 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCompass: Towards Reliable Evaluation of Agentic Workflows in Production
Sep 18, 2025With the growing adoption of Large Language Models (LLMs) in automating complex, multi-agent workflows, organizations face mounting risks from errors, emergent behaviors, and systemic failures that current evaluation methods fail to capture. We present AgentCompass, the first evaluation framework designed specifically for post-deployment monitoring and debugging of agentic workflows. AgentCompass models the reasoning process of expert debuggers through a structured, multi-stage analytical pipeline: error identification and categorization, thematic clustering, quantitative scoring, and strategic summarization. The framework is further enhanced with a dual memory system-episodic and semantic-that enables continual learning across executions. Through collaborations with design partners, we demonstrate the framework's practical utility on real-world deployments, before establishing its efficacy against the publicly available TRAIL benchmark. AgentCompass achieves state-of-the-art results on key metrics, while uncovering critical issues missed in human annotations, underscoring its role as a robust, developer-centric tool for reliable monitoring and improvement of agentic systems in production.
Exploration of Visual Features and their weighted-additive fusion for Video Captioning
Jan 14, 2021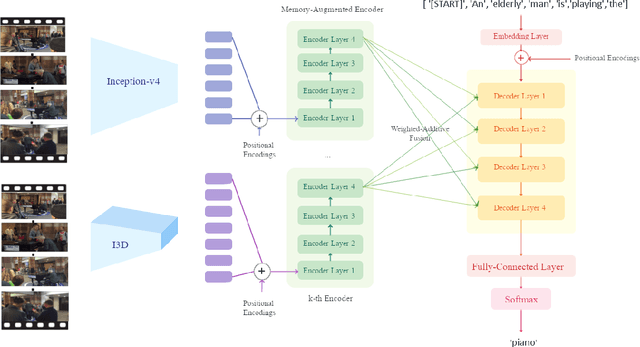
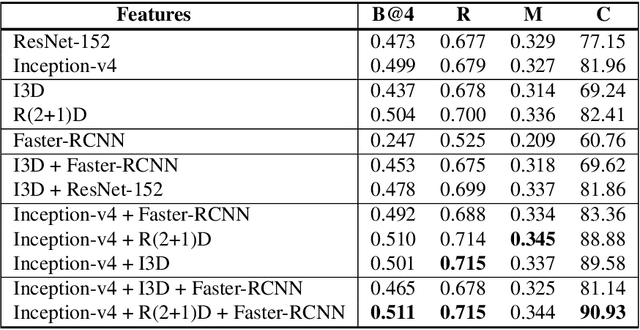
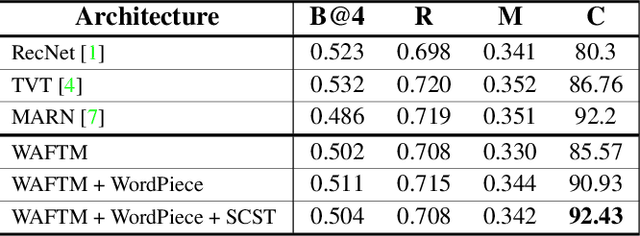

Video captioning is a popular task that challenges models to describe events in videos using natural language. In this work, we investigate the ability of various visual feature representations derived from state-of-the-art convolutional neural networks to capture high-level semantic context. We introduce the Weighted Additive Fusion Transformer with Memory Augmented Encoders (WAFTM), a captioning model that incorporates memory in a transformer encoder and uses a novel method, to fuse features, that ensures due importance is given to more significant representations. We illustrate a gain in performance realized by applying Word-Piece Tokenization and a popular REINFORCE algorithm. Finally, we benchmark our model on two datasets and obtain a CIDEr of 92.4 on MSVD and a METEOR of 0.091 on the ActivityNet Captions Dataset.
