 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Underperform Graph-Based Parsers on Supervised Relation Extraction for Complex Graphs
Apr 09, 2026Relation extraction represents a fundamental component in the process of creating knowledge graphs, among other applications. Large language models (LLMs) have been adopted as a promising tool for relation extraction, both in supervised and in-context learning settings. However, in this work we show that their performance still lags behind much smaller architectures when the linguistic graph underlying a text has great complexity. To demonstrate this, we evaluate four LLMs against a graph-based parser on six relation extraction datasets with sentence graphs of varying sizes and complexities. Our results show that the graph-based parser increasingly outperforms the LLMs, as the number of relations in the input documents increases. This makes the much lighter graph-based parser a superior choice in the presence of complex linguistic graphs.
Dependency Parsing is More Parameter-Efficient with Normalization
May 26, 2025Dependency parsing is the task of inferring natural language structure, often approached by modeling word interactions via attention through biaffine scoring. This mechanism works like self-attention in Transformers, where scores are calculated for every pair of words in a sentence. However, unlike Transformer attention, biaffine scoring does not use normalization prior to taking the softmax of the scores. In this paper, we provide theoretical evidence and empirical results revealing that a lack of normalization necessarily results in overparameterized parser models, where the extra parameters compensate for the sharp softmax outputs produced by high variance inputs to the biaffine scoring function. We argue that biaffine scoring can be made substantially more efficient by performing score normalization. We conduct experiments on six datasets for semantic and syntactic dependency parsing using a one-hop parser. We train N-layer stacked BiLSTMs and evaluate the parser's performance with and without normalizing biaffine scores. Normalizing allows us to beat the state of the art on two datasets, with fewer samples and trainable parameters. Code: https://anonymous.4open.science/r/EfficientSDP-70C1
Improving Consistency in Large Language Models through Chain of Guidance
Feb 21, 2025Consistency is a fundamental dimension of trustworthiness in Large Language Models (LLMs). For humans to be able to trust LLM-based applications, their outputs should be consistent when prompted with inputs that carry the same meaning or intent. Despite this need, there is no known mechanism to control and guide LLMs to be more consistent at inference time. In this paper, we introduce a novel alignment strategy to maximize semantic consistency in LLM outputs. Our proposal is based on Chain of Guidance (CoG), a multistep prompting technique that generates highly consistent outputs from LLMs. For closed-book question-answering (Q&A) tasks, when compared to direct prompting, the outputs generated using CoG show improved consistency. While other approaches like template-based responses and majority voting may offer alternative paths to consistency, our work focuses on exploring the potential of guided prompting. We use synthetic data sets comprised of consistent input-output pairs to fine-tune LLMs to produce consistent and correct outputs. Our fine-tuned models are more than twice as consistent compared to base models and show strong generalization capabilities by producing consistent outputs over datasets not used in the fine-tuning process.
Resolving Lexical Bias in Edit Scoping with Projector Editor Networks
Aug 19, 2024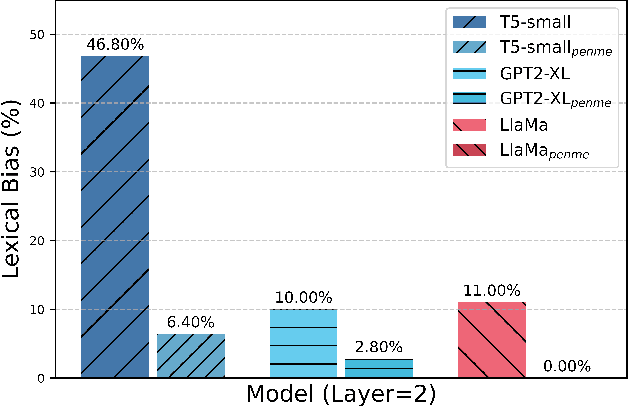
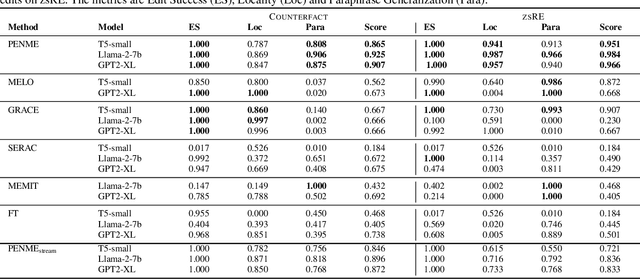
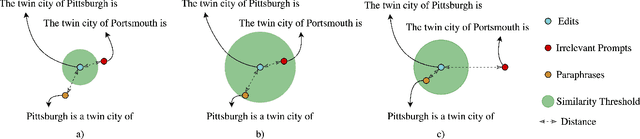

