 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudoSeer: a Search Engine for Pseudocode
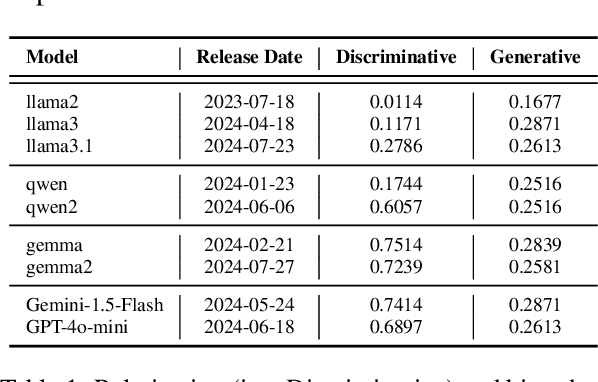
Nov 19, 2024A novel pseudocode search engine is designed to facilitate efficient retrieval and search of academic papers containing pseudocode. By leveraging Elasticsearch, the system enables users to search across various facets of a paper, such as the title, abstract, author information, and LaTeX code snippets, while supporting advanced features like combined facet searches and exact-match queries for more targeted results. A description of the data acquisition process is provided, with arXiv as the primary data source, along with methods for data extraction and text-based indexing, highlighting how different data elements are stored and optimized for search. A weighted BM25-based ranking algorithm is used by the search engine, and factors considered when prioritizing search results for both single and combined facet searches are described. We explain how each facet is weighted in a combined search. Several search engine results pages are displayed. Finally, there is a brief overview of future work and potential evaluation methodology for assessing the effectiveness and performance of the search engine is described.
Hey GPT, Can You be More Racist? Analysis from Crowdsourced Attempts to Elicit Biased Content from Generative AI
Oct 20, 2024

The widespread adoption of large language models (LLMs) and generative AI (GenAI) tools across diverse applications has amplified the importance of addressing societal biases inherent within these technologies. While the NLP community has extensively studied LLM bias, research investigating how non-expert users perceive and interact with biases from these systems remains limited. As these technologies become increasingly prevalent, understanding this question is crucial to inform model developers in their efforts to mitigate bias. To address this gap, this work presents the findings from a university-level competition, which challenged participants to design prompts for eliciting biased outputs from GenAI tools. We quantitatively and qualitatively analyze the competition submissions and identify a diverse set of biases in GenAI and strategies employed by participants to induce bias in GenAI. Our finding provides unique insights into how non-expert users perceive and interact with biases from GenAI tools.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024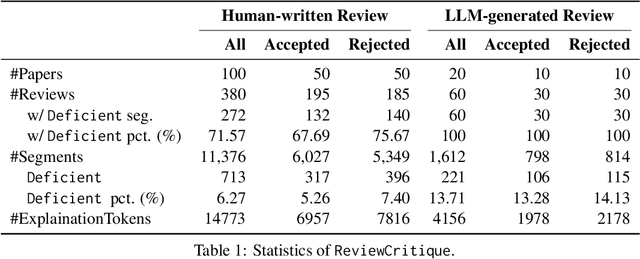
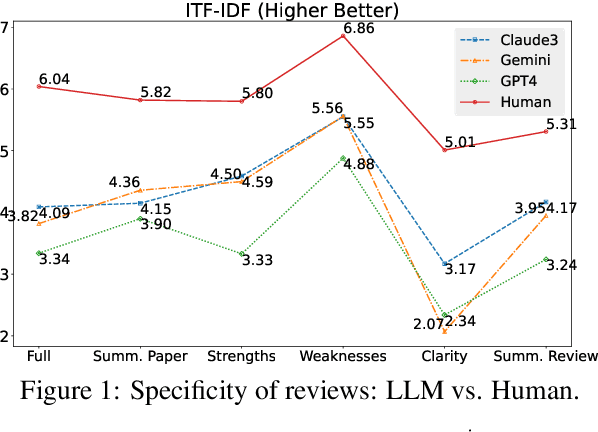

This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
Blind Spots and Biases: Exploring the Role of Annotator Cognitive Biases in NLP
Apr 29, 2024With the rapid proliferation of artificial intelligence, there is growing concern over its potential to exacerbate existing biases and societal disparities and introduce novel ones. This issue has prompted widespread attention from academia, policymakers, industry, and civil society. While evidence suggests that integrating human perspectives can mitigate bias-related issues in AI systems, it also introduces challenges associated with cognitive biases inherent in human decision-making. Our research focuses on reviewing existing methodologies and ongoing investigations aimed at understanding annotation attributes that contribute to bias.
"Confidently Nonsensical?'': A Critical Survey on the Perspectives and Challenges of 'Hallucinations' in NLP
Apr 11, 2024


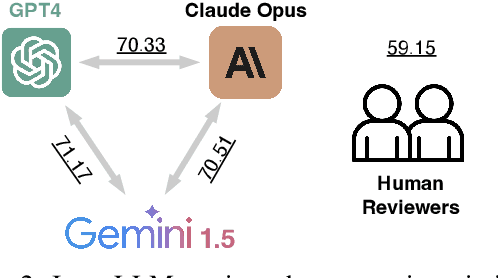
We investigate how hallucination in large language models (LLM) is characterized in peer-reviewed literature using a critical examination of 103 publications across NLP research. Through a comprehensive review of sociological and technological literature, we identify a lack of agreement with the term `hallucination.' Additionally, we conduct a survey with 171 practitioners from the field of NLP and AI to capture varying perspectives on hallucination. Our analysis underscores the necessity for explicit definitions and frameworks outlining hallucination within NLP, highlighting potential challenges, and our survey inputs provide a thematic understanding of the influence and ramifications of hallucination in society.
Automated Detection and Analysis of Data Practices Using A Real-World Corpus
Feb 16, 2024



