 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Improving Consistency in Large Language Models through Chain of Guidance
Feb 21, 2025Consistency is a fundamental dimension of trustworthiness in Large Language Models (LLMs). For humans to be able to trust LLM-based applications, their outputs should be consistent when prompted with inputs that carry the same meaning or intent. Despite this need, there is no known mechanism to control and guide LLMs to be more consistent at inference time. In this paper, we introduce a novel alignment strategy to maximize semantic consistency in LLM outputs. Our proposal is based on Chain of Guidance (CoG), a multistep prompting technique that generates highly consistent outputs from LLMs. For closed-book question-answering (Q&A) tasks, when compared to direct prompting, the outputs generated using CoG show improved consistency. While other approaches like template-based responses and majority voting may offer alternative paths to consistency, our work focuses on exploring the potential of guided prompting. We use synthetic data sets comprised of consistent input-output pairs to fine-tune LLMs to produce consistent and correct outputs. Our fine-tuned models are more than twice as consistent compared to base models and show strong generalization capabilities by producing consistent outputs over datasets not used in the fine-tuning process.
On the Performance of IRS-Assisted SSK and RPM over Rician Fading Channels
Apr 10, 2024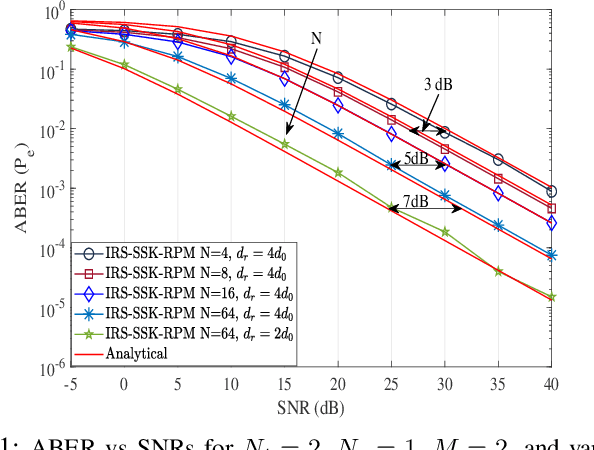
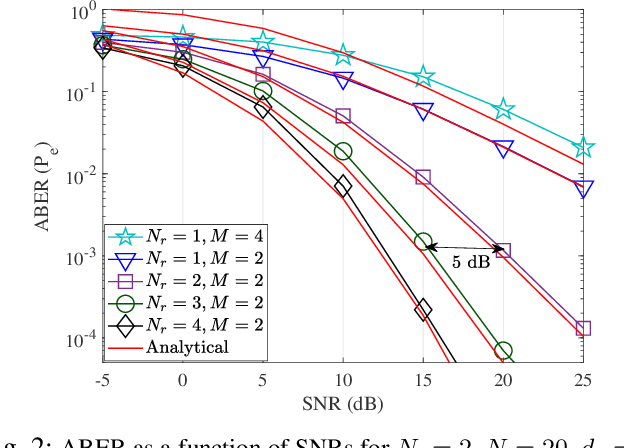
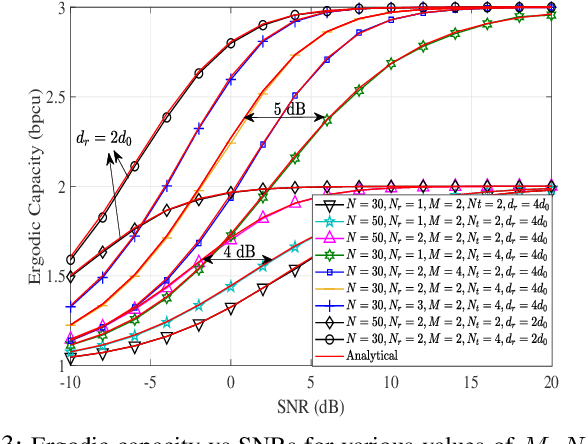

This paper presents the index modulation, that is, the space-shift keying (SSK) and reflection phase modulation (RPM) schemes for intelligent reflecting surface (IRS)-assisted wireless network. IRS simultaneously reflects the incoming information signal from the base station and explicitly encodes the local information bits in the reflection phase shift of IRS elements. The phase shift of the IRS elements is employed according to local data from the RPM constellation. A joint detection using a maximum-likelihood (ML) decoder is performed for the SSK and RPM symbols over a realistic fading scenario modeled as the Rician fading channel. The pairwise error probability over Rician fading channels is derived and utilized to determine the average bit error rate. In addition, the ergodic capacity of the presented system is derived. The derived analytical results are verified and are in exact agreement with Monte-Carlo simulations.
