 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation noising effectively prevents harmful fine-tuning on LLMs
May 23, 2024



Releasing open-source large language models (LLMs) presents a dual-use risk since bad actors can easily fine-tune these models for harmful purposes. Even without the open release of weights, weight stealing and fine-tuning APIs make closed models vulnerable to harmful fine-tuning attacks (HFAs). While safety measures like preventing jailbreaks and improving safety guardrails are important, such measures can easily be reversed through fine-tuning. In this work, we propose Representation Noising (RepNoise), a defence mechanism that is effective even when attackers have access to the weights and the defender no longer has any control. RepNoise works by removing information about harmful representations such that it is difficult to recover them during fine-tuning. Importantly, our defence is also able to generalize across different subsets of harm that have not been seen during the defence process. Our method does not degrade the general capability of LLMs and retains the ability to train the model on harmless tasks. We provide empirical evidence that the effectiveness of our defence lies in its "depth": the degree to which information about harmful representations is removed across all layers of the LLM.
Long-form evaluation of model editing
Feb 14, 2024
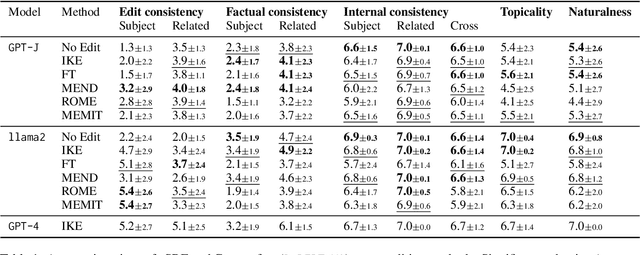

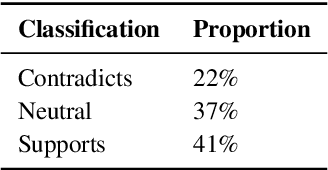
Evaluations of model editing currently only use the `next few token' completions after a prompt. As a result, the impact of these methods on longer natural language generation is largely unknown. We introduce long-form evaluation of model editing (\textbf{\textit{LEME}}) a novel evaluation protocol that measures the efficacy and impact of model editing in long-form generative settings. Our protocol consists of a machine-rated survey and a classifier which correlates well with human ratings. Importantly, we find that our protocol has very little relationship with previous short-form metrics (despite being designed to extend efficacy, generalization, locality, and portability into a long-form setting), indicating that our method introduces a novel set of dimensions for understanding model editing methods. Using this protocol, we benchmark a number of model editing techniques and present several findings including that, while some methods (ROME and MEMIT) perform well in making consistent edits within a limited scope, they suffer much more from factual drift than other methods. Finally, we present a qualitative analysis that illustrates common failure modes in long-form generative settings including internal consistency, lexical cohesion, and locality issues.