Knowledge Fusion Transformers for Video Action Recognition
Sep 30, 2020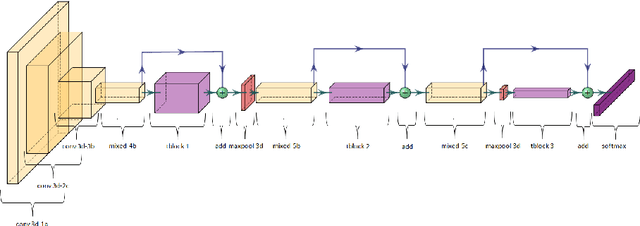
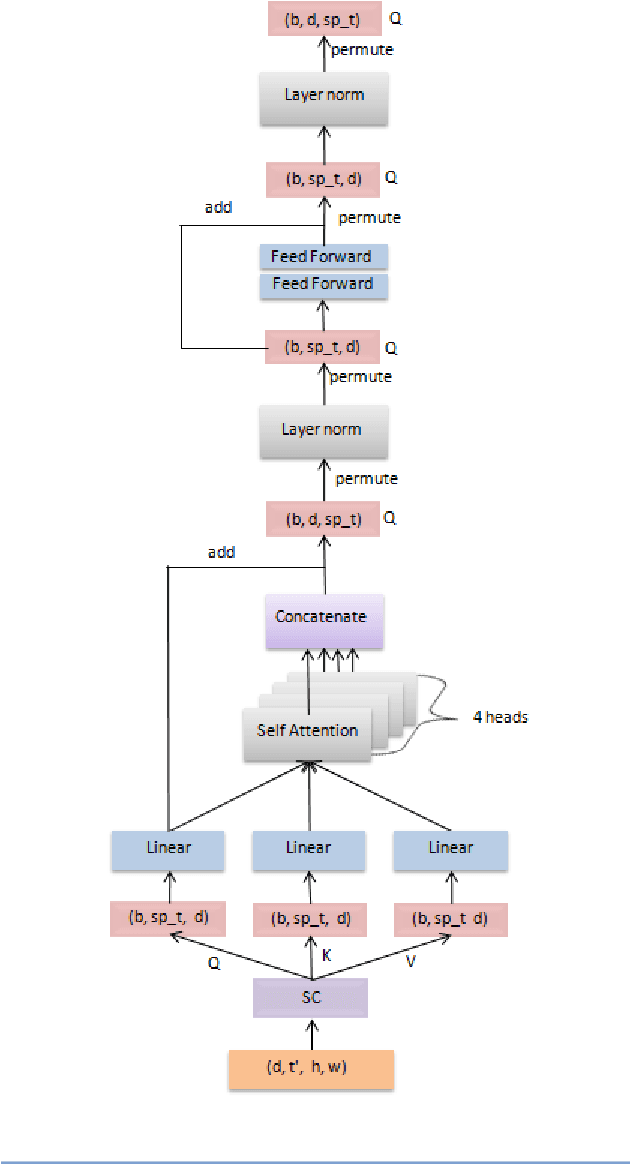
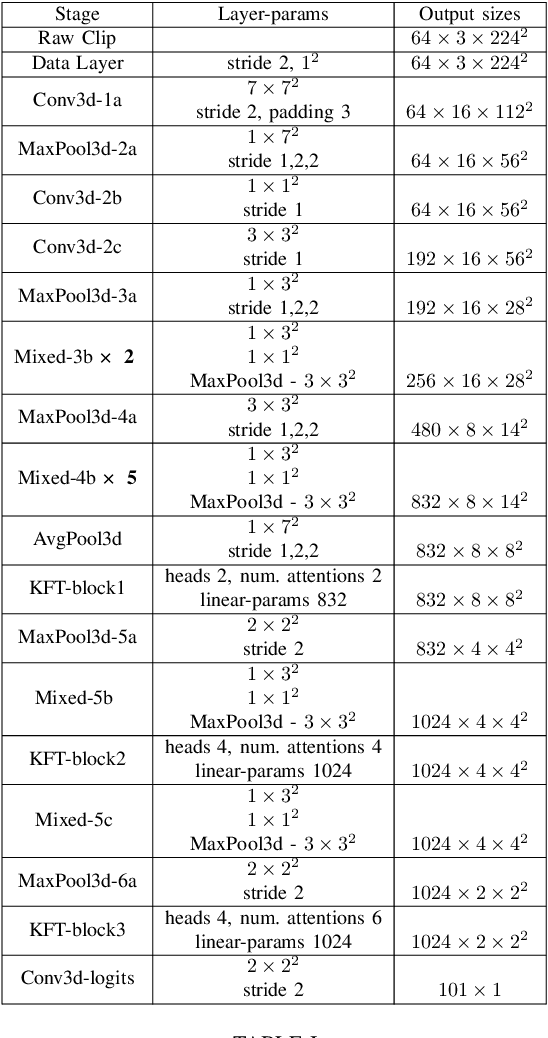

We introduce Knowledge Fusion Transformers for video action classification. We present a self-attention based feature enhancer to fuse action knowledge in 3D inception based spatio-temporal context of the video clip intended to be classified. We show, how using only one stream networks and with little or, no pretraining can pave the way for a performance close to the current state-of-the-art. Additionally, we present how different self-attention architectures used at different levels of the network can be blended-in to enhance feature representation. Our architecture is trained and evaluated on UCF-101 and Charades dataset, where it is competitive with the state of the art. It also exceeds by a large gap from single stream networks with no to less pretraining.