 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAskYourDB: An end-to-end system for querying and visualizing relational databases using natural language
Oct 16, 2022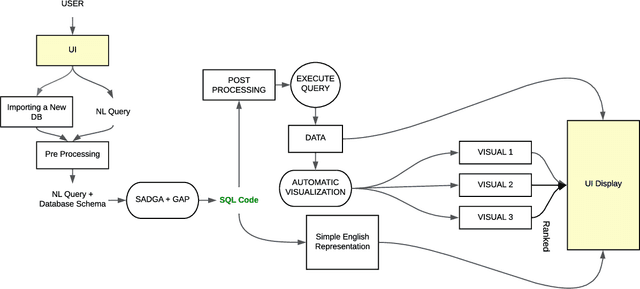
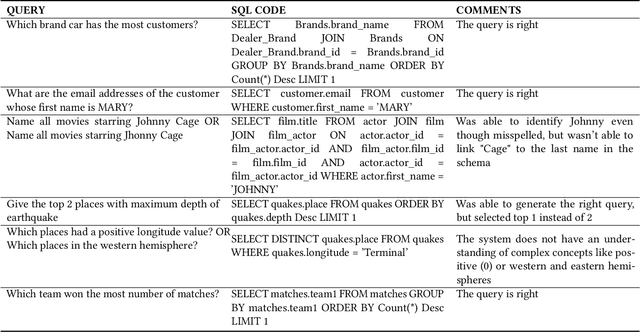
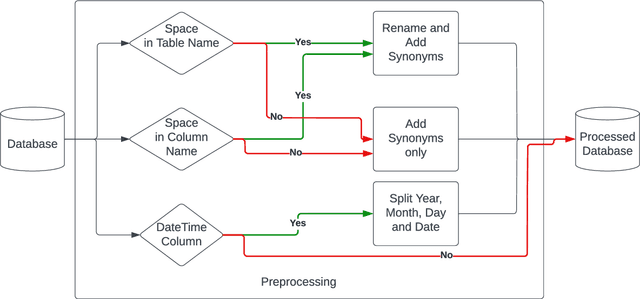

Querying databases for the right information is a time consuming and error-prone task and often requires experienced professionals for the job. Furthermore, the user needs to have some prior knowledge about the database. There have been various efforts to develop an intelligence which can help business users to query databases directly. However, there has been some successes, but very little in terms of testing and deploying those for real world users. In this paper, we propose a semantic parsing approach to address the challenge of converting complex natural language into SQL and institute a product out of it. For this purpose, we modified state-of-the-art models, by various pre and post processing steps which make the significant part when a model is deployed in production. To make the product serviceable to businesses we added an automatic visualization framework over the queried results.
Ensemble Creation via Anchored Regularization for Unsupervised Aspect Extraction
Oct 13, 2022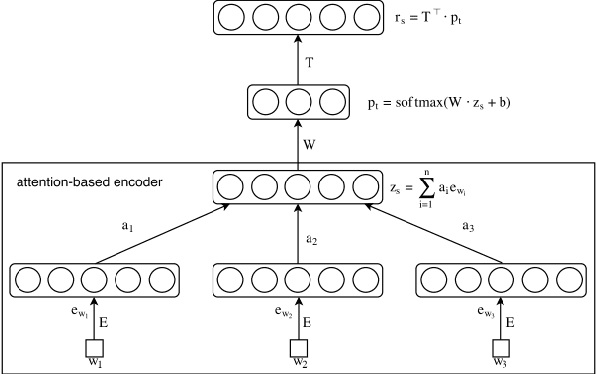
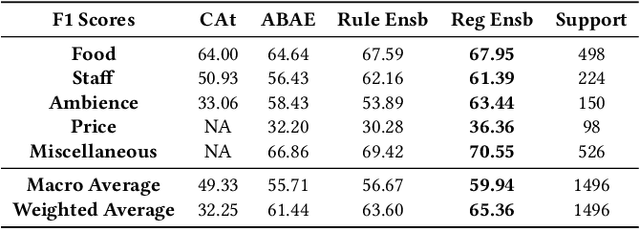
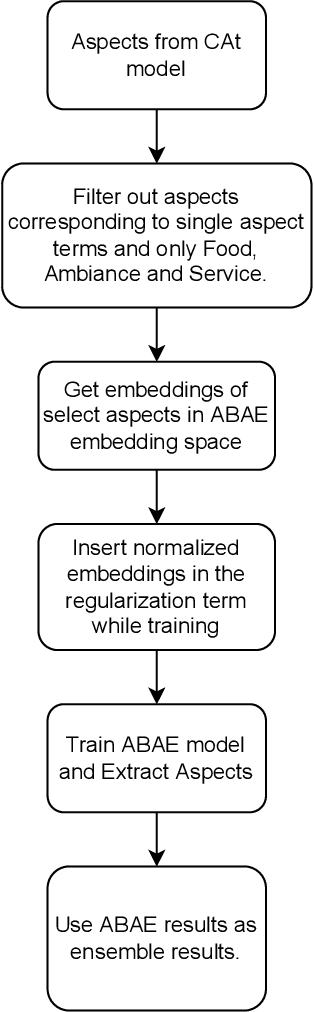
Aspect Based Sentiment Analysis is the most granular form of sentiment analysis that can be performed on the documents / sentences. Besides delivering the most insights at a finer grain, it also poses equally daunting challenges. One of them being the shortage of labelled data. To bring in value right out of the box for the text data being generated at a very fast pace in today's world, unsupervised aspect-based sentiment analysis allows us to generate insights without investing time or money in generating labels. From topic modelling approaches to recent deep learning-based aspect extraction models, this domain has seen a lot of development. One of the models that we improve upon is ABAE that reconstructs the sentences as a linear combination of aspect terms present in it, In this research we explore how we can use information from another unsupervised model to regularize ABAE, leading to better performance. We contrast it with baseline rule based ensemble and show that the ensemble methods work better than the individual models and the regularization based ensemble performs better than the rule-based one.
