manners from anonymous conversational data. However, emotional responses generated by those methods may be inconsistent, which will decrease user engagement and service quality. Psychological findings suggest that the emotional expressions of humans are rooted in personality traits. Therefore, we propose a new task, Personality-affected Emotion Generation, to generate emotion based on the personality given to the dialog system and further investigate a solution through the personality-affected mood transition. Specifically, we first construct a daily dialog dataset, Personality EmotionLines Dataset (PELD), with emotion and personality annotations. Subsequently, we analyze the challenges in this task, i.e., (1) heterogeneously integrating personality and emotional factors and (2) extracting multi-granularity emotional information in the dialog context. Finally, we propose to model the personality as the transition weight by simulating the mood transition process in the dialog system and solve the challenges above. We conduct extensive experiments on PELD for evaluation. Results suggest that by adopting our method, the emotion generation performance is improved by 13% in macro-F1 and 5% in weighted-F1 from the BERT-base model.
Affective-NLI: Towards Accurate and Interpretable Personality Recognition in Conversation
Apr 03, 2024



Personality Recognition in Conversation (PRC) aims to identify the personality traits of speakers through textual dialogue content. It is essential for providing personalized services in various applications of Human-Computer Interaction (HCI), such as AI-based mental therapy and companion robots for the elderly. Most recent studies analyze the dialog content for personality classification yet overlook two major concerns that hinder their performance. First, crucial implicit factors contained in conversation, such as emotions that reflect the speakers' personalities are ignored. Second, only focusing on the input dialog content disregards the semantic understanding of personality itself, which reduces the interpretability of the results. In this paper, we propose Affective Natural Language Inference (Affective-NLI) for accurate and interpretable PRC. To utilize affectivity within dialog content for accurate personality recognition, we fine-tuned a pre-trained language model specifically for emotion recognition in conversations, facilitating real-time affective annotations for utterances. For interpretability of recognition results, we formulate personality recognition as an NLI problem by determining whether the textual description of personality labels is entailed by the dialog content. Extensive experiments on two daily conversation datasets suggest that Affective-NLI significantly outperforms (by 6%-7%) state-of-the-art approaches. Additionally, our Flow experiment demonstrates that Affective-NLI can accurately recognize the speaker's personality in the early stages of conversations by surpassing state-of-the-art methods with 22%-34%.
Low-Resource Court Judgment Summarization for Common Law Systems
Mar 07, 2024



Common law courts need to refer to similar precedents' judgments to inform their current decisions. Generating high-quality summaries of court judgment documents can facilitate legal practitioners to efficiently review previous cases and assist the general public in accessing how the courts operate and how the law is applied. Previous court judgment summarization research focuses on civil law or a particular jurisdiction's judgments. However, judges can refer to the judgments from all common law jurisdictions. Current summarization datasets are insufficient to satisfy the demands of summarizing precedents across multiple jurisdictions, especially when labeled data are scarce for many jurisdictions. To address the lack of datasets, we present CLSum, the first dataset for summarizing multi-jurisdictional common law court judgment documents. Besides, this is the first court judgment summarization work adopting large language models (LLMs) in data augmentation, summary generation, and evaluation. Specifically, we design an LLM-based data augmentation method incorporating legal knowledge. We also propose a legal knowledge enhanced evaluation metric based on LLM to assess the quality of generated judgment summaries. Our experimental results verify that the LLM-based summarization methods can perform well in the few-shot and zero-shot settings. Our LLM-based data augmentation method can mitigate the impact of low data resources. Furthermore, we carry out comprehensive comparative experiments to find essential model components and settings that are capable of enhancing summarization performance.
kNN-ICL: Compositional Task-Oriented Parsing Generalization with Nearest Neighbor In-Context Learning
Dec 17, 2023



Task-Oriented Parsing (TOP) enables conversational assistants to interpret user commands expressed in natural language, transforming them into structured outputs that combine elements of both natural language and intent/slot tags. Recently, Large Language Models (LLMs) have achieved impressive performance in synthesizing computer programs based on a natural language prompt, mitigating the gap between natural language and structured programs. Our paper focuses on harnessing the capabilities of LLMs for semantic parsing tasks, addressing the following three key research questions: 1) How can LLMs be effectively utilized for semantic parsing tasks? 2) What defines an effective prompt? and 3) How can LLM overcome the length constraint and streamline prompt design by including all examples as prompts? We introduce k Nearest Neighbor In-Context Learning(kNN-ICL), which simplifies prompt engineering by allowing it to be built on top of any design strategy while providing access to all demo examples. Extensive experiments show that: 1)Simple ICL without kNN search can achieve a comparable performance with strong supervised models on the TOP tasks, and 2) kNN-ICL significantly improves the comprehension of complex requests by seamlessly integrating ICL with a nearest-neighbor approach. Notably, this enhancement is achieved without the need for additional data or specialized prompts.
JPAVE: A Generation and Classification-based Model for Joint Product Attribute Prediction and Value Extraction
Nov 07, 2023



Product attribute value extraction is an important task in e-Commerce which can help several downstream applications such as product search and recommendation. Most previous models handle this task using sequence labeling or question answering method which rely on the sequential position information of values in the product text and are vulnerable to data discrepancy between training and testing. This limits their generalization ability to real-world scenario in which each product can have multiple descriptions across various shopping platforms with different composition of text and style. They also have limited zero-shot ability to new values. In this paper, we propose a multi-task learning model with value generation/classification and attribute prediction called JPAVE to predict values without the necessity of position information of values in the text. Furthermore, the copy mechanism in value generator and the value attention module in value classifier help our model address the data discrepancy issue by only focusing on the relevant part of input text and ignoring other information which causes the discrepancy issue such as sentence structure in the text. Besides, two variants of our model are designed for open-world and closed-world scenarios. In addition, copy mechanism introduced in the first variant based on value generation can improve its zero-shot ability for identifying unseen values. Experimental results on a public dataset demonstrate the superiority of our model compared with strong baselines and its generalization ability of predicting new values.
Aspect-based Meeting Transcript Summarization: A Two-Stage Approach with Weak Supervision on Sentence Classification
Nov 07, 2023



Aspect-based meeting transcript summarization aims to produce multiple summaries, each focusing on one aspect of content in a meeting transcript. It is challenging as sentences related to different aspects can mingle together, and those relevant to a specific aspect can be scattered throughout the long transcript of a meeting. The traditional summarization methods produce one summary mixing information of all aspects, which cannot deal with the above challenges of aspect-based meeting transcript summarization. In this paper, we propose a two-stage method for aspect-based meeting transcript summarization. To select the input content related to specific aspects, we train a sentence classifier on a dataset constructed from the AMI corpus with pseudo-labeling. Then we merge the sentences selected for a specific aspect as the input for the summarizer to produce the aspect-based summary. Experimental results on the AMI corpus outperform many strong baselines, which verifies the effectiveness of our proposed method.