 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-form evaluation of model editing
Feb 14, 2024
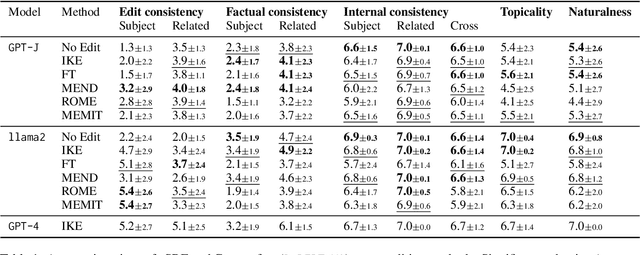

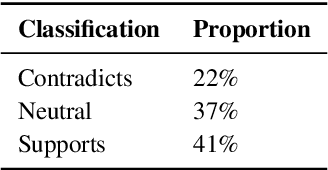
Evaluations of model editing currently only use the `next few token' completions after a prompt. As a result, the impact of these methods on longer natural language generation is largely unknown. We introduce long-form evaluation of model editing (\textbf{\textit{LEME}}) a novel evaluation protocol that measures the efficacy and impact of model editing in long-form generative settings. Our protocol consists of a machine-rated survey and a classifier which correlates well with human ratings. Importantly, we find that our protocol has very little relationship with previous short-form metrics (despite being designed to extend efficacy, generalization, locality, and portability into a long-form setting), indicating that our method introduces a novel set of dimensions for understanding model editing methods. Using this protocol, we benchmark a number of model editing techniques and present several findings including that, while some methods (ROME and MEMIT) perform well in making consistent edits within a limited scope, they suffer much more from factual drift than other methods. Finally, we present a qualitative analysis that illustrates common failure modes in long-form generative settings including internal consistency, lexical cohesion, and locality issues.