LAMA-Net: Unsupervised Domain Adaptation via Latent Alignment and Manifold Learning for RUL Prediction
Aug 17, 2022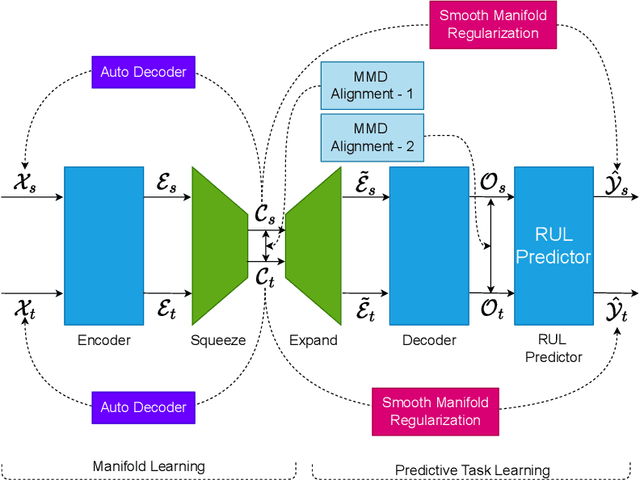
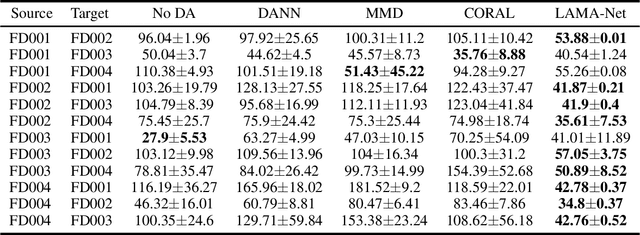
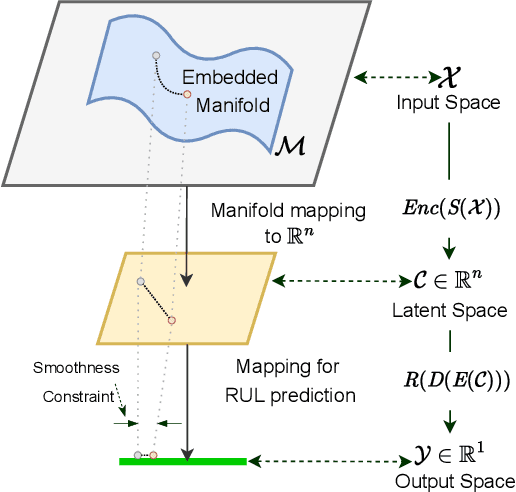
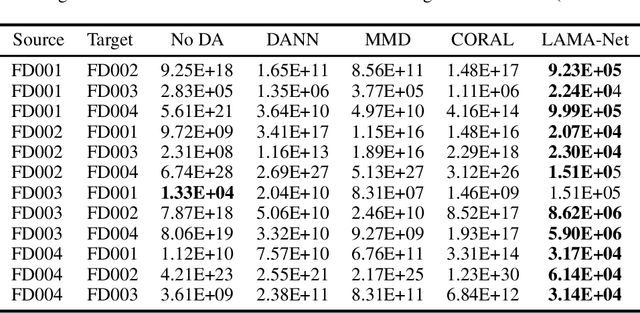
Prognostics and Health Management (PHM) is an emerging field which has received much attention from the manufacturing industry because of the benefits and efficiencies it brings to the table. And Remaining Useful Life (RUL) prediction is at the heart of any PHM system. Most recent data-driven research demand substantial volumes of labelled training data before a performant model can be trained under the supervised learning paradigm. This is where Transfer Learning (TL) and Domain Adaptation (DA) methods step in and make it possible for us to generalize a supervised model to other domains with different data distributions with no labelled data. In this paper, we propose \textit{LAMA-Net}, an encoder-decoder based model (Transformer) with an induced bottleneck, Latent Alignment using Maximum Mean Discrepancy (MMD) and manifold learning is proposed to tackle the problem of Unsupervised Homogeneous Domain Adaptation for RUL prediction. \textit{LAMA-Net} is validated using the C-MAPSS Turbofan Engine dataset by NASA and compared against other state-of-the-art techniques for DA. The results suggest that the proposed method offers a promising approach to perform domain adaptation in RUL prediction. Code will be made available once the paper comes out of review.
