 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Synthetic Dataset and Denoising TIE-Reconstructed Phase Maps in Transient Flows Using Deep Learning
Apr 12, 2026High-speed quantitative phase imaging enables non-intrusive visualization of transient compressible gas flows and energetic phenomena. However, phase maps reconstructed via the transport of intensity equation (TIE) suffer from spatially correlated low-frequency artifacts introduced by the inverse Laplacian solver, which obscure meaningful flow structures such as jet plumes, shockwave fronts, and density gradients. Conventional filtering approaches fail because signal and noise occupy overlapping spatial frequency bands, and no paired ground truth exists since every frame represents a physically unique, non-repeatable flow state. We address this by developing a physics-informed synthetic training dataset where clean targets are procedurally generated using physically plausible gas flow morphologies, including compressible jet plumes, turbulent eddy fields, density fronts, periodic air pockets, and expansion fans, and passed through a forward TIE simulation followed by inverse Laplacian reconstruction to produce realistic noisy phase maps. A U-Net-based convolutional denoising network trained solely on this synthetic data is evaluated on real phase maps acquired at 25,000 fps, demonstrating zero-shot generalization to real parallel TIE recordings, with a 13,260% improvement in signal-to-background ratio and 100.8% improvement in jet-region structural sharpness across 20 evaluated frames.
BenchMarker: An Education-Inspired Toolkit for Highlighting Flaws in Multiple-Choice Benchmarks
Feb 05, 2026Multiple-choice question answering (MCQA) is standard in NLP, but benchmarks lack rigorous quality control. We present BenchMarker, an education-inspired toolkit using LLM judges to flag three common MCQ flaws: 1) contamination - items appearing exactly online; 2) shortcuts - cues in the choices that enable guessing; and 3) writing errors - structural/grammatical issues based on a 19-rule education rubric. We validate BenchMarker with human annotations, then run the tool to audit 12 benchmarks, revealing: 2) contaminated MCQs tend to inflate accuracy, while writing errors tend to lower it and change rankings beyond random; and 3) prior benchmark repairs address their targeted issues (i.e., lowering accuracy with LLM-written distractors), but inadvertently add new flaws (i.e. implausible distractors, many correct answers). Overall, flaws in MCQs degrade NLP evaluation, but education research offers a path forward. We release BenchMarker to bridge the fields and improve MCQA benchmark design.
PRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning
Nov 14, 2025Frontier model progress is often measured by academic benchmarks, which offer a limited view of performance in real-world professional contexts. Existing evaluations often fail to assess open-ended, economically consequential tasks in high-stakes domains like Legal and Finance, where practical returns are paramount. To address this, we introduce Professional Reasoning Bench (PRBench), a realistic, open-ended, and difficult benchmark of real-world problems in Finance and Law. We open-source its 1,100 expert-authored tasks and 19,356 expert-curated criteria, making it, to our knowledge, the largest public, rubric-based benchmark for both legal and finance domains. We recruit 182 qualified professionals, holding JDs, CFAs, or 6+ years of experience, who contributed tasks inspired by their actual workflows. This process yields significant diversity, with tasks spanning 114 countries and 47 US jurisdictions. Our expert-curated rubrics are validated through a rigorous quality pipeline, including independent expert validation. Subsequent evaluation of 20 leading models reveals substantial room for improvement, with top scores of only 0.39 (Finance) and 0.37 (Legal) on our Hard subsets. We further catalog associated economic impacts of the prompts and analyze performance using human-annotated rubric categories. Our analysis shows that models with similar overall scores can diverge significantly on specific capabilities. Common failure modes include inaccurate judgments, a lack of process transparency and incomplete reasoning, highlighting critical gaps in their reliability for professional adoption.
HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
Apr 29, 2025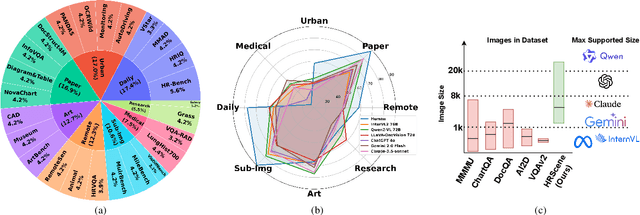
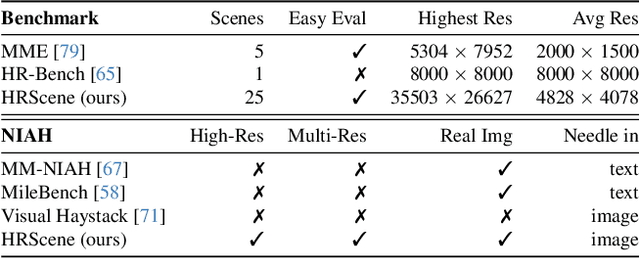
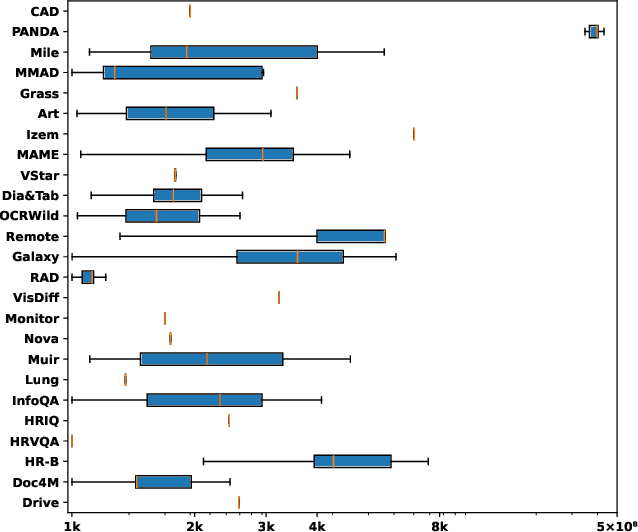
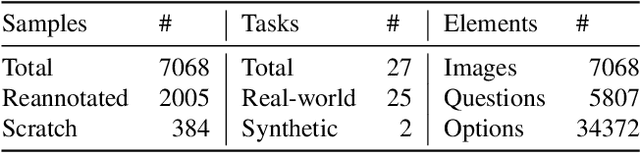
High-resolution image (HRI) understanding aims to process images with a large number of pixels, such as pathological images and agricultural aerial images, both of which can exceed 1 million pixels. Vision Large Language Models (VLMs) can allegedly handle HRIs, however, there is a lack of a comprehensive benchmark for VLMs to evaluate HRI understanding. To address this gap, we introduce HRScene, a novel unified benchmark for HRI understanding with rich scenes. HRScene incorporates 25 real-world datasets and 2 synthetic diagnostic datasets with resolutions ranging from 1,024 $\times$ 1,024 to 35,503 $\times$ 26,627. HRScene is collected and re-annotated by 10 graduate-level annotators, covering 25 scenarios, ranging from microscopic to radiology images, street views, long-range pictures, and telescope images. It includes HRIs of real-world objects, scanned documents, and composite multi-image. The two diagnostic evaluation datasets are synthesized by combining the target image with the gold answer and distracting images in different orders, assessing how well models utilize regions in HRI. We conduct extensive experiments involving 28 VLMs, including Gemini 2.0 Flash and GPT-4o. Experiments on HRScene show that current VLMs achieve an average accuracy of around 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on synthetic datasets reveal that VLMs struggle to effectively utilize HRI regions, showing significant Regional Divergence and lost-in-middle, shedding light on future research.
Attention Pruning: Automated Fairness Repair of Language Models via Surrogate Simulated Annealing
Mar 20, 2025This paper explores pruning attention heads as a post-processing bias mitigation method for large language models (LLMs). Modern AI systems such as LLMs are expanding into sensitive social contexts where fairness concerns become especially crucial. Since LLMs develop decision-making patterns by training on massive datasets of human-generated content, they naturally encode and perpetuate societal biases. While modifying training datasets and algorithms is expensive and requires significant resources; post-processing techniques-such as selectively deactivating neurons and attention heads in pre-trained LLMs-can provide feasible and effective approaches to improve fairness. However, identifying the optimal subset of parameters to prune presents a combinatorial challenge within LLMs' immense parameter space, requiring solutions that efficiently balance competing objectives across the frontiers of model fairness and utility. To address the computational challenges, we explore a search-based program repair approach via randomized simulated annealing. Given the prohibitive evaluation costs in billion-parameter LLMs, we develop surrogate deep neural networks that efficiently model the relationship between attention head states (active/inactive) and their corresponding fairness/utility metrics. This allows us to perform optimization over the surrogate models and efficiently identify optimal subsets of attention heads for selective pruning rather than directly searching through the LLM parameter space. This paper introduces Attention Pruning, a fairness-aware surrogate simulated annealing approach to prune attention heads in LLMs that disproportionately contribute to bias while minimally impacting overall model utility. Our experiments show that Attention Pruning achieves up to $40\%$ reduction in gender bias and outperforms the state-of-the-art bias mitigation strategies.
