Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATE: Gated Additive Tree Ensemble for Tabular Classification and Regression
Paper and Code
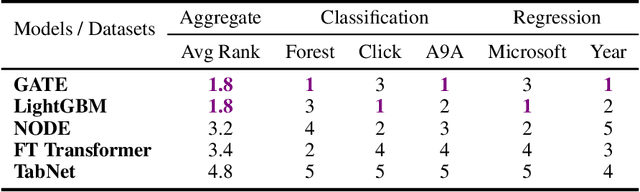
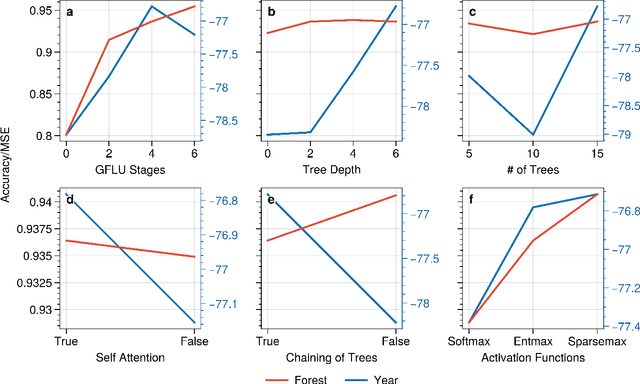

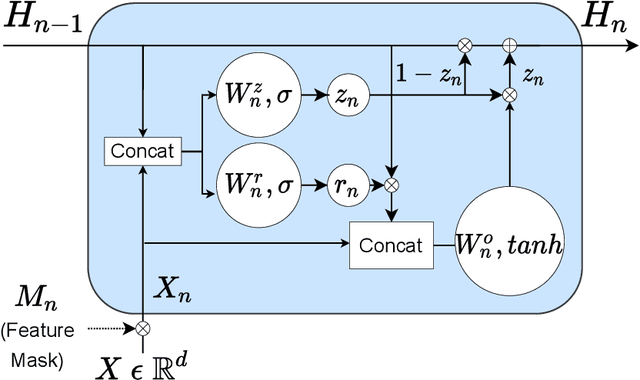
We propose a novel high-performance, parameter and computationally efficient deep learning architecture for tabular data, Gated Additive Tree Ensemble(GATE). GATE uses a gating mechanism, inspired from GRU, as a feature representation learning unit with an in-built feature selection mechanism. We combine it with an ensemble of differentiable, non-linear decision trees, re-weighted with simple self-attention to predict our desired output. We demonstrate that GATE is a competitive alternative to SOTA approaches like GBDTs, NODE, FT Transformers, etc. by experiments on several public datasets (both classification and regression). The code will be uploaded as soon as the paper comes out of review.
View paper on