Semantic Consistency for Assuring Reliability of Large Language Models
Aug 17, 2023Large Language Models (LLMs) exhibit remarkable fluency and competence across various natural language tasks. However, recent research has highlighted their sensitivity to variations in input prompts. To deploy LLMs in a safe and reliable manner, it is crucial for their outputs to be consistent when prompted with expressions that carry the same meaning or intent. While some existing work has explored how state-of-the-art LLMs address this issue, their evaluations have been confined to assessing lexical equality of single- or multi-word answers, overlooking the consistency of generative text sequences. For a more comprehensive understanding of the consistency of LLMs in open-ended text generation scenarios, we introduce a general measure of semantic consistency, and formulate multiple versions of this metric to evaluate the performance of various LLMs. Our proposal demonstrates significantly higher consistency and stronger correlation with human evaluations of output consistency than traditional metrics based on lexical consistency. Finally, we propose a novel prompting strategy, called Ask-to-Choose (A2C), to enhance semantic consistency. When evaluated for closed-book question answering based on answer variations from the TruthfulQA benchmark, A2C increases accuracy metrics for pretrained and finetuned LLMs by up to 47%, and semantic consistency metrics for instruction-tuned models by up to 7-fold.
Measuring Reliability of Large Language Models through Semantic Consistency
Nov 10, 2022While large pretrained language models (PLMs) demonstrate incredible fluency and performance on many natural language tasks, recent work has shown that well-performing PLMs are very sensitive to what prompts are feed into them. Even when prompts are semantically identical, language models may give very different answers. When considering safe and trustworthy deployments of PLMs we would like their outputs to be consistent under prompts that mean the same thing or convey the same intent. While some work has looked into how state-of-the-art PLMs address this need, they have been limited to only evaluating lexical equality of single- or multi-word answers and do not address consistency of generative text sequences. In order to understand consistency of PLMs under text generation settings, we develop a measure of semantic consistency that allows the comparison of open-ended text outputs. We implement several versions of this consistency metric to evaluate the performance of a number of PLMs on paraphrased versions of questions in the TruthfulQA dataset, we find that our proposed metrics are considerably more consistent than traditional metrics embodying lexical consistency, and also correlate with human evaluation of output consistency to a higher degree.
AskYourDB: An end-to-end system for querying and visualizing relational databases using natural language
Oct 16, 2022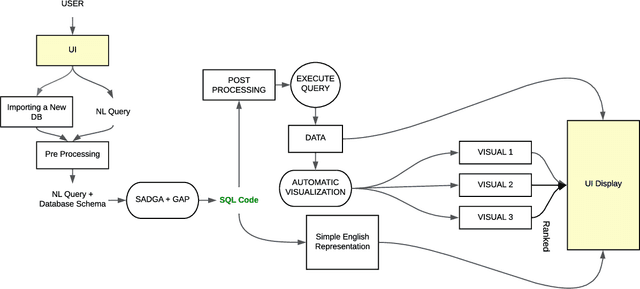
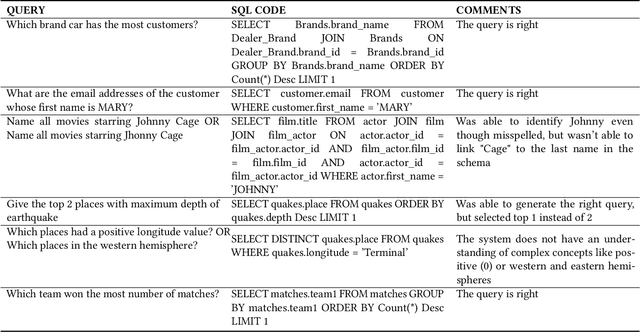
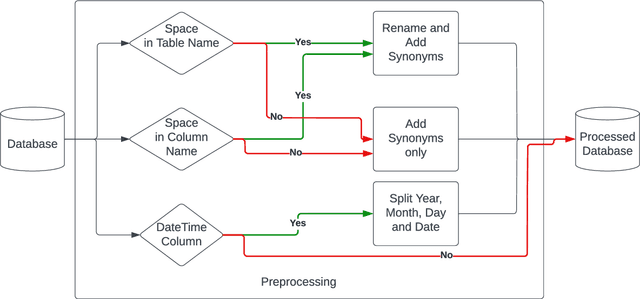

Querying databases for the right information is a time consuming and error-prone task and often requires experienced professionals for the job. Furthermore, the user needs to have some prior knowledge about the database. There have been various efforts to develop an intelligence which can help business users to query databases directly. However, there has been some successes, but very little in terms of testing and deploying those for real world users. In this paper, we propose a semantic parsing approach to address the challenge of converting complex natural language into SQL and institute a product out of it. For this purpose, we modified state-of-the-art models, by various pre and post processing steps which make the significant part when a model is deployed in production. To make the product serviceable to businesses we added an automatic visualization framework over the queried results.
