 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Open-World Object Detection
Feb 25, 2024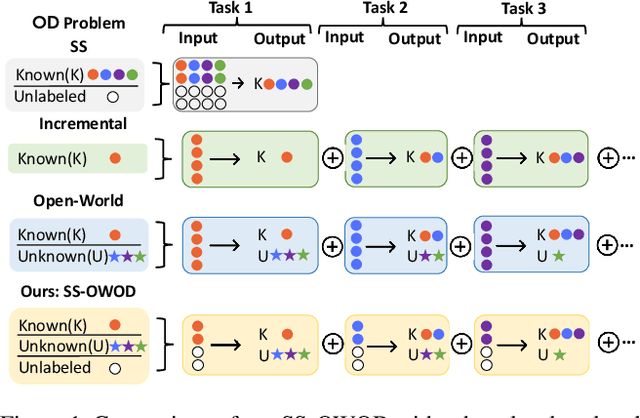
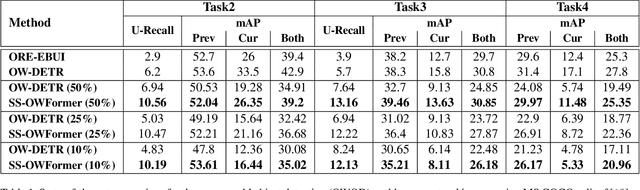
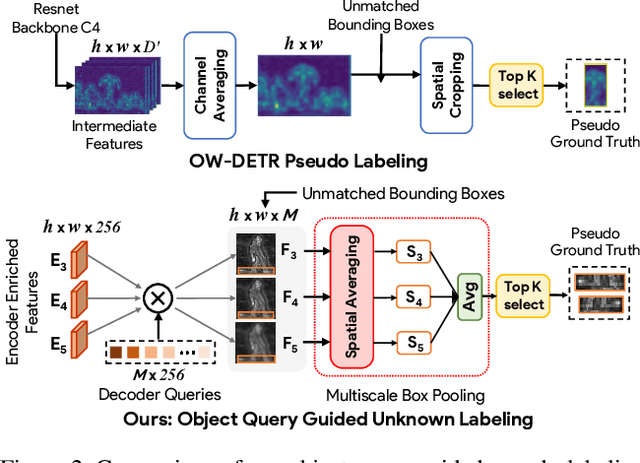
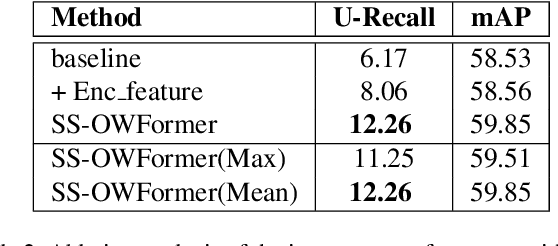
Conventional open-world object detection (OWOD) problem setting first distinguishes known and unknown classes and then later incrementally learns the unknown objects when introduced with labels in the subsequent tasks. However, the current OWOD formulation heavily relies on the external human oracle for knowledge input during the incremental learning stages. Such reliance on run-time makes this formulation less realistic in a real-world deployment. To address this, we introduce a more realistic formulation, named semi-supervised open-world detection (SS-OWOD), that reduces the annotation cost by casting the incremental learning stages of OWOD in a semi-supervised manner. We demonstrate that the performance of the state-of-the-art OWOD detector dramatically deteriorates in the proposed SS-OWOD setting. Therefore, we introduce a novel SS-OWOD detector, named SS-OWFormer, that utilizes a feature-alignment scheme to better align the object query representations between the original and augmented images to leverage the large unlabeled and few labeled data. We further introduce a pseudo-labeling scheme for unknown detection that exploits the inherent capability of decoder object queries to capture object-specific information. We demonstrate the effectiveness of our SS-OWOD problem setting and approach for remote sensing object detection, proposing carefully curated splits and baseline performance evaluations. Our experiments on 4 datasets including MS COCO, PASCAL, Objects365 and DOTA demonstrate the effectiveness of our approach. Our source code, models and splits are available here - https://github.com/sahalshajim/SS-OWFormer
An Empirical Study Of Self-supervised Learning Approaches For Object Detection With Transformers
May 11, 2022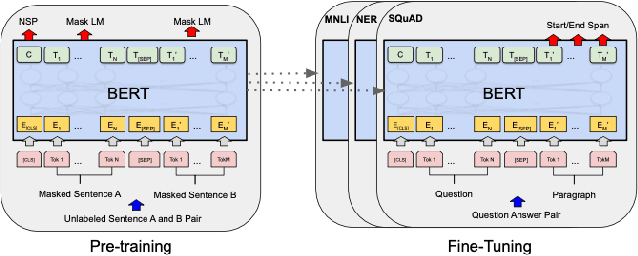
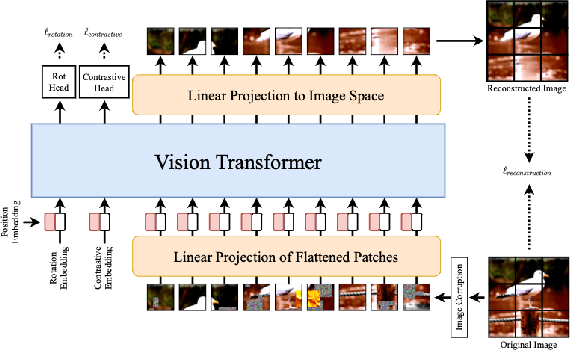

Self-supervised learning (SSL) methods such as masked language modeling have shown massive performance gains by pretraining transformer models for a variety of natural language processing tasks. The follow-up research adapted similar methods like masked image modeling in vision transformer and demonstrated improvements in the image classification task. Such simple self-supervised methods are not exhaustively studied for object detection transformers (DETR, Deformable DETR) as their transformer encoder modules take input in the convolutional neural network (CNN) extracted feature