 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration of Visual Features and their weighted-additive fusion for Video Captioning
Jan 14, 2021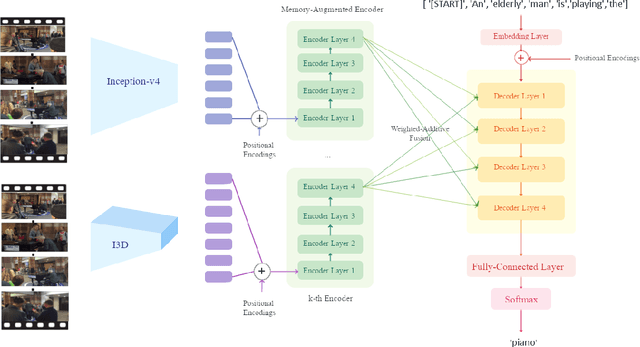
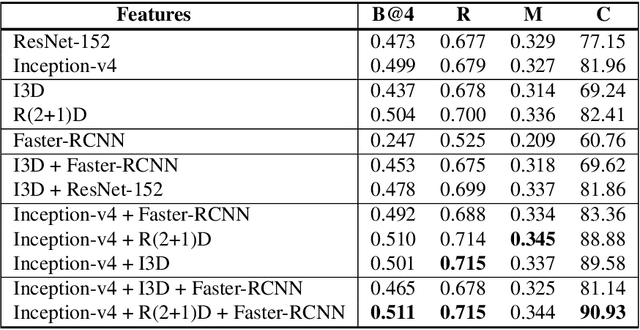
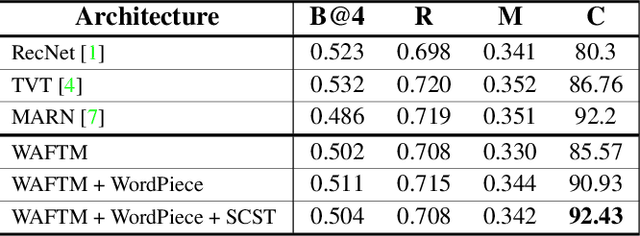

Video captioning is a popular task that challenges models to describe events in videos using natural language. In this work, we investigate the ability of various visual feature representations derived from state-of-the-art convolutional neural networks to capture high-level semantic context. We introduce the Weighted Additive Fusion Transformer with Memory Augmented Encoders (WAFTM), a captioning model that incorporates memory in a transformer encoder and uses a novel method, to fuse features, that ensures due importance is given to more significant representations. We illustrate a gain in performance realized by applying Word-Piece Tokenization and a popular REINFORCE algorithm. Finally, we benchmark our model on two datasets and obtain a CIDEr of 92.4 on MSVD and a METEOR of 0.091 on the ActivityNet Captions Dataset.