Privacy policies are crucial for informing users about data practices, yet their length and complexity often deter users from reading them. In this paper, we propose an automated approach to identify and visualize data practices within privacy policies at different levels of detail. Leveraging crowd-sourced annotations from the ToS;DR platform, we experiment with various methods to match policy excerpts with predefined data practice descriptions. We further conduct a case study to evaluate our approach on a real-world policy, demonstrating its effectiveness in simplifying complex policies. Experiments show that our approach accurately matches data practice descriptions with policy excerpts, facilitating the presentation of simplified privacy information to users.
The Sentiment Problem: A Critical Survey towards Deconstructing Sentiment Analysis
Oct 18, 2023



We conduct an inquiry into the sociotechnical aspects of sentiment analysis (SA) by critically examining 189 peer-reviewed papers on their applications, models, and datasets. Our investigation stems from the recognition that SA has become an integral component of diverse sociotechnical systems, exerting influence on both social and technical users. By delving into sociological and technological literature on sentiment, we unveil distinct conceptualizations of this term in domains such as finance, government, and medicine. Our study exposes a lack of explicit definitions and frameworks for characterizing sentiment, resulting in potential challenges and biases. To tackle this issue, we propose an ethics sheet encompassing critical inquiries to guide practitioners in ensuring equitable utilization of SA. Our findings underscore the significance of adopting an interdisciplinary approach to defining sentiment in SA and offer a pragmatic solution for its implementation.
Leveraging Twitter Data for Sentiment Analysis of Transit User Feedback: An NLP Framework
Oct 11, 2023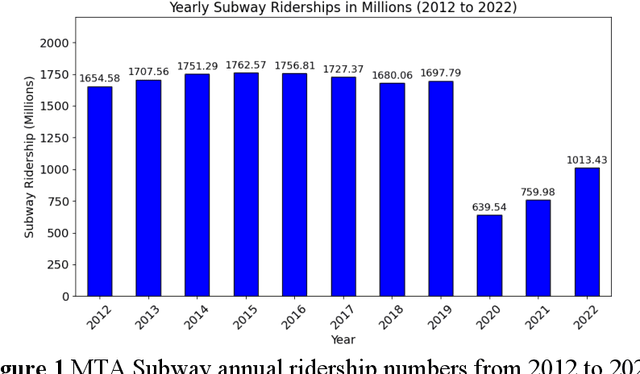

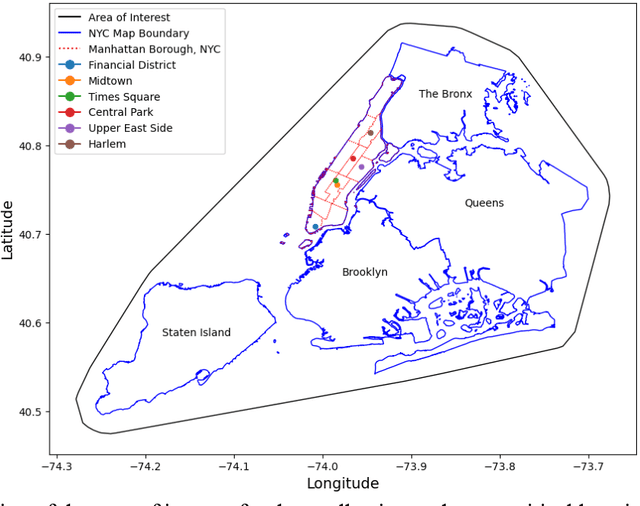

Traditional methods of collecting user feedback through transit surveys are often time-consuming, resource intensive, and costly. In this paper, we propose a novel NLP-based framework that harnesses the vast, abundant, and inexpensive data available on social media platforms like Twitter to understand users' perceptions of various service issues. Twitter, being a microblogging platform, hosts a wealth of real-time user-generated content that often includes valuable feedback and opinions on various products, services, and experiences. The proposed framework streamlines the process of gathering and analyzing user feedback without the need for costly and time-consuming user feedback surveys using two techniques. First, it utilizes few-shot learning for tweet classification within predefined categories, allowing effective identification of the issues described in tweets. It then employs a lexicon-based sentiment analysis model to assess the intensity and polarity of the tweet sentiments, distinguishing between positive, negative, and neutral tweets. The effectiveness of the framework was validated on a subset of manually labeled Twitter data and was applied to the NYC subway system as a case study. The framework accurately classifies tweets into predefined categories related to safety, reliability, and maintenance of the subway system and effectively measured sentiment intensities within each category. The general findings were corroborated through a comparison with an agency-run customer survey conducted in the same year. The findings highlight the effectiveness of the proposed framework in gauging user feedback through inexpensive social media data to understand the pain points of the transit system and plan for targeted improvements.
Automated Ableism: An Exploration of Explicit Disability Biases in Sentiment and Toxicity Analysis Models
Jul 18, 2023



We analyze sentiment analysis and toxicity detection models to detect the presence of explicit bias against people with disability (PWD). We employ the bias identification framework of Perturbation Sensitivity Analysis to examine conversations related to PWD on social media platforms, specifically Twitter and Reddit, in order to gain insight into how disability bias is disseminated in real-world social settings. We then create the \textit{Bias Identification Test in Sentiment} (BITS) corpus to quantify explicit disability bias in any sentiment analysis and toxicity detection models. Our study utilizes BITS to uncover significant biases in four open AIaaS (AI as a Service) sentiment analysis tools, namely TextBlob, VADER, Google Cloud Natural Language API, DistilBERT and two toxicity detection models, namely two versions of Toxic-BERT. Our findings indicate that all of these models exhibit statistically significant explicit bias against PWD.
* TrustNLP at ACL 2023