GATE: Gated Additive Tree Ensemble for Tabular Classification and Regression
Jul 19, 2022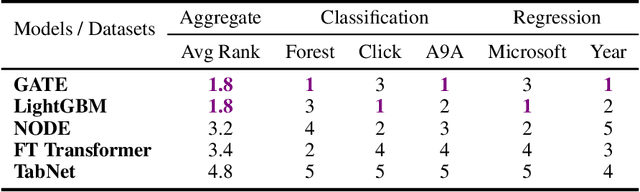
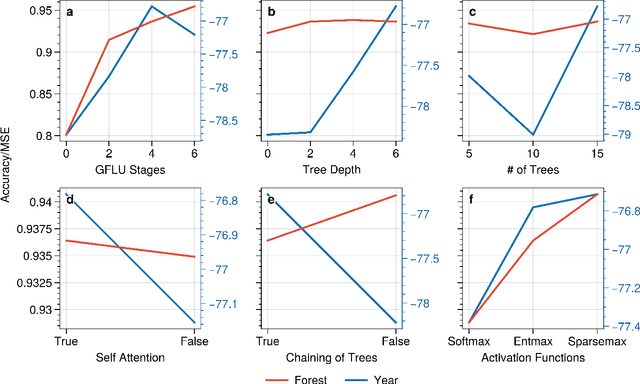

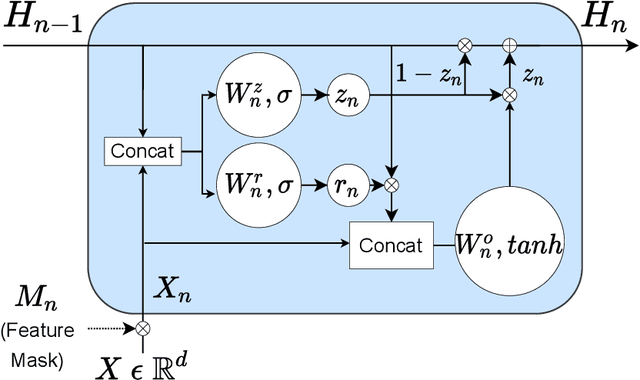
We propose a novel high-performance, parameter and computationally efficient deep learning architecture for tabular data, Gated Additive Tree Ensemble(GATE). GATE uses a gating mechanism, inspired from GRU, as a feature representation learning unit with an in-built feature selection mechanism. We combine it with an ensemble of differentiable, non-linear decision trees, re-weighted with simple self-attention to predict our desired output. We demonstrate that GATE is a competitive alternative to SOTA approaches like GBDTs, NODE, FT Transformers, etc. by experiments on several public datasets (both classification and regression). The code will be uploaded as soon as the paper comes out of review.