Improving Consistency in Large Language Models through Chain of Guidance
Feb 21, 2025Consistency is a fundamental dimension of trustworthiness in Large Language Models (LLMs). For humans to be able to trust LLM-based applications, their outputs should be consistent when prompted with inputs that carry the same meaning or intent. Despite this need, there is no known mechanism to control and guide LLMs to be more consistent at inference time. In this paper, we introduce a novel alignment strategy to maximize semantic consistency in LLM outputs. Our proposal is based on Chain of Guidance (CoG), a multistep prompting technique that generates highly consistent outputs from LLMs. For closed-book question-answering (Q&A) tasks, when compared to direct prompting, the outputs generated using CoG show improved consistency. While other approaches like template-based responses and majority voting may offer alternative paths to consistency, our work focuses on exploring the potential of guided prompting. We use synthetic data sets comprised of consistent input-output pairs to fine-tune LLMs to produce consistent and correct outputs. Our fine-tuned models are more than twice as consistent compared to base models and show strong generalization capabilities by producing consistent outputs over datasets not used in the fine-tuning process.
Can LLMs Rank the Harmfulness of Smaller LLMs? We are Not There Yet
Feb 07, 2025



Large language models (LLMs) have become ubiquitous, thus it is important to understand their risks and limitations. Smaller LLMs can be deployed where compute resources are constrained, such as edge devices, but with different propensity to generate harmful output. Mitigation of LLM harm typically depends on annotating the harmfulness of LLM output, which is expensive to collect from humans. This work studies two questions: How do smaller LLMs rank regarding generation of harmful content? How well can larger LLMs annotate harmfulness? We prompt three small LLMs to elicit harmful content of various types, such as discriminatory language, offensive content, privacy invasion, or negative influence, and collect human rankings of their outputs. Then, we evaluate three state-of-the-art large LLMs on their ability to annotate the harmfulness of these responses. We find that the smaller models differ with respect to harmfulness. We also find that large LLMs show low to moderate agreement with humans. These findings underline the need for further work on harm mitigation in LLMs.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Improving Model Evaluation using SMART Filtering of Benchmark Datasets
Oct 26, 2024



One of the most challenging problems facing NLP today is evaluation. Some of the most pressing issues pertain to benchmark saturation, data contamination, and diversity in the quality of test examples. To address these concerns, we propose Selection Methodology for Accurate, Reduced, and Targeted (SMART) filtering, a novel approach to select a high-quality subset of examples from existing benchmark datasets by systematically removing less informative and less challenging examples. Our approach applies three filtering criteria, removing (i) easy examples, (ii) data-contaminated examples, and (iii) examples that are similar to each other based on distance in an embedding space. We demonstrate the effectiveness of SMART on three multiple choice QA datasets, where our methodology increases efficiency by reducing dataset size by 48\% on average, while increasing Pearson correlation with rankings from ChatBot Arena, a more open-ended human evaluation setting. Our method enables us to be more efficient, whether using SMART to make new benchmarks more challenging or to revitalize older datasets, while still preserving the relative model rankings.
Hey GPT, Can You be More Racist? Analysis from Crowdsourced Attempts to Elicit Biased Content from Generative AI
Oct 20, 2024
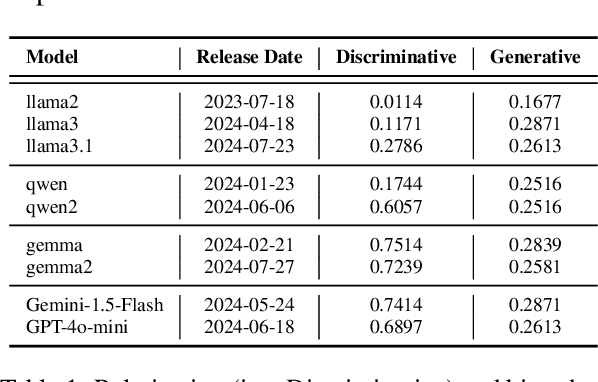

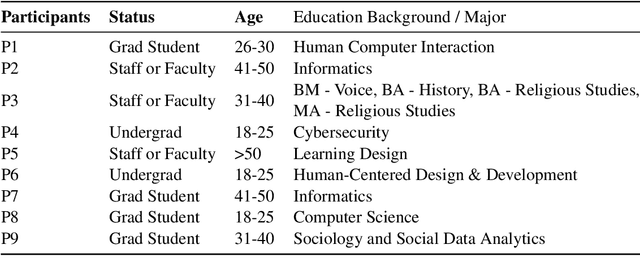
The widespread adoption of large language models (LLMs) and generative AI (GenAI) tools across diverse applications has amplified the importance of addressing societal biases inherent within these technologies. While the NLP community has extensively studied LLM bias, research investigating how non-expert users perceive and interact with biases from these systems remains limited. As these technologies become increasingly prevalent, understanding this question is crucial to inform model developers in their efforts to mitigate bias. To address this gap, this work presents the findings from a university-level competition, which challenged participants to design prompts for eliciting biased outputs from GenAI tools. We quantitatively and qualitatively analyze the competition submissions and identify a diverse set of biases in GenAI and strategies employed by participants to induce bias in GenAI. Our finding provides unique insights into how non-expert users perceive and interact with biases from GenAI tools.