GATE: Gated Additive Tree Ensemble for Tabular Classification and Regression
Jul 19, 2022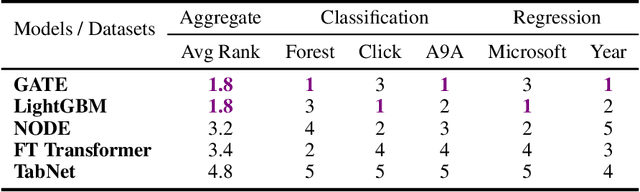
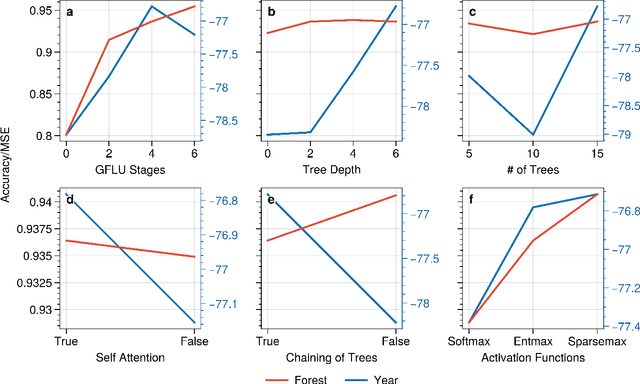

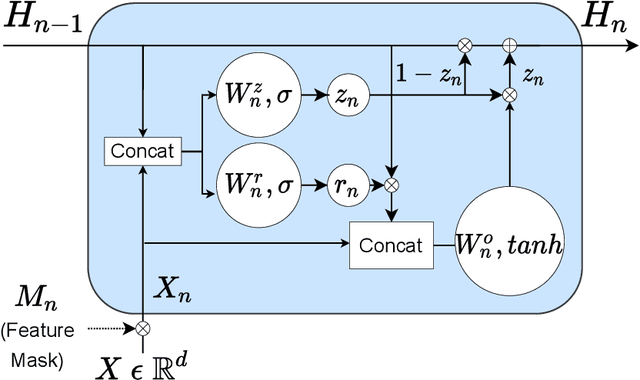
We propose a novel high-performance, parameter and computationally efficient deep learning architecture for tabular data, Gated Additive Tree Ensemble(GATE). GATE uses a gating mechanism, inspired from GRU, as a feature representation learning unit with an in-built feature selection mechanism. We combine it with an ensemble of differentiable, non-linear decision trees, re-weighted with simple self-attention to predict our desired output. We demonstrate that GATE is a competitive alternative to SOTA approaches like GBDTs, NODE, FT Transformers, etc. by experiments on several public datasets (both classification and regression). The code will be uploaded as soon as the paper comes out of review.
PyTorch Tabular: A Framework for Deep Learning with Tabular Data
Apr 28, 2021
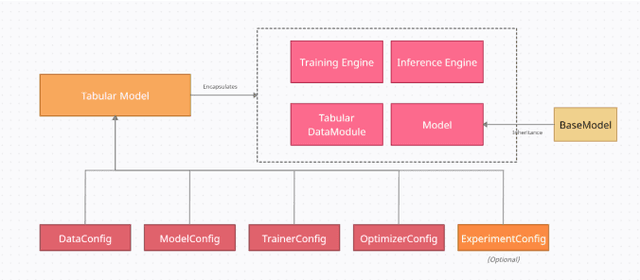
In spite of showing unreasonable effectiveness in modalities like Text and Image, Deep Learning has always lagged Gradient Boosting in tabular data - both in popularity and performance. But recently there have been newer models created specifically for tabular data, which is pushing the performance bar. But popularity is still a challenge because there is no easy, ready-to-use library like Sci-Kit Learn for deep learning. PyTorch Tabular is a new deep learning library which makes working with Deep Learning and tabular data easy and fast. It is a library built on top of PyTorch and PyTorch Lightning and works on pandas dataframes directly. Many SOTA models like NODE and TabNet are already integrated and implemented in the library with a unified API. PyTorch Tabular is designed to be easily extensible for researchers, simple for practitioners, and robust in industrial deployments.