Multi-Image Visual Question Answering
Dec 27, 2021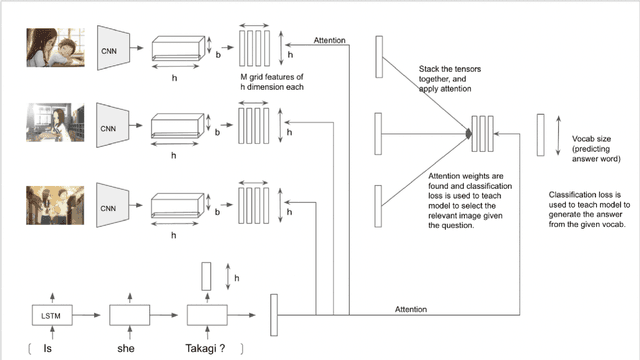


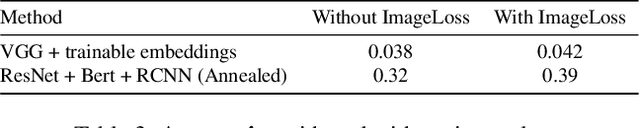
While a lot of work has been done on developing models to tackle the problem of Visual Question Answering, the ability of these models to relate the question to the image features still remain less explored. We present an empirical study of different feature extraction methods with different loss functions. We propose New dataset for the task of Visual Question Answering with multiple image inputs having only one ground truth, and benchmark our results on them. Our final model utilising Resnet + RCNN image features and Bert embeddings, inspired from stacked attention network gives 39% word accuracy and 99% image accuracy on CLEVER+TinyImagenet dataset.
Exploration of Visual Features and their weighted-additive fusion for Video Captioning
Jan 14, 2021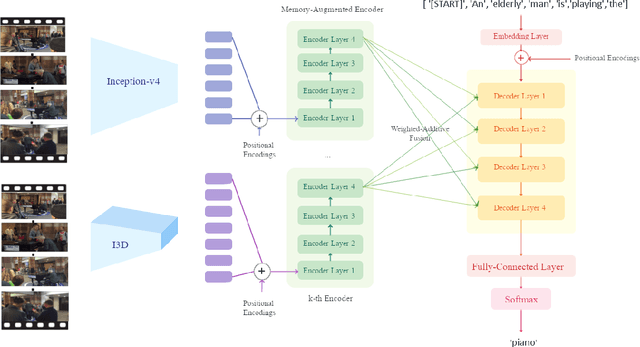
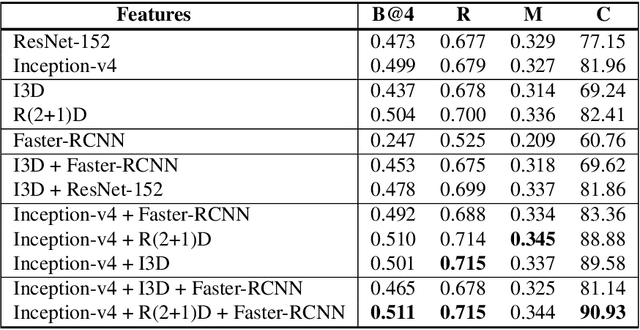
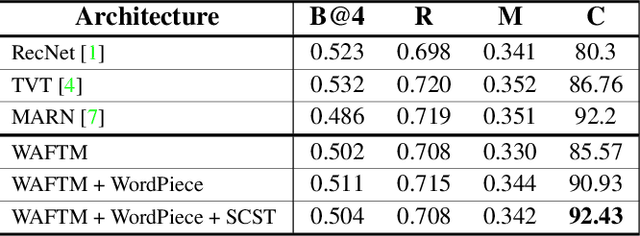

Video captioning is a popular task that challenges models to describe events in videos using natural language. In this work, we investigate the ability of various visual feature representations derived from state-of-the-art convolutional neural networks to capture high-level semantic context. We introduce the Weighted Additive Fusion Transformer with Memory Augmented Encoders (WAFTM), a captioning model that incorporates memory in a transformer encoder and uses a novel method, to fuse features, that ensures due importance is given to more significant representations. We illustrate a gain in performance realized by applying Word-Piece Tokenization and a popular REINFORCE algorithm. Finally, we benchmark our model on two datasets and obtain a CIDEr of 92.4 on MSVD and a METEOR of 0.091 on the ActivityNet Captions Dataset.