 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavLink: Compact Audio--Text Embeddings with a Global Whisper Token
Jan 21, 2026Whisper has become the de-facto encoder for extracting general-purpose audio features in large audio-language models, where a 30-second clip is typically represented by 1500 frame features projected into an LLM. In contrast, audio-text embedding models like CLAP-based models have largely relied on alternative audio encoders (e.g., HTS-AT, PaSST), and have not leveraged Whisper effectively. We present WavLink, a compact audio-text embedding model that augments Whisper encoder with a learnable global token, trained jointly with a text encoder. Through a systematic study of design choices, including pretrained text encoders, loss functions, training modes, and data mixtures, we identify configurations that yield state-of-the-art retrieval performance. Our two-stage training recipe across three model sizes, combined with Matryoshka-style supervision, improves scalability, enabling 8x smaller embeddings with minimal performance drop. WavLink also demonstrates competitive performance on AIR-Bench with MCQs and zero-shot classification.
Competitive Audio-Language Models with Data-Efficient Single-Stage Training on Public Data
Sep 09, 2025Large language models (LLMs) have transformed NLP, yet their integration with audio remains underexplored -- despite audio's centrality to human communication. We introduce Falcon3-Audio, a family of Audio-Language Models (ALMs) built on instruction-tuned LLMs and Whisper encoders. Using a remarkably small amount of public audio data -- less than 30K hours (5K unique) -- Falcon3-Audio-7B matches the best reported performance among open-weight models on the MMAU benchmark, with a score of 64.14, matching R1-AQA, while distinguishing itself through superior data and parameter efficiency, single-stage training, and transparency. Notably, our smallest 1B model remains competitive with larger open models ranging from 2B to 13B parameters. Through extensive ablations, we find that common complexities -- such as curriculum learning, multiple audio encoders, and intricate cross-attention connectors -- are not required for strong performance, even compared to models trained on over 500K hours of data.
Towards Building Text-To-Speech Systems for the Next Billion Users
Nov 17, 2022Deep learning based text-to-speech (TTS) systems have been evolving rapidly with advances in model architectures, training methodologies, and generalization across speakers and languages. However, these advances have not been thoroughly investigated for Indian language speech synthesis. Such investigation is computationally expensive given the number and diversity of Indian languages, relatively lower resource availability, and the diverse set of advances in neural TTS that remain untested. In this paper, we evaluate the choice of acoustic models, vocoders, supplementary loss functions, training schedules, and speaker and language diversity for Dravidian and Indo-Aryan languages. Based on this, we identify monolingual models with FastPitch and HiFi-GAN V1, trained jointly on male and female speakers to perform the best. With this setup, we train and evaluate TTS models for 13 languages and find our models to significantly improve upon existing models in all languages as measured by mean opinion scores. We open-source all models on the Bhashini platform.
