 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Image Visual Question Answering
Dec 27, 2021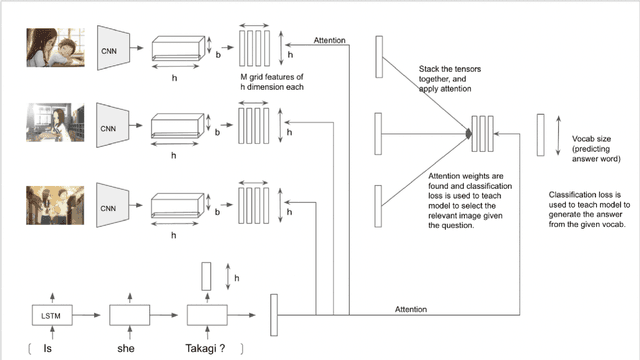


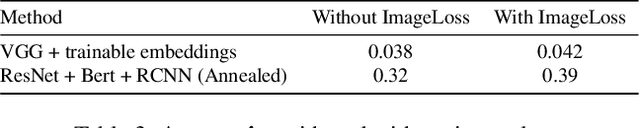
While a lot of work has been done on developing models to tackle the problem of Visual Question Answering, the ability of these models to relate the question to the image features still remain less explored. We present an empirical study of different feature extraction methods with different loss functions. We propose New dataset for the task of Visual Question Answering with multiple image inputs having only one ground truth, and benchmark our results on them. Our final model utilising Resnet + RCNN image features and Bert embeddings, inspired from stacked attention network gives 39% word accuracy and 99% image accuracy on CLEVER+TinyImagenet dataset.
Exploration of Visual Features and their weighted-additive fusion for Video Captioning
Jan 14, 2021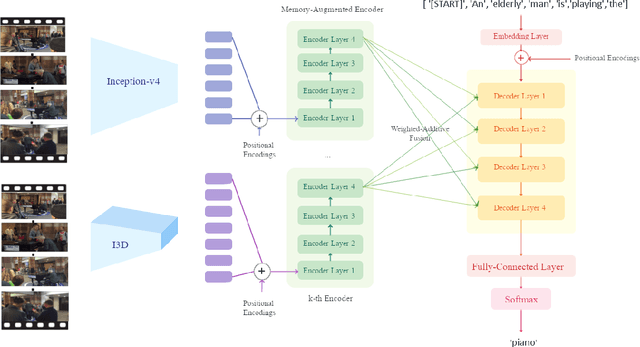
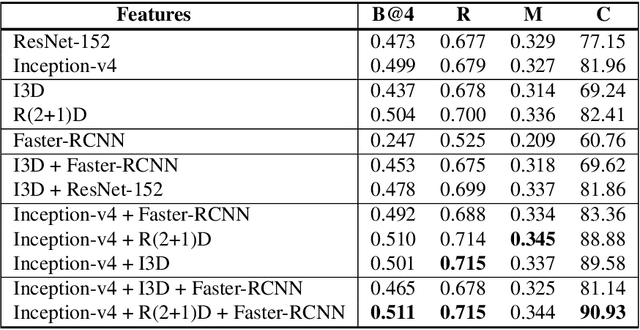
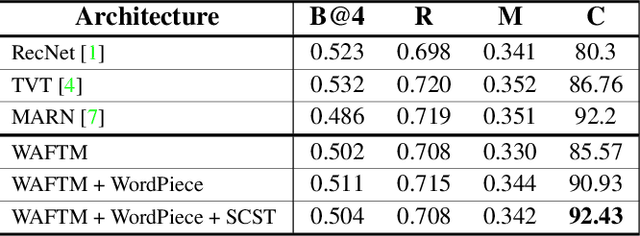

Video captioning is a popular task that challenges models to describe events in videos using natural language. In this work, we investigate the ability of various visual feature representations derived from state-of-the-art convolutional neural networks to capture high-level semantic context. We introduce the Weighted Additive Fusion Transformer with Memory Augmented Encoders (WAFTM), a captioning model that incorporates memory in a transformer encoder and uses a novel method, to fuse features, that ensures due importance is given to more significant representations. We illustrate a gain in performance realized by applying Word-Piece Tokenization and a popular REINFORCE algorithm. Finally, we benchmark our model on two datasets and obtain a CIDEr of 92.4 on MSVD and a METEOR of 0.091 on the ActivityNet Captions Dataset.