Weight-preserving model editing techniques heavily rely on the scoping mechanism that decides when to apply an edit to the base model. These scoping mechanisms utilize distance functions in the representation space to ascertain the scope of the edit. In this work, we show that distance-based scoping functions grapple with lexical biases leading to issues such as misfires with irrelevant prompts that share similar lexical characteristics. To address this problem, we introduce, Projector Editor Networks for Model Editing (PENME),is a model editing approach that employs a compact adapter with a projection network trained via a contrastive learning objective. We demonstrate the efficacy of PENME in achieving superior results while being compute efficient and flexible to adapt across model architectures.
Representation noising effectively prevents harmful fine-tuning on LLMs
May 23, 2024



Releasing open-source large language models (LLMs) presents a dual-use risk since bad actors can easily fine-tune these models for harmful purposes. Even without the open release of weights, weight stealing and fine-tuning APIs make closed models vulnerable to harmful fine-tuning attacks (HFAs). While safety measures like preventing jailbreaks and improving safety guardrails are important, such measures can easily be reversed through fine-tuning. In this work, we propose Representation Noising (RepNoise), a defence mechanism that is effective even when attackers have access to the weights and the defender no longer has any control. RepNoise works by removing information about harmful representations such that it is difficult to recover them during fine-tuning. Importantly, our defence is also able to generalize across different subsets of harm that have not been seen during the defence process. Our method does not degrade the general capability of LLMs and retains the ability to train the model on harmless tasks. We provide empirical evidence that the effectiveness of our defence lies in its "depth": the degree to which information about harmful representations is removed across all layers of the LLM.
Immunization against harmful fine-tuning attacks
Feb 26, 2024Approaches to aligning large language models (LLMs) with human values has focused on correcting misalignment that emerges from pretraining. However, this focus overlooks another source of misalignment: bad actors might purposely fine-tune LLMs to achieve harmful goals. In this paper, we present an emerging threat model that has arisen from alignment circumvention and fine-tuning attacks. However, lacking in previous works is a clear presentation of the conditions for effective defence. We propose a set of conditions for effective defence against harmful fine-tuning in LLMs called "Immunization conditions," which help us understand how we would construct and measure future defences. Using this formal framework for defence, we offer a synthesis of different research directions that might be persued to prevent harmful fine-tuning attacks and provide a demonstration of how to use these conditions experimentally showing early results of using an adversarial loss to immunize LLama2-7b-chat.
Long-form evaluation of model editing
Feb 14, 2024
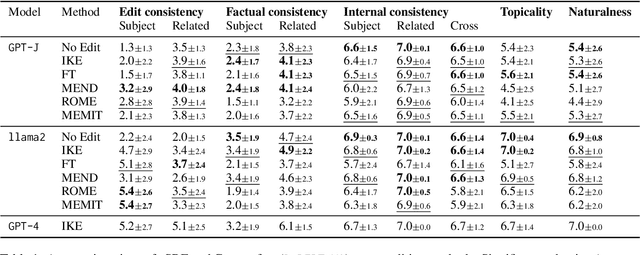

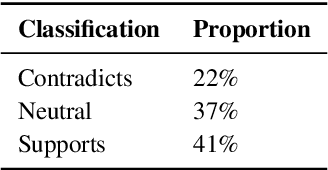
Evaluations of model editing currently only use the `next few token' completions after a prompt. As a result, the impact of these methods on longer natural language generation is largely unknown. We introduce long-form evaluation of model editing (\textbf{\textit{LEME}}) a novel evaluation protocol that measures the efficacy and impact of model editing in long-form generative settings. Our protocol consists of a machine-rated survey and a classifier which correlates well with human ratings. Importantly, we find that our protocol has very little relationship with previous short-form metrics (despite being designed to extend efficacy, generalization, locality, and portability into a long-form setting), indicating that our method introduces a novel set of dimensions for understanding model editing methods. Using this protocol, we benchmark a number of model editing techniques and present several findings including that, while some methods (ROME and MEMIT) perform well in making consistent edits within a limited scope, they suffer much more from factual drift than other methods. Finally, we present a qualitative analysis that illustrates common failure modes in long-form generative settings including internal consistency, lexical cohesion, and locality issues.
Self-Consistency of Large Language Models under Ambiguity
Oct 20, 2023