Hate-CLIPper: Multimodal Hateful Meme Classification based on Cross-modal Interaction of CLIP Features
Oct 17, 2022
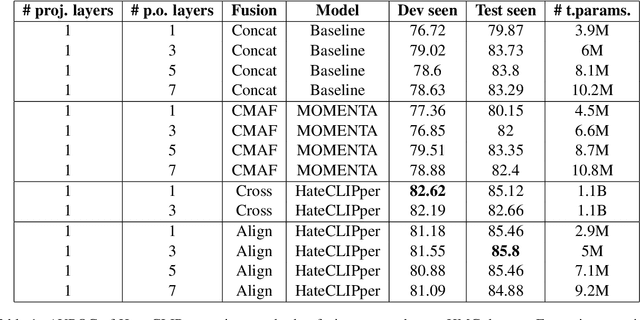

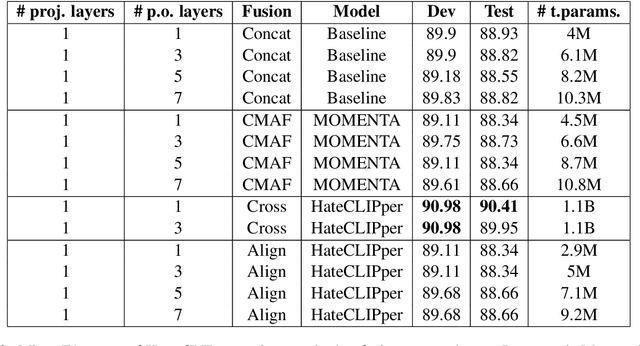
Hateful memes are a growing menace on social media. While the image and its corresponding text in a meme are related, they do not necessarily convey the same meaning when viewed individually. Hence, detecting hateful memes requires careful consideration of both visual and textual information. Multimodal pre-training can be beneficial for this task because it effectively captures the relationship between the image and the text by representing them in a similar feature space. Furthermore, it is essential to model the interactions between the image and text features through intermediate fusion. Most existing methods either employ multimodal pre-training or intermediate fusion, but not both. In this work, we propose the Hate-CLIPper architecture, which explicitly models the cross-modal interactions between the image and text representations obtained using Contrastive Language-Image Pre-training (CLIP) encoders via a feature interaction matrix (FIM). A simple classifier based on the FIM representation is able to achieve state-of-the-art performance on the Hateful Memes Challenge (HMC) dataset with an AUROC of 85.8, which even surpasses the human performance of 82.65. Experiments on other meme datasets such as Propaganda Memes and TamilMemes also demonstrate the generalizability of the proposed approach. Finally, we analyze the interpretability of the FIM representation and show that cross-modal interactions can indeed facilitate the learning of meaningful concepts. The code for this work is available at https://github.com/gokulkarthik/hateclipper.
An Empirical Study Of Self-supervised Learning Approaches For Object Detection With Transformers
May 11, 2022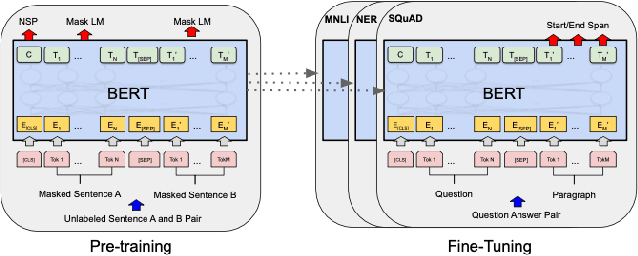
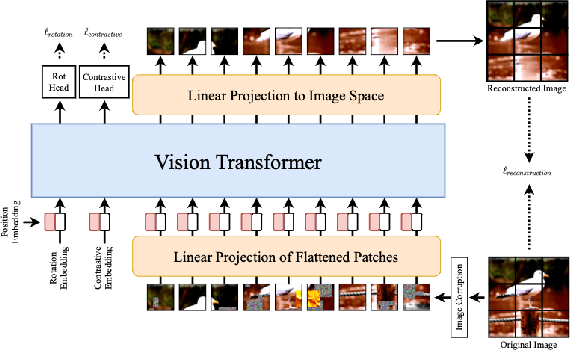

Self-supervised learning (SSL) methods such as masked language modeling have shown massive performance gains by pretraining transformer models for a variety of natural language processing tasks. The follow-up research adapted similar methods like masked image modeling in vision transformer and demonstrated improvements in the image classification task. Such simple self-supervised methods are not exhaustively studied for object detection transformers (DETR, Deformable DETR) as their transformer encoder modules take input in the convolutional neural network (CNN) extracted feature space rather than the image space as in general vision transformers. However, the CNN feature maps still maintain the spatial relationship and we utilize this property to design self-supervised learning approaches to train the encoder of object detection transformers in pretraining and multi-task learning settings. We explore common self-supervised methods based on image reconstruction, masked image modeling and jigsaw. Preliminary experiments in the iSAID dataset demonstrate faster convergence of DETR in the initial epochs in both pretraining and multi-task learning settings; nonetheless, similar improvement is not observed in the case of multi-task learning with Deformable DETR. The code for our experiments with DETR and Deformable DETR are available at https://github.com/gokulkarthik/detr and https://github.com/gokulkarthik/Deformable-DETR respectively.
