 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building Text-To-Speech Systems for the Next Billion Users
Nov 17, 2022

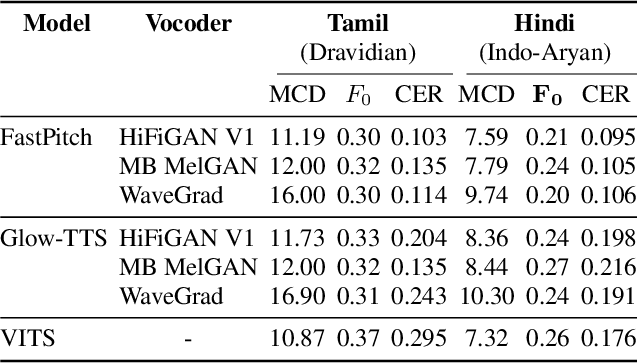

Deep learning based text-to-speech (TTS) systems have been evolving rapidly with advances in model architectures, training methodologies, and generalization across speakers and languages. However, these advances have not been thoroughly investigated for Indian language speech synthesis. Such investigation is computationally expensive given the number and diversity of Indian languages, relatively lower resource availability, and the diverse set of advances in neural TTS that remain untested. In this paper, we evaluate the choice of acoustic models, vocoders, supplementary loss functions, training schedules, and speaker and language diversity for Dravidian and Indo-Aryan languages. Based on this, we identify monolingual models with FastPitch and HiFi-GAN V1, trained jointly on male and female speakers to perform the best. With this setup, we train and evaluate TTS models for 13 languages and find our models to significantly improve upon existing models in all languages as measured by mean opinion scores. We open-source all models on the Bhashini platform.
Exploration of Visual Features and their weighted-additive fusion for Video Captioning
Jan 14, 2021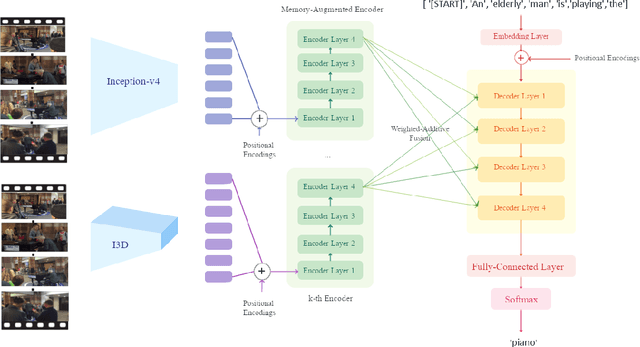
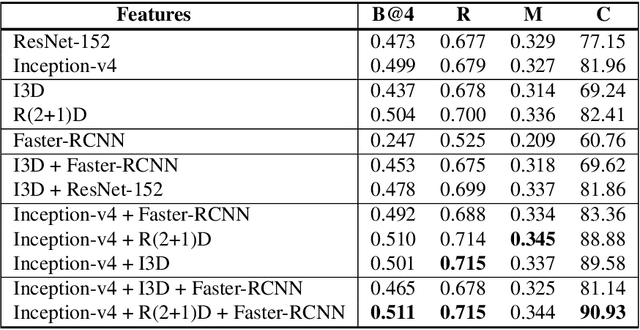
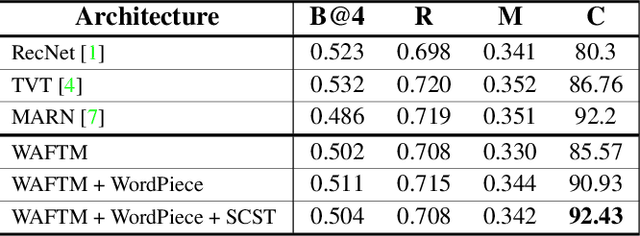

Video captioning is a popular task that challenges models to describe events in videos using natural language. In this work, we investigate the ability of various visual feature representations derived from state-of-the-art convolutional neural networks to capture high-level semantic context. We introduce the Weighted Additive Fusion Transformer with Memory Augmented Encoders (WAFTM), a captioning model that incorporates memory in a transformer encoder and uses a novel method, to fuse features, that ensures due importance is given to more significant representations. We illustrate a gain in performance realized by applying Word-Piece Tokenization and a popular REINFORCE algorithm. Finally, we benchmark our model on two datasets and obtain a CIDEr of 92.4 on MSVD and a METEOR of 0.091 on the ActivityNet Captions Dataset.