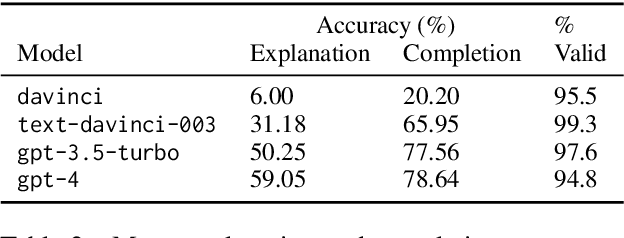

Large language models (LLMs) that do not give consistent answers across contexts are problematic when used for tasks with expectations of consistency, e.g., question-answering, explanations, etc. Our work presents an evaluation benchmark for self-consistency in cases of under-specification where two or more answers can be correct. We conduct a series of behavioral experiments on the OpenAI model suite using an ambiguous integer sequence completion task. We find that average consistency ranges from 67\% to 82\%, far higher than would be predicted if a model's consistency was random, and increases as model capability improves. Furthermore, we show that models tend to maintain self-consistency across a series of robustness checks, including prompting speaker changes and sequence length changes. These results suggest that self-consistency arises as an emergent capability without specifically training for it. Despite this, we find that models are uncalibrated when judging their own consistency, with models displaying both over- and under-confidence. We also propose a nonparametric test for determining from token output distribution whether a model assigns non-trivial probability to alternative answers. Using this test, we find that despite increases in self-consistency, models usually place significant weight on alternative, inconsistent answers. This distribution of probability mass provides evidence that even highly self-consistent models internally compute multiple possible responses.
Semantic Consistency for Assuring Reliability of Large Language Models
Aug 17, 2023Large Language Models (LLMs) exhibit remarkable fluency and competence across various natural language tasks. However, recent research has highlighted their sensitivity to variations in input prompts. To deploy LLMs in a safe and reliable manner, it is crucial for their outputs to be consistent when prompted with expressions that carry the same meaning or intent. While some existing work has explored how state-of-the-art LLMs address this issue, their evaluations have been confined to assessing lexical equality of single- or multi-word answers, overlooking the consistency of generative text sequences. For a more comprehensive understanding of the consistency of LLMs in open-ended text generation scenarios, we introduce a general measure of semantic consistency, and formulate multiple versions of this metric to evaluate the performance of various LLMs. Our proposal demonstrates significantly higher consistency and stronger correlation with human evaluations of output consistency than traditional metrics based on lexical consistency. Finally, we propose a novel prompting strategy, called Ask-to-Choose (A2C), to enhance semantic consistency. When evaluated for closed-book question answering based on answer variations from the TruthfulQA benchmark, A2C increases accuracy metrics for pretrained and finetuned LLMs by up to 47%, and semantic consistency metrics for instruction-tuned models by up to 7-fold.
Background Knowledge Grounding for Readable, Relevant, and Factual Biomedical Lay Summaries
May 03, 2023Communication of scientific findings to the public is important for keeping non-experts informed of developments such as life-saving medical treatments. However, generating readable lay summaries from scientific documents is challenging, and currently, these summaries suffer from critical factual errors. One popular intervention for improving factuality is using additional external knowledge to provide factual grounding. However, it is unclear how these grounding sources should be retrieved, selected, or integrated, and how supplementary grounding documents might affect the readability or relevance of the generated summaries. We develop a simple method for selecting grounding sources and integrating them with source documents. We then use the BioLaySum summarization dataset to evaluate the effects of different grounding sources on summary quality. We found that grounding source documents improves the relevance and readability of lay summaries but does not improve factuality of lay summaries. This continues to be true in zero-shot summarization settings where we hypothesized that grounding might be even more important for factual lay summaries.