space rather than the image space as in general vision transformers. However, the CNN feature maps still maintain the spatial relationship and we utilize this property to design self-supervised learning approaches to train the encoder of object detection transformers in pretraining and multi-task learning settings. We explore common self-supervised methods based on image reconstruction, masked image modeling and jigsaw. Preliminary experiments in the iSAID dataset demonstrate faster convergence of DETR in the initial epochs in both pretraining and multi-task learning settings; nonetheless, similar improvement is not observed in the case of multi-task learning with Deformable DETR. The code for our experiments with DETR and Deformable DETR are available at https://github.com/gokulkarthik/detr and https://github.com/gokulkarthik/Deformable-DETR respectively.
MuCoT: Multilingual Contrastive Training for Question-Answering in Low-resource Languages
Apr 12, 2022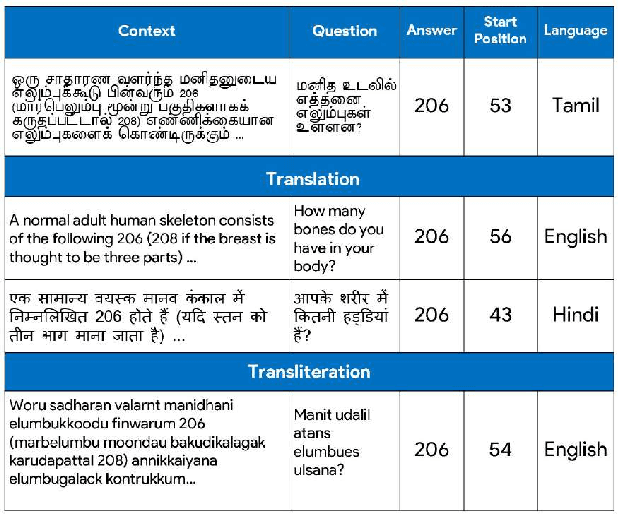
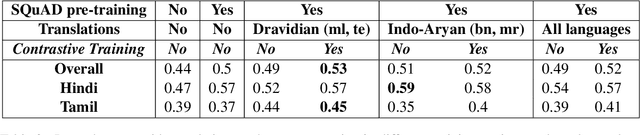
Accuracy of English-language Question Answering (QA) systems has improved significantly in recent years with the advent of Transformer-based models (e.g., BERT). These models are pre-trained in a self-supervised fashion with a large English text corpus and further fine-tuned with a massive English QA dataset (e.g., SQuAD). However, QA datasets on such a scale are not available for most of the other languages. Multi-lingual BERT-based models (mBERT) are often used to transfer knowledge from high-resource languages to low-resource languages. Since these models are pre-trained with huge text corpora containing multiple languages, they typically learn language-agnostic embeddings for tokens from different languages. However, directly training an mBERT-based QA system for low-resource languages is challenging due to the paucity of training data. In this work, we augment the QA samples of the target language using translation and transliteration into other languages and use the augmented data to fine-tune an mBERT-based QA model, which is already pre-trained in English. Experiments on the Google ChAII dataset show that fine-tuning the mBERT model with translations from the same language family boosts the question-answering performance, whereas the performance degrades in the case of cross-language families. We further show that introducing a contrastive loss between the translated question-context feature pairs during the fine-tuning process, prevents such degradation with cross-lingual family translations and leads to marginal improvement. The code for this work is available at https://github.com/gokulkarthik/mucot.