MuCoT: Multilingual Contrastive Training for Question-Answering in Low-resource Languages
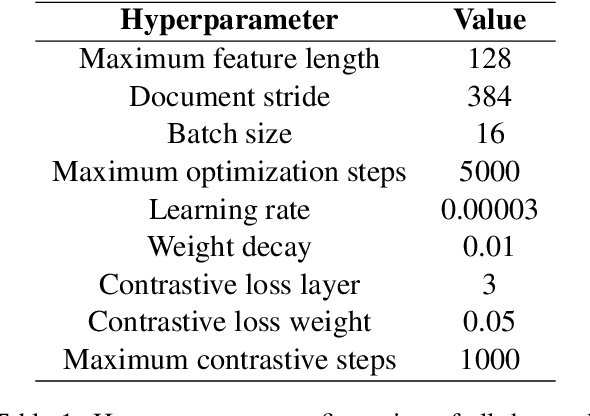
Apr 12, 2022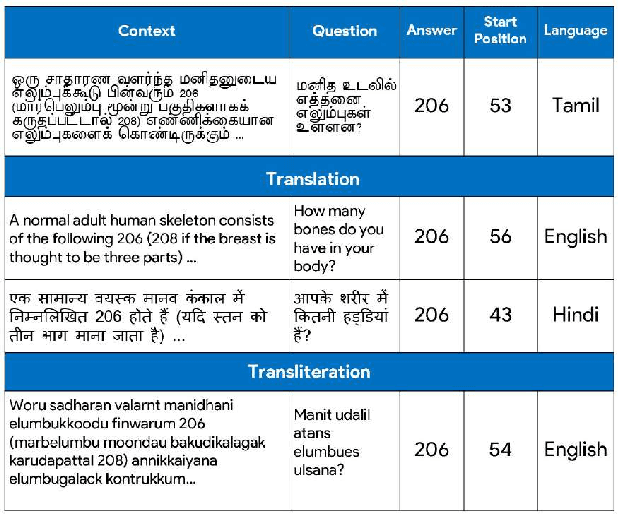
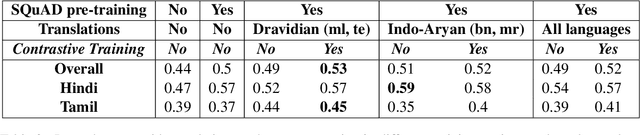
Accuracy of English-language Question Answering (QA) systems has improved significantly in recent years with the advent of Transformer-based models (e.g., BERT). These models are pre-trained in a self-supervised fashion with a large English text corpus and further fine-tuned with a massive English QA dataset (e.g., SQuAD). However, QA datasets on such a scale are not available for most of the other languages. Multi-lingual BERT-based models (mBERT) are often used to transfer knowledge from high-resource languages to low-resource languages. Since these models are pre-trained with huge text corpora containing multiple languages, they typically learn language-agnostic embeddings for tokens from different languages. However, directly training an mBERT-based QA system for low-resource languages is challenging due to the paucity of training data. In this work, we augment the QA samples of the target language using translation and transliteration into other languages and use the augmented data to fine-tune an mBERT-based QA model, which is already pre-trained in English. Experiments on the Google ChAII dataset show that fine-tuning the mBERT model with translations from the same language family boosts the question-answering performance, whereas the performance degrades in the case of cross-language families. We further show that introducing a contrastive loss between the translated question-context feature pairs during the fine-tuning process, prevents such degradation with cross-lingual family translations and leads to marginal improvement. The code for this work is available at https://github.com/gokulkarthik/mucot.